
Unlocking Document Insights: How AI Answers Your Questions
Seamlessly Interact with Your Information Through AI-Powered Question Answering
- Effortless Information Retrieval: AI tools allow you to quickly extract specific answers from lengthy documents, saving significant time compared to manual reading.
- Broad Document Compatibility: These intelligent systems support various file formats, including PDFs, DOCX, TXT, and even scanned images, ensuring versatility in your data input.
- Contextual Understanding: Unlike simple keyword searches, AI question-answering goes beyond highlighting words, providing detailed, contextually relevant responses based on the document's content.
In today's information-rich environment, efficiently extracting relevant data from vast amounts of text can be a significant challenge. Fortunately, artificial intelligence (AI) has revolutionized how we interact with documents, offering powerful tools that can read, understand, and answer questions based on the content you provide. This capability, known as Document Question Answering (Document Q&A), transforms passive documents into interactive knowledge bases, allowing you to gain insights and find specific information with unprecedented speed and accuracy.
The Core Mechanism: How AI Understands Your Documents
From Raw Text to Intelligent Answers
At its heart, an AI system designed to answer questions from documents employs sophisticated natural language processing (NLP) and machine learning techniques. The process typically involves several key stages:
Document Ingestion and Pre-processing
The first step is to "ingest" the document. This involves uploading your file, which can be in various formats such as PDF, DOCX, TXT, HTML, EPUB, RTF, and even scanned images. For scanned documents, Optical Character Recognition (OCR) technology is crucial, converting the image-based text into machine-readable format. Once ingested, the document undergoes pre-processing, where it's parsed, cleaned, and often broken down into smaller, manageable chunks or passages. This prepares the text for deeper analysis.
Many AI tools, like docAnalyzer.ai, Adobe Acrobat AI Assistant, and AskYourPDF, boast broad compatibility with these diverse file types, making them highly versatile for users with varied document libraries.
Here is an image demonstrating AI-powered document analysis:
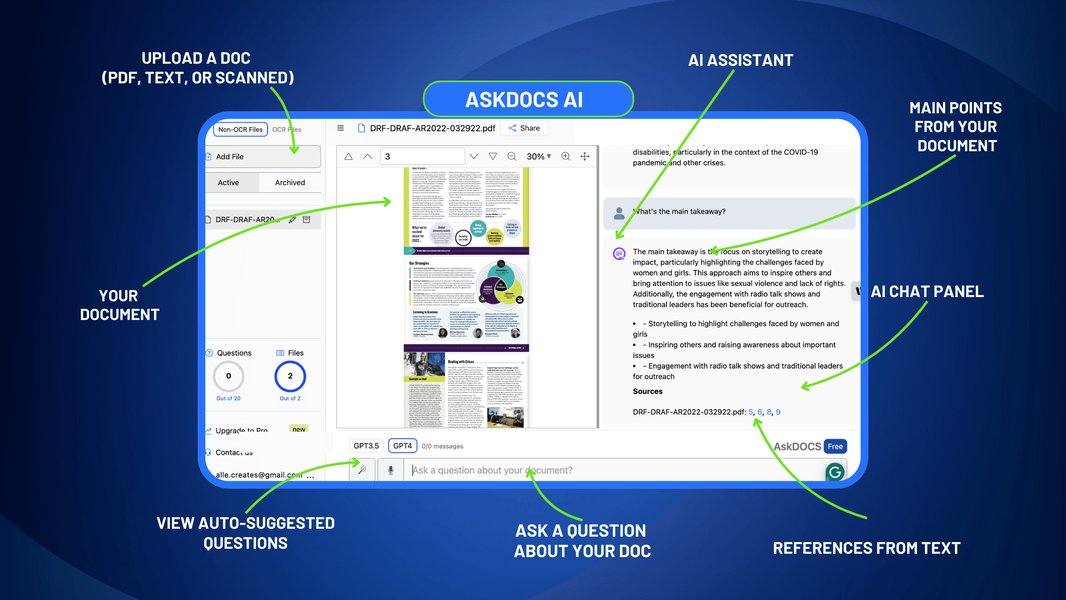
An illustrative representation of AI actively analyzing document content to extract insights.
Text Embedding and Vectorization
After pre-processing, the text (and sometimes layout or visual information) is converted into numerical representations called embeddings. These embeddings are high-dimensional vectors that capture the semantic meaning of the text. Models like Google's textembedding-gecko transform words, sentences, or even entire paragraphs into these vectors. The idea is that semantically similar pieces of text will have "closer" vectors in this multi-dimensional space.
This vectorization is fundamental for the AI to understand the context and relationships between different pieces of information within the document, rather than just matching keywords. It allows the AI to perform semantic search, recognizing synonyms and paraphrases with similar meanings even if the exact words differ.
Question Processing and Retrieval-Augmented Generation (RAG)
When you ask a question, it also gets converted into a vector embedding. The AI then compares this question embedding to the document embeddings to find the most relevant sections of the document. This "document retriever" step is critical for identifying the passages most likely to contain the answer. This is where Retrieval-Augmented Generation (RAG) comes into play. RAG enhances the capabilities of large language models (LLMs) by grounding their responses in relevant information from a knowledge base (your document).
Once relevant sections are identified, a "document reader" component, often an LLM like Google's PaLM2 (specifically the Vertex AI text-bison foundation model) or OpenAI's GPT models, carefully examines these retrieved contexts. The LLM then synthesizes the information to generate a natural language answer to your question, providing precise, context-aware responses and often citing the source within the document.
Practical Applications and Benefits of Document Q&A
Transforming Workflow and Accessibility
The ability of AI to answer questions from documents has far-reaching benefits across various sectors:
Enhanced Productivity and Efficiency
One of the most significant advantages is the drastic reduction in time spent on information retrieval. Instead of manually sifting through hundreds or thousands of pages, users can ask specific questions and receive instant, accurate answers. This is invaluable for:
- Researchers and Students: Quickly extract main points, methodologies, or findings from complex scholarly articles, textbooks, and reports, streamlining literature reviews and analysis. Tools like Jotbot AI and HiPDF are particularly popular in academic settings.
- Professionals (Legal, Technical, Financial): Engineers can rapidly locate specific sections in technical manuals, legal teams can review contracts and extract clauses, and financial analysts can quickly gather data from reports. This reduces downtime and improves operational efficiency.
- IT Support Teams: Expedite troubleshooting by finding information from technical documentation and guides.
Improved Accuracy and Contextual Understanding
Unlike traditional keyword searches, AI-powered tools understand the context of your question and the document's content. This means they can provide detailed, multi-paragraph answers that go beyond mere word highlighting. Many tools, such as Doclime and PDF.ai, are designed to offer contextual chat systems that reference and analyze uploaded documents, often providing citations from the source material to back up their answers.
Accessibility and User Experience
AI PDF readers and document Q&A tools can enhance accessibility for individuals with disabilities by offering features like text-to-speech and simplified explanations, making complex documents more approachable for everyone.
Choosing the Right AI Document Q&A Tool
Key Considerations for Your Workflow
With numerous AI tools available, selecting the most suitable one depends on your specific needs. Here are some factors to consider:
This radar chart illustrates a comparative analysis of key features in various AI document Q&A tools, based on general observations and reported functionalities. Each axis represents a crucial aspect, and the further a point is from the center, the stronger the tool's performance or emphasis in that area. For instance, a higher score on "Ease of Use" indicates a more intuitive interface, while a higher score on "File Format Support" suggests broader compatibility. This chart helps visualize the strengths and focuses of different platforms, guiding users in selecting a tool that aligns with their priorities, whether it's security, advanced analytics, or multi-document processing.
Key Features to Evaluate
When selecting an AI document Q&A tool, consider the following:
| Feature | Description | Benefit to User |
|---|---|---|
| Supported File Formats | PDF, DOCX, TXT, HTML, EPUB, RTF, CSV, scanned images (JPG, PNG) | Ensures compatibility with all your existing documents without prior conversion. |
| Accuracy and Contextual Understanding | Ability to provide precise, context-aware answers, often with source citations. | Reduces misinterpretations, ensures reliable information, and builds trust in AI-generated answers. |
| Multi-Document Processing | Capability to analyze and answer questions across multiple uploaded files simultaneously. | Ideal for cross-referencing information from large datasets or diverse knowledge bases. |
| Summarization Capabilities | Ability to generate concise summaries of lengthy documents or specific sections. | Saves time by providing quick overviews of complex content. |
| Security and Privacy | Measures taken to protect your uploaded data, including encryption and data retention policies. | Ensures confidentiality and compliance, especially for sensitive or proprietary information. |
| Integration and API Access | Availability of APIs for integrating the AI Q&A functionality into existing workflows or applications. | Allows developers to build custom solutions and automate document analysis processes. |
| User Interface (UI) and Ease of Use | Intuitive design and straightforward process for uploading documents and asking questions. | Reduces learning curve, making the tool accessible to a wider range of users. |
Many solutions, such as Docalysis, ChatDOC, and Sharly AI, offer varying combinations of these features, catering to different user needs from individual researchers to enterprise-level document management.
Building Your Own Document Q&A System
A Glimpse into Custom Solutions
For those with specific requirements or a desire for greater control, it's also possible to build a custom document-based question-answering system. This often involves leveraging cloud AI services and open-source libraries.
Leveraging Cloud AI Platforms
Platforms like Google Cloud's Document AI and Azure AI Search provide robust tools for developers. Google Cloud, for example, combines Document AI OCR processors for text extraction, text embedding models (like textembedding-gecko) for vector representation, and LLMs (like PaLM2) for generating answers. This approach allows for the creation of sophisticated "Ask your documents" tools for employees, grounded in internal knowledge bases.
Similarly, Azure AI Search enables the creation of an index of your files and emails, which can then be queried to retrieve relevant results, and can be used in conjunction with Azure OpenAI models for enhanced question answering.
Open-Source and Local AI Options
For those interested in self-hosting or more granular control, open-source frameworks like LangChain, combined with custom LLMs (e.g., using Ollama or llama.cpp), can be used to build document Q&A systems. This involves steps such as:
- Loading and splitting documents into chunks.
- Creating embeddings for these chunks using embedding models.
- Storing these embeddings in a vector database (vector store).
- Performing similarity searches to retrieve relevant chunks based on a user's query.
- Feeding these relevant chunks to an LLM to generate an answer.
These methods allow for highly customized solutions tailored to specific data types or privacy requirements.
The following video provides an excellent overview of building a document-based question answering system:
A tutorial on building a document-based question answering system with AI-driven insights, highlighting the power of semantic search.
This video delves into the technical aspects of setting up such a system, demonstrating how to unlock the potential of semantic search and AI-driven insights to create precise and context-aware AI solutions. It's particularly useful for understanding the underlying architecture and process involved in developing custom document Q&A applications.
FAQs about AI Document Question Answering
Conclusion
The advent of AI-powered document question answering has transformed the way we interact with information. By leveraging sophisticated models and techniques, these tools empower users to extract precise, contextual insights from their documents with remarkable efficiency. Whether through user-friendly online platforms or custom-built systems, the ability to "chat" with your files is no longer a futuristic concept but a practical reality that significantly boosts productivity and enhances understanding across all domains.
Recommended Further Exploration
- How to build a custom AI document analysis system?
- What are the best AI tools for summarizing academic papers?
- Explore the impact of Retrieval Augmented Generation (RAG) on LLM performance.
- Investigate AI applications in legal document review and compliance.
References
Last updated May 21, 2025