
全面洞察:AI大模型对比网站与选择指南
探索领先AI模型,助您找到最适合的智能伙伴
随着人工智能技术的飞速发展,市面上涌现出众多强大的AI大模型,如OpenAI的ChatGPT、Anthropic的Claude、Google的Gemini等。面对琳琅满目的选择,用户常常感到困惑:哪款AI模型最适合我的需求?幸好,现在有许多专业的网站和工具致力于对这些AI模型进行详细的比较和排名,帮助用户做出明智的决策。
关键洞察
- 综合性比较平台:Artificial Analysis、LLM Stats和Vellum AI等网站提供了全面的AI模型排行榜,涵盖了性能、价格、速度、上下文窗口等关键指标。
- 任务特定优势:不同的AI模型在特定任务上表现出显著优势。例如,GPT-4o和Claude 3.5 Sonnet在编码和高级推理方面表现出色,而Gemini 1.5 Flash则以其极快的输出速度见长。
- 用户体验与“个性”:除了技术指标,AI模型的“个性”或交互体验也是重要的选择因素。许多平台允许用户实时测试不同模型,以便亲身感受其风格和响应方式。
为什么需要AI模型对比网站?
AI模型的能力和应用场景日益广泛,从日常的文本生成、代码辅助到复杂的科学研究和多模态理解。然而,没有一个模型是“万能”的。每个模型都有其独特的优势和局限性,例如在处理长文本、生成创意内容、进行数学运算或代码编写时的表现各不相同。对比网站的出现正是为了解决这一痛点,它们通过结构化的数据和用户反馈,让选择过程变得更加透明和高效。
这些平台通常会根据一系列基准测试(benchmarks)来评估模型的性能。这些基准测试旨在衡量模型在特定任务上的能力,例如:
- MMLU (Massive Multitask Language Understanding):评估模型在跨学科知识和解决问题方面的通用能力。
- HumanEval:专注于代码生成和调试能力。
- GPQA:测试模型在高级推理和复杂问题解决上的表现。
- DROP:衡量模型在阅读理解和推理方面的准确性。
主要AI模型对比网站概览
以下是一些当前领先的AI模型对比网站,它们提供了丰富的信息和实用的工具,帮助用户进行选择:
Artificial Analysis (artificialanalysis.ai)
这个网站提供了对AI模型的深入比较和分析,涵盖了质量、价格、输出速度、延迟和上下文窗口等关键性能指标。它有详细的排行榜,允许用户点击任何模型查看其详细指标。例如,它指出OpenAI的o4-mini和o3以及Gemini 2.5 Pro在质量方面表现突出,而DeepSeek R1 Distill Qwen 1.5B和Gemini 2.5 Flash则在输出速度上领先。
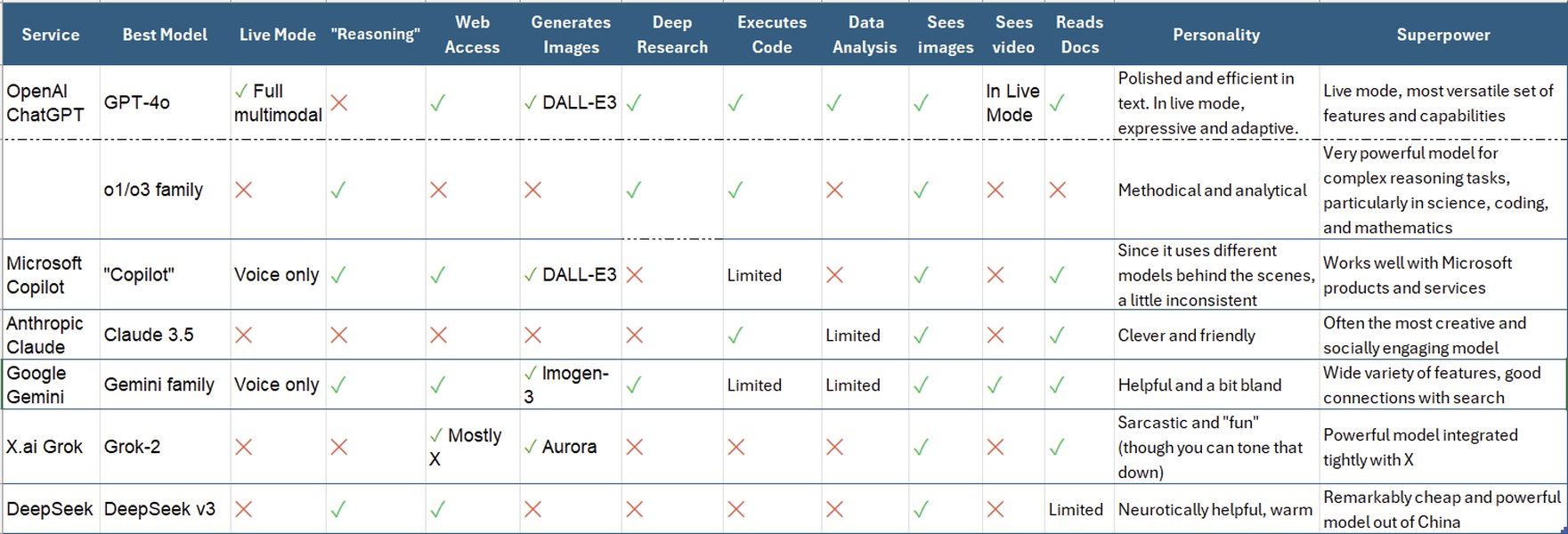
图片:不同AI模型特性概览
LLM Stats (llm-stats.com)
LLM Stats 提供了一个综合的AI(LLM)排行榜,包含基准测试、定价和功能。它提供了最新的模型版本(2024年4月后发布)的公开基准性能数据,并支持通过交互式分析工具比较领先的LLM模型。用户可以根据上下文窗口、速度和价格等指标筛选模型,获取全面的性能指标和基准数据。
Vellum AI LLM Leaderboard (vellum.ai/llm-leaderboard)
Vellum AI的LLM排行榜展示了最先进模型(SOTA)的最新公开基准性能。它强调了Claude 3.5 Sonnet在多项基准测试中的出色表现,例如在编码任务(HumanEval)中以92.00%位居榜首,通用能力(MMLU)也表现强劲。Meta的开源模型,特别是Llama 3.1 405b,在基准测试中表现出色,与顶级专有模型竞争激烈。
Chatbot Arena (lmarena.ai) / LMSYS Org
Chatbot Arena是一个开放平台,通过人类偏好来评估AI。用户可以与不同的AI语言模型进行聊天并比较其能力,甚至可以自定义测试参数,如温度,以了解不同设置如何影响模型输出。这是一个非常实用的“沙盒”环境,适合亲身体验不同模型的风格和表现。
Compare AI Models (compareaimodels.com)
这个网站提供了一个侧边比较工具,可以实时测试GPT-4o、Claude、Llama、Flux、Mistral等多种AI模型的提示,并分析其性能。它旨在帮助用户在众多模型中做出选择,提供全面的AI比较和洞察。
OverallGPT (overallgpt.com)
OverallGPT允许用户并排比较不同AI模型的答案,提供AI生成答案的透明视图。这对于需要评估模型准确性、相关性和决策过程的用户来说非常有用。
如何选择最适合的AI模型?
选择最佳AI模型并非易事,因为它高度依赖于您的具体需求和应用场景。以下是一些关键考虑因素:
任务类型
- 文本生成与创意写作:如果您需要撰写长篇文章、营销文案或进行创意头脑风暴,Anthropic的Claude(尤其是Claude 2及其后续版本,因其长上下文窗口)和ChatGPT(因其通用性能和广泛应用)通常是优秀的选择。
- 代码编写与审查:GPT-4o、Claude 3.5 Sonnet和DeepSeek-R1在编码任务上表现突出。它们能帮助调试、生成代码片段,甚至进行代码审查。
- 数据分析与推理:OpenAI的GPT系列(如GPT-4o、o1、o3-mini)和Google的Gemini 2.5 Pro在分析和推理任务上表现强劲。
- 多模态处理:GPT-4o和Gemini 2.5 Pro等模型在处理图像和文本输入并生成相应输出方面有更强的能力。
- 客户服务与聊天机器人:Gemini因其在维持对话上下文和提供相关有用帮助方面的优势,被认为是构建客户支持聊天机器人的优秀选择。
性能指标
- 准确性与质量:高准确性是模型有效性的基石。对比网站上的基准测试分数(如MMLU、GPQA)能直观反映模型的综合能力。
- 输出速度与延迟:对于需要实时响应的应用(如聊天机器人、交互式工具),模型的输出速度和延迟至关重要。
- 上下文窗口:上下文窗口越大,模型在处理长文本或长时间对话时保持连贯性的能力越强。
- 价格:模型的定价模式(按token计费)会影响长期使用成本,特别是对于大规模应用。Gemma和Qwen系列通常提供更具成本效益的选择。
“个性”与用户体验
除了硬性指标,许多用户发现不同AI模型有其独特的“个性”或响应风格。有些模型可能更简洁直接,有些则更详细、更具解释性。例如,Claude有时会采取更详细的路线,提出多种解决方案。通过免费试用或对比工具,亲身体验不同模型,找到与您的偏好和工作流程最契合的“AI伙伴”是非常重要的。
开源与闭源
市场上存在开源和闭源AI模型。开源模型(如Llama系列、Mistral)提供了更高的灵活性和可定制性,但可能需要更多的技术专长来部署和管理。闭源模型(如OpenAI的GPT系列、Anthropic的Claude系列)通常提供易于使用的API和更稳定的性能,但其内部运作不透明。
AI模型性能雷达图
为了更直观地理解不同AI模型在关键能力上的表现,我们可以构建一个雷达图。以下图表模拟了ChatGPT 4o、Claude 3.5 Sonnet和Google Gemini 2.5 Pro在各项性能指标上的相对优势,这些数据基于对公开基准测试和专家意见的综合分析。
这张雷达图展示了主要AI模型在几个关键能力上的相对表现。例如,ChatGPT 4o在通用推理和多模态能力上得分较高,而Claude 3.5 Sonnet则在长文本理解和代码生成方面更胜一筹。DeepSeek-R1在输出速度和成本效益上具有显著优势,这使其成为特定场景下的有力竞争者。
AI模型比较工具与平台
除了上述网站,还有一些工具和平台旨在简化AI模型的比较过程,提供更便捷的用户体验:
- ChatLabs:允许用户选择200多种模型进行比较,并根据具体任务进行测试。
- HuggingChat:提供互联网访问功能,并允许用户根据自身需求构建自定义聊天机器人。
- Rawbot:一个探索和比较AI模型功能的平台,为研究人员、开发人员和商业领袖提供关于AI模型选择的信息。
- Countless.dev:一个免费开源的平台,可以轻松比较所有AI模型提供商,包括价格计算器和功能比较工具。
YouTube上的AI模型比较视频
为了更生动地了解AI模型之间的差异,许多内容创作者在YouTube上发布了详尽的比较视频。这些视频通常会实际演示不同模型在处理相同提示时的表现,并提供他们的个人见解和测试结果。
视频:最佳AI模型比较方法概览。该视频详细介绍了如何使用免费工具对GPT-4o、Gemini 2.0和Claude 3.5等顶级模型进行比较,并提供了实用技巧,帮助用户直观地看到不同模型的输出差异。这对于初学者和需要快速了解模型特性的用户来说非常有帮助。
主要AI模型及其特点对比
为了更清晰地对比几款主流AI模型,以下表格总结了它们的核心特点和推荐用途:
| AI 模型 | 主要特点 | 优势 | 推荐用途 | 主要提供商 |
|---|---|---|---|---|
| ChatGPT (GPT-4o) | 通用性强,多模态能力,实时对话 | 综合性能卓越,擅长多种任务,强大的多语言和视觉内容理解 | 日常聊天,文本创作,代码辅助,多模态交互 | OpenAI |
| Claude (Claude 3.5 Sonnet) | 长上下文窗口,安全与可解释性,擅长写作与代码审查 | 处理长篇文档,减少错误,生成高质量的创意和技术内容 | 长文本总结,复杂写作,代码审查,安全敏感应用 | Anthropic |
| Google Gemini (Gemini 2.5 Pro/Flash) | 高速输出,多模态能力,实时信息访问 | 速度快,上下文保持能力强,与Google生态系统集成 | 实时聊天机器人,客户支持,快速信息检索,编程与数学(Pro) | |
| DeepSeek-R1 | 高推理能力,高效率,低成本 | 在特定基准测试中表现出色,尤其在数学和推理方面 | 需要高推理能力的任务,注重成本效益的开发 | DeepSeek (中国) |
| Llama 3.1 Instruct | 开源,高性能,灵活性高 | 可用于自定义和微调,社区支持活跃,在通用能力上与闭源模型竞争 | 研究,定制化应用,部署私有模型 | Meta |
| Grok | 与X(Twitter)实时数据整合,独特幽默感 | 实时获取网络信息,适合X平台用户 | 时事新闻摘要,社交媒体分析,需要时效性信息的任务 | X.ai |
常见问题解答 (FAQ)
总结
AI大模型的选择是一个动态的过程,需要结合最新的性能数据、个人需求和实际体验。通过利用像Artificial Analysis、LLM Stats、Vellum AI和Chatbot Arena这样的专业对比网站,您可以系统地评估不同模型的优劣,从而找到最适合您的智能助手。随着AI技术的持续进步,这些对比工具也将不断更新,为用户提供更精准、更实用的决策依据。