
揭秘 Amazon OpenSearch:开源搜索与分析引擎的强大动力
深入了解 Amazon OpenSearch 项目的核心、托管服务优势,并通过全面的日志分析实例探索其实际应用。
Amazon OpenSearch 是一个基于 Apache Lucene 构建的分布式、社区驱动、100% 开源的搜索和分析套件,广泛应用于日志分析、实时应用程序监控、网站搜索、向量搜索等多种场景。它起源于 Elasticsearch 7.10.2 和 Kibana 7.10.2 的一个分支,采用 Apache License Version 2.0 (ALv2) 许可,由亚马逊云科技 (AWS) 及其社区伙伴积极维护和发展。
为了简化用户在云上部署、操作和扩展 OpenSearch 集群的复杂性,AWS 提供了 Amazon OpenSearch Service,这是一项完全托管的服务。它负责处理集群预置、节点故障检测与替换、补丁更新、备份等繁重的运维任务,让用户能够专注于利用 OpenSearch 的强大功能来获取数据洞察,而无需担心底层基础设施的管理。
核心亮点速览
- 强大的托管服务: Amazon OpenSearch Service 自动化了集群管理,提供高可用性、数据持久性和安全性,并支持多种实例类型以优化成本和性能。
- 广泛的应用场景: 从 PB 级的日志聚合分析、毫秒级实时监控到先进的语义和向量搜索,满足多样化的数据处理需求。
- 开放与灵活: 基于 Apache 2.0 许可的开源项目,拥有活跃的社区支持,并能与众多 AWS 服务(如 S3, Lambda, Kinesis, CloudWatch)无缝集成。
深入了解 Amazon OpenSearch Service
Amazon OpenSearch Service 不仅仅是托管了开源 OpenSearch,它还集成了众多 AWS 的优势,为用户提供了一个企业级的搜索和分析解决方案。
关键特性与优势
托管与易用性
AWS 负责所有底层基础设施的管理,包括硬件预置、软件安装与配置、打补丁、备份和监控。用户可以通过 AWS 管理控制台、CLI 或 API 轻松创建、配置和管理 OpenSearch 域(集群)。这极大地降低了运维复杂度和成本。
弹性伸缩与性能
服务支持按需扩展计算和存储资源,可以根据工作负载自动调整集群规模。它提供多种针对不同工作负载优化的实例类型,包括基于 AWS Graviton 处理器的实例(如 M6g, C6g, R6g)以及专门优化的 OR1、OR2、OM2 实例,这些实例可显著提升索引吞吐量(高达 38%)并降低查询延迟(高达 50%)。服务能提供毫秒级的交互式搜索响应。
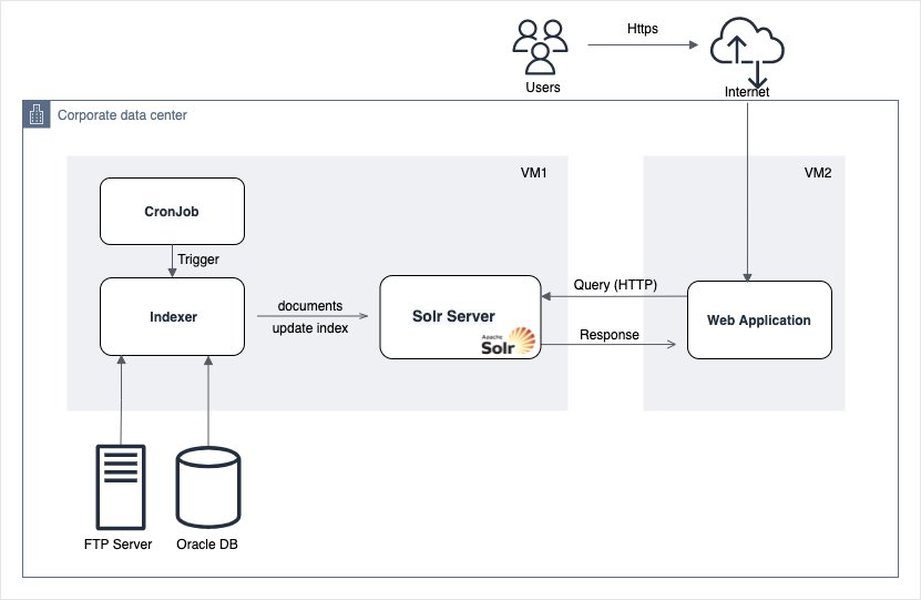
一个展示如何将数据导入 Amazon OpenSearch Service 的架构示例
高可用性与持久性
支持跨多个可用区 (Multi-AZ) 部署,自动检测并替换故障节点,确保服务的高可用性。通过与 Amazon S3 集成进行自动快照备份,保障数据的持久性和灾难恢复能力。
安全性与合规性
提供多层安全防护:
- 网络安全: 支持在 Amazon VPC 中部署,实现网络隔离。
- 访问控制: 与 AWS Identity and Access Management (IAM) 集成,实现精细的访问权限控制。
- 数据加密: 支持静态数据加密和传输中数据加密。
- 审计日志: 可以将审计日志发布到 CloudWatch Logs 或 S3,满足合规性要求。
丰富的功能与集成
- OpenSearch Dashboards: 内置强大的可视化工具 (源自 Kibana),用于数据探索、可视化和仪表板创建。
- 查询语言: 支持 OpenSearch 查询 DSL、SQL 和 Piped Processing Language (PPL)。
- 向量引擎: 支持向量嵌入的存储和 k-NN 相似性搜索,赋能语义搜索、推荐系统等 AI 应用,可扩展至数十亿向量并保持毫秒级延迟。
- 告警与异常检测: 内置告警插件,可根据数据阈值触发通知;提供基于机器学习的异常检测功能。
- 数据摄取: 可通过 OpenSearch Ingestion 或 Logstash、Fluentd/Fluent Bit 等工具,以及与 Kinesis Data Firehose、AWS Lambda、Amazon S3 的集成来轻松导入数据。最近还推出了与 Amazon S3 的零 ETL 集成(预览版),简化了 S3 数据的查询和分析流程。
- 存储层级: 提供 Hot、UltraWarm 和 Cold 存储层,允许用户根据数据访问频率和成本需求平衡存储。UltraWarm 可将成本降低高达 70-90%。

Amazon OpenSearch Service 与 S3 的零 ETL 集成简化了数据分析流程
成本效益
采用按需付费模式,无预付费用。用户可以通过选择合适的实例类型、使用预留实例 (Reserved Instances,最高可节省 50%-60% 费用) 以及利用不同的存储层来优化成本。例如,OR1 实例相比同类实例可提升高达 30% 的性价比。此外,还提供了 OpenSearch Serverless 选项,自动预置和扩展资源,用户只需为实际处理的数据量和使用的计算单元付费,进一步简化管理并优化成本。

Amazon OpenSearch Serverless 提供自动化的资源管理和成本优化
Amazon OpenSearch Service 特性评估
为了更直观地展示 Amazon OpenSearch Service 的各项能力,下面的雷达图基于其核心特性进行了主观评估(分数越高代表能力越强):
该图表突显了 Amazon OpenSearch Service 在可扩展性、性能、安全性和集成能力方面的强大优势,同时其托管特性也带来了极高的易用性。成本效益通过多种优化选项得以实现,功能集也相当丰富,开源社区则提供了额外的支持。
Amazon OpenSearch 核心概念与用例
以下思维导图概述了 Amazon OpenSearch 项目的核心组成部分及其关键应用领域:
这个思维导图清晰地展示了 OpenSearch 项目围绕其核心引擎、托管服务和可视化工具,支撑着从传统日志分析到现代 AI 搜索的广泛应用场景,并通过一系列关键特性提供强大的数据处理能力。
全面实际应用示例:企业级日志分析与监控平台
为了具体说明 Amazon OpenSearch Service 的强大功能,让我们构建一个全面的实际使用场景:为一个大型 Web 应用程序构建集中式日志分析和实时监控平台。
业务背景与需求
假设一个运行在 AWS (如 EC2 实例、容器服务 ECS/EKS) 上的高流量在线服务(例如,电商平台、社交媒体应用或 SaaS 服务),每天产生数 GB 到数 TB 的日志数据,包括:
- 应用程序日志 (INFO, WARN, ERROR)
- Web 服务器访问日志 (Nginx, Apache)
- 数据库慢查询日志
- 用户行为日志(点击流)
- 安全审计日志
该平台需要实现以下目标:
- 集中存储: 将分散在不同服务器和服务的日志统一收集和存储。
- 实时分析: 能够近乎实时地搜索、查询和分析日志数据。
- 故障排查: 快速定位应用程序错误、性能瓶颈和异常行为。
- 业务监控: 监控关键业务指标(如用户注册量、订单量、API 响应时间)。
- 安全审计: 满足安全合规要求,检测潜在的安全威胁。
- 可视化: 通过仪表板直观展示系统健康状况和业务趋势。
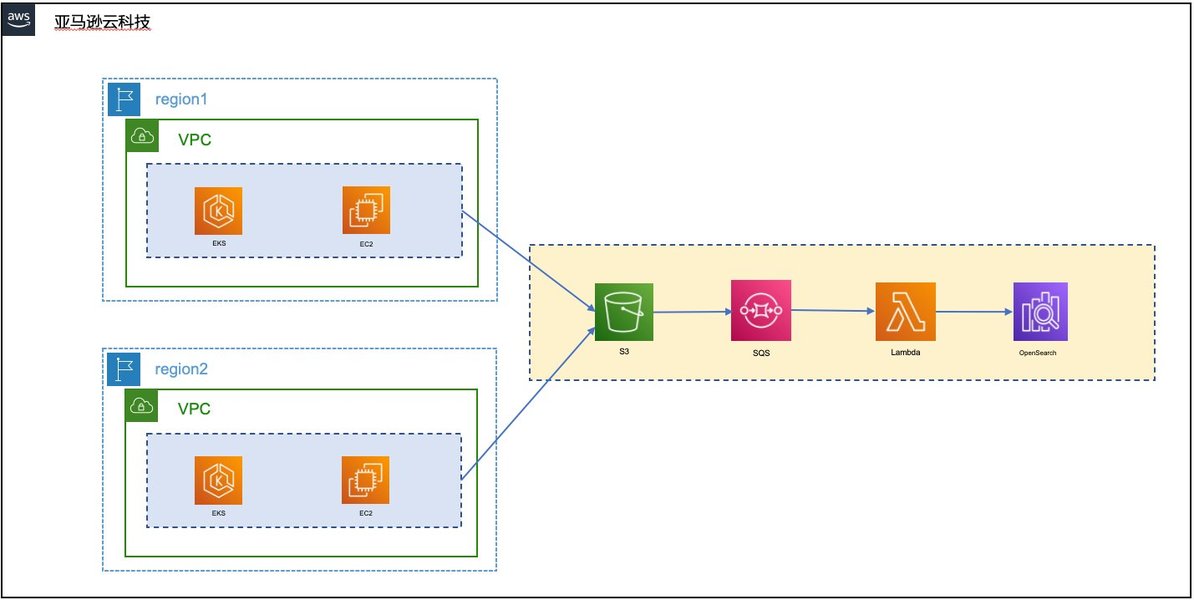
一个典型的基于 Amazon OpenSearch Service 的集中式日志分析架构
解决方案架构与实施步骤
1. 日志收集 (Collection)
在运行应用程序的服务器或容器上部署轻量级的日志代理,如 AWS for Fluent Bit、Fluentd 或 CloudWatch Agent。配置这些代理以监控指定的日志文件或标准输出,并将日志事件转发出去。
2. 日志传输与缓冲 (Transport & Buffering)
为了提高系统的可靠性和弹性,通常会引入一个中间缓冲层。日志代理可以将日志发送到:
- Amazon Kinesis Data Firehose: 这是一个完全托管的服务,可以可靠地捕获、转换日志数据,并将其批量加载到 Amazon OpenSearch Service。它可以处理数据格式转换(如 JSON)、压缩和加密。
- Amazon CloudWatch Logs: 将日志发送到 CloudWatch Logs Log Groups。
- Self-managed Buffer (如 Kafka): 对于更复杂的需求,可以使用 Kafka 作为缓冲。
3. 日志摄取 (Ingestion)
将缓冲后的日志数据导入 Amazon OpenSearch Service 域:
- 从 Kinesis Data Firehose: 配置 Firehose 交付流直接将数据写入 OpenSearch Service 域。这是推荐的方式之一,因为它简化了流程。
- 从 CloudWatch Logs: 使用 AWS Lambda 函数订阅 CloudWatch Logs Log Groups。当新日志到达时,Lambda 函数被触发,处理日志数据(可能需要解析和转换)并将其发送到 OpenSearch Service。AWS 提供了现成的 Lambda 蓝图。
- 使用 OpenSearch Ingestion: 配置 OpenSearch Ingestion 管道从源(如 Kafka, S3)拉取数据,进行转换、丰富、聚合和过滤,然后写入 OpenSearch Service。
- 使用 Logstash: 如果已经在使用 Logstash,可以配置其 OpenSearch 输出插件将数据发送到托管服务域。
4. Amazon OpenSearch Service 域配置
创建一个 Amazon OpenSearch Service 域:
- 实例选择: 根据预期的查询负载和数据量选择合适的实例类型(如 `m6g.large.search` 或 `r6g.xlarge.search`)。
- 存储: 配置 EBS 存储卷的大小。可以启用 UltraWarm 或 Cold 存储层来降低长期存储成本。
- 集群配置: 部署为 Multi-AZ 以获得高可用性。配置适当数量的数据节点和专用的主节点(推荐用于生产环境)。
- 访问策略: 配置基于 IAM 的访问策略和/或 VPC 访问,确保只有授权用户和服务可以访问域。
- 索引管理: 设置索引生命周期管理 (ILM) 策略,自动管理索引(例如,定期滚动索引,将旧索引移至 UltraWarm/Cold 存储,最终删除)。
5. 搜索、分析与可视化 (Search, Analyze, Visualize)
使用 OpenSearch Dashboards (通过 OpenSearch Service 域的端点访问):
- 索引模式创建: 定义索引模式以匹配摄入的日志数据(例如,`app-logs-*`)。
- 数据探索 (Discover): 使用简单的文本搜索或强大的查询 DSL/SQL/PPL 来交互式地搜索和过滤日志。例如,查找所有包含 "error" 并且发生在特定时间段内的日志:`level:error AND @timestamp:[now-1h TO now]`。
- 可视化创建 (Visualize): 创建各种图表(折线图、柱状图、饼图、地图等)来可视化日志数据。例如,创建一个折线图显示每分钟的错误日志数量,或创建一个柱状图显示请求量最高的 Top 10 URL。
- 仪表板构建 (Dashboard): 将相关的可视化图表组合成一个或多个仪表板,提供系统健康状况、性能指标和业务趋势的整体视图。
6. 监控与告警 (Monitor & Alert)
- 集群监控: 利用 Amazon CloudWatch 监控 OpenSearch Service 域的关键指标(CPU/内存利用率、磁盘空间、JVM 内存压力、集群健康状态等)。设置 CloudWatch 警报,在指标异常时通知运维团队。
- 日志数据告警: 使用 OpenSearch 的告警插件,基于特定的查询结果设置告警规则。例如,当过去 5 分钟内出现超过 100 条 5xx 错误日志时,触发告警并通过 Webhook、SNS 或 Email 发送通知。
- 慢日志分析: 启用搜索慢日志和索引慢日志,并将它们发布到 CloudWatch Logs。分析这些日志有助于识别和优化性能不佳的查询或索引操作。
实施效益
- 运维效率提升: 托管服务大大减少了管理开销,让团队专注于数据价值。
- 快速故障定位: 强大的搜索功能使得从海量日志中定位问题根源的时间从几小时缩短到几分钟甚至几秒。
- 实时业务洞察: 通过实时仪表板,业务和运营团队可以即时了解系统状态和用户行为。
- 增强的安全性: 集中审计和访问控制有助于满足合规性要求,并能更快地检测和响应安全事件。
- 可扩展性与成本效益: 能够轻松应对流量高峰,并通过分层存储和实例优化来控制成本。
这个全面的例子展示了如何利用 Amazon OpenSearch Service 及其周边 AWS 服务生态系统,构建一个强大、可扩展且易于管理的日志分析和监控平台,从而显著提高运营效率和系统可靠性。
关键特性概览表
下表总结了 Amazon OpenSearch Service 的一些关键特性及其优势:
| 特性 | 描述 | 优势 |
|---|---|---|
| 完全托管 | AWS 负责基础设施管理、补丁、备份、监控等。 | 降低运维复杂性,节省人力成本,专注业务。 |
| 弹性伸缩 | 按需调整计算和存储资源,支持自动扩展。 | 应对流量波动,优化资源利用率和成本。 |
| 多可用区部署 | 支持跨多个 AWS 可用区部署集群。 | 提供高可用性和容错能力。 |
| 精细访问控制 | 与 IAM 集成,支持 VPC 访问,提供字段级安全。 | 保障数据安全,满足合规要求。 |
| OpenSearch Dashboards | 内置强大的数据可视化和探索工具。 | 轻松创建仪表板,直观理解数据。 |
| 多种查询语言 | 支持 OpenSearch DSL, SQL, PPL。 | 灵活满足不同用户的查询习惯和需求。 |
| 向量引擎 | 支持 k-NN 相似性搜索,可扩展至数十亿向量。 | 赋能 AI 应用,如语义搜索、推荐系统。 |
| 分层存储 | 提供 Hot, UltraWarm, Cold 存储层。 | 根据数据访问频率优化存储成本。 |
| OpenSearch Serverless | 无服务器选项,自动管理容量。 | 进一步简化管理,按实际使用付费。 |
| 集成 AWS 生态 | 与 S3, Kinesis, Lambda, CloudWatch 等无缝集成。 | 构建端到端的 数据处理和分析管道。 |
常见问题解答 (FAQ)
什么是 OpenSearch?
OpenSearch 是一个社区驱动、基于 Apache Lucene 的开源搜索和分析套件。它源自 Elasticsearch 7.10.2 和 Kibana 7.10.2 的分支,采用 Apache 2.0 许可。它包含一个分布式搜索引擎 (OpenSearch) 和一个可视化界面 (OpenSearch Dashboards),用于日志分析、实时监控、全文搜索等场景。
Amazon OpenSearch Service 是什么?它和 OpenSearch 有什么关系?
Amazon OpenSearch Service 是 AWS 提供的一项完全托管的服务,它简化了在云中部署、操作和扩展开源 OpenSearch 集群的过程。它使用开源的 OpenSearch 作为其核心引擎,并增加了 AWS 的管理、安全、可扩展性和集成特性。您可以将 Amazon OpenSearch Service 视为运行和管理 OpenSearch(以及兼容的 Elasticsearch OSS 版本)的一种便捷方式。
Amazon OpenSearch Service 的主要应用场景有哪些?
主要应用场景包括:
- 日志分析:集中收集、存储和分析来自应用程序、服务器和网络设备的日志,用于故障排查、性能监控和安全审计。
- 实时应用程序监控:监控应用程序性能指标、用户活动和业务指标,通过仪表板和告警实时了解系统状态。
- 网站和应用程序搜索:为网站、电商平台或内部知识库提供强大的全文搜索功能。
- 向量搜索/语义搜索:利用向量引擎实现基于含义的搜索、推荐系统、图像搜索等 AI 应用。
- 安全信息和事件管理 (SIEM):聚合安全日志,检测威胁并进行调查。
Amazon OpenSearch Service 如何收费?
Amazon OpenSearch Service 主要根据以下几个方面收费:
- 实例小时数:根据您运行的 OpenSearch 实例类型和数量按小时收费。
- 存储:根据您使用的 EBS 存储量(或 UltraWarm/Cold 存储量)收费。
- 数据传输:标准 AWS 数据传输费用适用。
- 可选功能:如启用专用主节点、跨可用区复制等可能会产生额外费用。
对于 OpenSearch Serverless 选项,收费基于 OpenSearch 计算单元 (OCU) 的使用量和索引数据的存储量。
什么是 OpenSearch Serverless?
OpenSearch Serverless 是 Amazon OpenSearch Service 提供的一种无服务器部署选项。它会自动预置、配置和扩展所需的 OpenSearch 资源,以适应不断变化的数据量和查询负载,用户无需管理实例或集群。这使得运行间歇性或不可预测工作负载的成本效益更高,并进一步简化了操作。
参考资料
- 托管式开源搜索和日志分析 — Amazon OpenSearch Service — AWS
- What is OpenSearch? - OpenSearch Explained - AWS
- 什么是 Amazon OpenSearch Service? - Amazon OpenSearch Service
- Amazon OpenSearch 服务的最佳运营实践 - 亚马逊 OpenSearch 服务
- 认识 OpenSearch 与向量引擎语义搜索 | 亚马逊 AWS 官方博客
- Centralized Logging with OpenSearch 解决方案概述 - Centralized Logging with OpenSearch Implementation Guide
- Make it Easy to Retrieve, Search, Visualize, and Analyze Your Data: Amazon OpenSearch Service | by Elif Nurber Borucu | Medium
推荐探索
 aws.amazon.com
aws.amazon.com
aws.amazon.com
aws.amazon.com
 docs.aws.amazon.com
aws.amazon.com
docs.aws.amazon.com
aws.amazon.com
 dev.amazoncloud.cn
docs.aws.amazon.com
docs.aws.amazon.com
aws.amazon.com
aws.amazon.com
aws.amazon.com
dev.amazoncloud.cn
docs.aws.amazon.com
docs.aws.amazon.com
aws.amazon.com
aws.amazon.com
aws.amazon.com
 docs.amazonaws.cn
aws.amazon.com
docs.amazonaws.cn
aws.amazon.com
 amazonaws.cn
docs.aws.amazon.com
aws.amazon.com
aws.amazon.com
aws.amazon.com
docs.aws.amazon.com
dev.amazoncloud.cn
aws.amazon.com
amazonaws.cn
aws.amazon.com
docs.aws.amazon.com
docs.aws.amazon.com
aws.amazon.com
docs.aws.amazon.com
aws.amazon.com
amazonaws.cn
docs.aws.amazon.com
aws.amazon.com
aws.amazon.com
aws.amazon.com
docs.aws.amazon.com
dev.amazoncloud.cn
aws.amazon.com
amazonaws.cn
aws.amazon.com
docs.aws.amazon.com
docs.aws.amazon.com
aws.amazon.com
docs.aws.amazon.com
aws.amazon.com
Last updated April 22, 2025