
Understanding Supersteps in Apache Pregel
The Backbone of Parallel Graph Processing
Key Takeaways
- Synchronous Iterations: Supersteps define synchronized computation phases in Pregel's Bulk Synchronous Parallel model.
- Message-Passing Paradigm: Communication between vertices occurs via messages, facilitating scalable graph processing.
- Termination Conditions: Computation halts when no active vertices remain and no messages are in transit.
Introduction
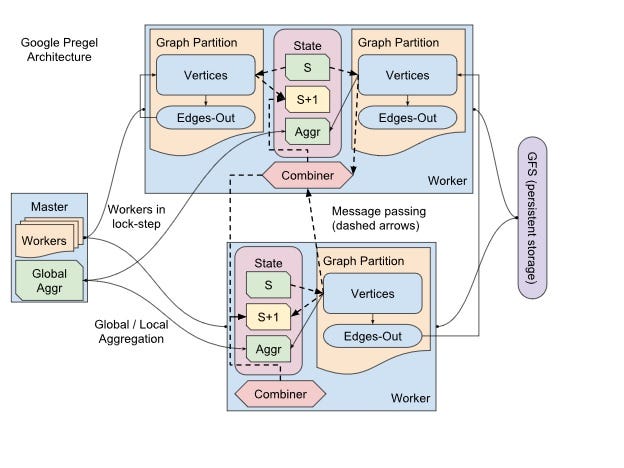
Apache Pregel is a distributed computing framework designed for large-scale graph processing. Inspired by Google's Pregel system, it employs the Bulk Synchronous Parallel (BSP) model to manage computations across massive graphs efficiently. At the core of Pregel's computational model lies the concept of a superstep, which orchestrates the parallel processing of graph vertices in a structured and synchronized manner.
What is a Superstep?
A superstep is a fundamental iteration in the Pregel computation model that facilitates parallel processing of graph vertices. Each superstep represents a discrete phase where vertices perform computations, communicate via messages, and update their states based on received information. This iterative approach allows Pregel to handle complex graph algorithms efficiently by breaking down computations into manageable steps.
Components of a Superstep
1. Vertex Computation
During a superstep, every active vertex in the graph executes a user-defined Compute() function. This function processes any incoming messages from the previous superstep, updates the vertex's state, and can send new messages to other vertices. The vertex-centric approach ensures that each vertex operates independently, promoting scalability and parallelism.
2. Message Passing
Communication between vertices is achieved through message passing. Messages sent during the current superstep are not delivered immediately but are instead queued for delivery at the beginning of the next superstep. This decouples the sending and receiving processes, preventing race conditions and ensuring orderly communication across the distributed system.
3. Synchronization Barrier
At the end of each superstep, a global synchronization barrier ensures that all vertex computations and message passing are complete before proceeding to the next superstep. This barrier guarantees that the system remains in lockstep, maintaining consistency and coordination across all processing nodes.
4. Vertex Activation and Halting
Vertices can be in an active or inactive state. Initially, all vertices are active. A vertex can choose to halt (become inactive) if it has no further work to do. However, if it receives a message in a subsequent superstep, it becomes active again. This mechanism optimizes resource usage by focusing computation on vertices that require processing.
Execution Flow of Supersteps
-
Superstep 0: Initialization
All vertices are activated and initialize their state. This superstep typically involves setting up initial values or parameters necessary for the algorithm.
-
Superstep 1: First Computation
Vertices execute their
Compute()functions, process any initial messages, update their states, and send out messages to neighboring vertices based on the computation. -
Subsequent Supersteps: Iterative Processing
Each subsequent superstep involves vertices processing messages received in the previous superstep, updating their states accordingly, and sending new messages. This iterative process continues until no active vertices remain and no messages are in transit, signaling the termination of the computation.
Advantages of Using Supersteps
- Parallelism: Supersteps enable simultaneous execution of computations across all active vertices, leveraging the full potential of distributed systems.
- Synchronization: The global synchronization barrier ensures orderly progression of computation, preventing inconsistencies and race conditions.
- Scalability: By breaking down computations into discrete, parallelizable supersteps, Pregel efficiently handles large-scale graphs spanning thousands to millions of vertices and edges.
- Message-Driven Architecture: The decoupled message-passing mechanism facilitates flexible and dynamic communication patterns between vertices, essential for varied graph algorithms.
- Resource Optimization: The activation and halting mechanism ensures that only necessary computations are performed, optimizing resource utilization across the cluster.
Use Cases of Supersteps in Graph Processing
Supersteps are instrumental in implementing a wide range of graph algorithms within the Pregel framework. Some prominent use cases include:
1. PageRank
The PageRank algorithm calculates the importance of each vertex (or web page) based on the number and quality of incoming links. During each superstep, vertices distribute their current rank to neighboring vertices, which accumulate these contributions to update their own ranks in the subsequent supersteps.
2. Shortest Path
Algorithms like Dijkstra's or Bellman-Ford utilize supersteps to iteratively update the shortest known distances from a source vertex to all other vertices in the graph. Messages carry tentative distance values that vertices use to refine their shortest path estimates.
3. Connected Components
Determining connected components involves identifying clusters of vertices that are mutually reachable. Supersteps facilitate the propagation of component identifiers across the graph, allowing vertices to update their component affiliations based on received messages.
4. Community Detection
Community detection algorithms identify groups of vertices that are more densely connected internally than with the rest of the graph. Supersteps enable the iterative refinement of community memberships based on local and global connectivity patterns.
Example Workflow: PageRank Algorithm
To illustrate the role of supersteps, let's delve into how the PageRank algorithm operates within the Pregel framework:
Initialization
In Superstep 0, each vertex initializes its PageRank value, typically starting with a uniform distribution.
Iterative Computation
-
Superstep 1:
Each vertex sends its current PageRank value, divided by the number of outgoing edges, to all its neighbors.
-
Superstep 2 and Beyond:
Vertices receive messages from their incoming neighbors, sum the contributions, and update their PageRank values accordingly. They then send out new messages based on the updated ranks if necessary.
-
Termination:
The algorithm continues supersteps until the PageRank values stabilize within a predefined threshold or a maximum number of supersteps is reached.
This iterative process exemplifies how supersteps orchestrate the coordination, communication, and computation necessary for effective graph analysis.
Termination Criteria
The Pregel computation concludes when one of the following conditions is met:
-
No Active Vertices: All vertices have voted to halt, and there are no messages in transit. This indicates that no further computations are necessary.
-
Maximum Supersteps Reached: A predefined limit on the number of supersteps is reached, preventing infinite loops in case the convergence condition isn't met.
These termination conditions ensure that the computation process is both efficient and bounded, allowing for predictable resource usage and completion times.
Conclusion
Supersteps are the cornerstone of Apache Pregel's ability to perform large-scale graph processing efficiently. By structuring computations into synchronized, parallel iterations, supersteps enable complex graph algorithms to run seamlessly across distributed systems. The combination of message passing, vertex-centric computation, and strict synchronization ensures both scalability and reliability, making Pregel a powerful tool for graph analytics in various domains.
References
Last updated January 24, 2025