
Exploring the Leading AI Voice Model APIs for Text-to-Speech in 2025
A Deep Dive into Top Text-to-Speech APIs for AI Applications
Key Highlights
- Neural Network Synthesis is Dominant: The most advanced and realistic AI voice generation relies heavily on neural network-based synthesis, leveraging deep learning models for human-like speech.
- Top Providers Offer Comprehensive Solutions: Companies like Google Cloud, Amazon, Microsoft Azure, and ElevenLabs are consistently ranked among the best for their high-quality voices, extensive language support, and robust API features.
- Versatile Applications Across Industries: Text-to-speech APIs are not limited to a single use case; they are being widely adopted in accessibility, e-learning, customer service, content creation, and entertainment.
The landscape of AI voice model APIs for text-to-speech (TTS) is rapidly evolving in 2025, driven by advancements in machine learning and the increasing demand for natural-sounding, human-like voice synthesis. These APIs are becoming indispensable tools for developers and businesses looking to integrate voice capabilities into their applications, enhance user experiences, and create engaging audio content. The best AI voice APIs today offer not just text-to-speech but also often include speech-to-text (STT) capabilities and natural language processing, enabling truly interactive voice experiences.
When evaluating the top voice model APIs, several factors come into play, including the naturalness and expressiveness of the generated speech, the range of languages and voices supported, customization options, ease of integration, scalability, and pricing. The leading platforms are leveraging sophisticated algorithms and deep learning models, particularly neural network synthesis, to produce voices that are virtually indistinguishable from human speech.
Leading Text-to-Speech API Providers in 2025
Several companies stand out in the competitive field of text-to-speech APIs as of 2025. These providers offer a range of features and capabilities catering to diverse needs, from simple text conversion to complex voice cloning and custom voice model training.
Top Tier API Solutions
Based on market analysis, user reviews, and technological capabilities, a few providers consistently rank at the top for their text-to-speech APIs:
Google Cloud Text-to-Speech
Google Cloud's Text-to-Speech API is widely recognized for its high-quality speech synthesis, powered by DeepMind's WaveNet technology. It offers a wide variety of lifelike voices and supports over 40 languages and dialects. Its features include custom voice creation and SSML support for fine-grained control over speech output.
Illustration of components in a voice assistant using Google Cloud services.
Amazon Polly
Amazon Polly is another prominent player, known for its neural text-to-speech voices that provide natural and expressive speech. It is suitable for various use cases, including e-learning platforms, accessibility tools, and voice-enabled devices. Polly supports multiple languages and offers features for customizing speech output.
Microsoft Azure Cognitive Services Speech
Microsoft Azure's Speech Services offer robust text-to-speech capabilities with a focus on enterprise integration. It provides high-quality voices and supports numerous languages and accents. Azure's offerings are particularly strong for businesses looking to incorporate speech technology into their existing workflows and applications.
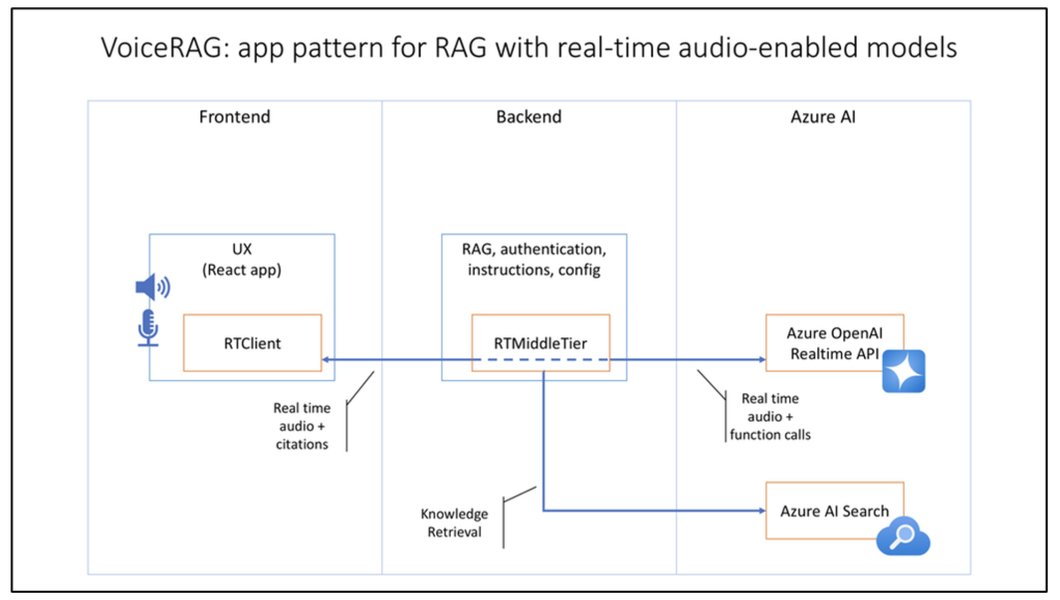
Screenshot showing Microsoft's VoiceRAG, an advanced voice interface.
ElevenLabs
ElevenLabs has quickly gained popularity for its state-of-the-art text-to-speech API that leverages advanced neural network models to convert text into natural-sounding speech with emotional depth. It is highly regarded for its realistic voices and is a popular choice among content creators, particularly for voiceovers and narration.
Youtube video thumbnail discussing the best AI voice generators.
Other Notable Providers
Beyond the top tier, several other providers offer compelling text-to-speech API solutions in 2025, each with its unique strengths:
IBM Watson Speech Services
IBM Watson offers speech-to-text and text-to-speech services with a focus on domain-specific applications. Its capabilities are valuable for businesses in industries requiring specialized terminology and accurate transcription and synthesis.
Deepgram
While known for its high-accuracy speech-to-text, Deepgram also offers the Aura Text-to-Speech API, optimized for real-time applications such as conversational AI and voicebots, providing lightning-fast voice synthesis.
Murf.ai
Murf.ai provides a text-to-speech API that focuses on delivering high-quality, human-like voices for various applications, designed for seamless integration into existing technology stacks.
Synthesys
Synthesys is an AI voice generator specifically designed for creating videos, offering a wide range of ultra-realistic human-sounding voices and AI-powered avatars.
Synthesys platform screenshot showcasing AI voice generation features.
PlayHT
PlayHT is recognized for its AI voice API that focuses on creating lifelike conversations, offering realistic voices and features for conversational AI applications.
Resemble AI
Resemble AI specializes in custom voice cloning, allowing users to create a personalized voice model using their own audio recordings for brand-specific voice synthesis.
Key Features and Capabilities
The leading text-to-speech APIs in 2025 offer a range of advanced features that go beyond basic text conversion:
Voice Naturalness and Expressiveness
Modern TTS APIs excel at generating voices that sound remarkably human, capturing nuances in tone, emotion, and rhythm. This is achieved through advanced neural network models that learn from vast datasets of human speech.
Language and Accent Support
The best APIs support a wide array of languages and dialects, enabling global applications. Many also offer various accents within a language, allowing for more localized and diverse voice outputs.
Customization Options
Developers can often customize aspects of the generated speech, such as pitch, speaking rate, pronunciation, and pauses, using features like SSML (Speech Synthesis Markup Language).
Voice Cloning
Advanced APIs offer voice cloning capabilities, allowing users to create a digital replica of a specific voice from a small audio sample. This is particularly useful for creating personalized voice experiences or maintaining brand consistency.
Youtube video thumbnail illustrating AI voice cloning.
Real-time and Batch Processing
Depending on the application, APIs offer both real-time synthesis for interactive applications like voice assistants and batch processing for generating longer audio content like audiobooks or podcasts.
Integration Capabilities
Leading APIs provide well-documented APIs and SDKs for various programming languages, making it easy for developers to integrate text-to-speech functionality into their applications.
Use Cases for Text-to-Speech APIs
Text-to-speech APIs are being adopted across numerous industries and applications, transforming how we interact with technology and consume content:
Accessibility
TTS is crucial for creating accessible content for individuals with visual impairments, reading difficulties, or learning disabilities, converting written text into spoken words.
E-learning and Education
TTS enhances e-learning platforms by converting course materials into audio, making lessons more engaging and accessible to learners with different preferences.
Customer Service and Support
AI-driven voice assistants and interactive voice response (IVR) systems powered by TTS APIs can handle customer inquiries, automate workflows, and improve efficiency in call centers.
Diagram illustrating the components of a web-based voice bot.
Content Creation
Content creators, including podcasters, YouTubers, and video producers, use TTS to generate voiceovers, narration, and character voices, saving time and resources compared to traditional recording methods.
Entertainment
TTS is used in video games, animation, and other forms of entertainment to provide character voices, narration, and localized audio content.
IoT Devices and Virtual Assistants
TTS enables smart speakers, virtual assistants, and other IoT devices to communicate with users in a natural and intuitive way.
Comparison of Top Text-to-Speech APIs (2025)
Here's a table summarizing some of the key features and characteristics of the leading text-to-speech API providers in 2025:
| API Provider | Key Strengths | Voice Quality / Naturalness | Language Support | Customization Options | Ideal Use Cases |
|---|---|---|---|---|---|
| Google Cloud Text-to-Speech | Powered by WaveNet, Wide range of voices and languages | Excellent, very lifelike | Extensive (40+ languages/dialects) | SSML, Custom Voice Creation | Various applications, including IoT and audio content generation |
| Amazon Polly | Neural TTS voices, AWS integration | Very Natural and expressive | Multiple languages | Customization features available | E-learning, accessibility, voice-enabled devices |
| Microsoft Azure Cognitive Services Speech | Strong enterprise integration, High-quality voices | High quality | Numerous languages and accents | Customization features available | Business applications, integrated workflows |
| ElevenLabs | Emotional depth and realism, Popular with content creators | Outstanding, highly realistic | Multiple languages | Customizable parameters | Voiceovers, narration, content creation |
| IBM Watson Speech Services | Domain-specific accuracy | High quality | Multiple languages | Customized models | Healthcare, finance, domain-specific applications |
| Deepgram (Aura) | Optimized for real-time, Fast synthesis | High quality | Multiple languages | Features for real-time applications | Conversational AI, voicebots |
| Murf.ai | Focus on human-like voices, Easy integration | High quality, realistic | 20+ languages | Pitch, speed, pronunciation, pauses, emphasis | Voiceovers, presentations, videos |
| Synthesys | Designed for video creation, AI avatars | Ultra-realistic human-sounding | 140+ languages | Customizable voice options | Video voiceovers, content creation |
| PlayHT | Focus on lifelike conversations | Realistic for conversational AI | Multiple languages | Features for conversational applications | Chatbots, virtual assistants |
| Resemble AI | Strong voice cloning capabilities | Highly customizable with cloning | Multiple languages | Custom voice model training | Personalized voice experiences, brand consistency |
The Future of AI Voice Synthesis
The field of AI voice synthesis is continuously advancing. Future developments are expected to bring even more realistic and expressive voices, improved control over emotional nuances, and broader language and dialect support. The integration of TTS with other AI technologies like natural language processing and speech-to-text will lead to more sophisticated and interactive AI voice agents and applications. The availability of open-source models also contributes to the innovation and accessibility of TTS technology.

Visual representation of speech synthesis technology.
Frequently Asked Questions
What is Text-to-Speech (TTS)?
Text-to-Speech (TTS) is a technology that converts written text into spoken audio. AI-powered TTS utilizes advanced algorithms and machine learning models to generate human-like and natural-sounding voices.
How do AI voice models work?
AI voice models, particularly those using neural network synthesis, analyze text input, break it down into phonetic components, and then generate audio waveforms that mimic human speech patterns, including intonation, rhythm, and emphasis.
What are the benefits of using a Text-to-Speech API?
Using a TTS API allows developers to easily integrate voice capabilities into their applications without building the underlying technology from scratch. It enables features like voice user interfaces, audio content generation, and accessibility tools. Benefits include scalability, access to high-quality voices, and reduced development time.
Which TTS API is best for realism?
Several APIs are recognized for their realistic voices, including Google Cloud, Amazon Polly (Neural voices), Microsoft Azure, and ElevenLabs. The "best" often depends on the specific requirements for the voice's tone, emotion, and application.
Can I create a custom voice with these APIs?
Yes, some advanced APIs like Google Cloud and Resemble AI offer features for creating custom voice models or cloning existing voices, allowing for a high degree of personalization.
Are there free Text-to-Speech options available?
While many top-tier APIs are paid services, some providers offer free tiers or limited free usage. There are also open-source text-to-speech projects available, although they may require more technical expertise to implement.
References
Last updated May 5, 2025