
Comparing Columns Across Different SELECT Statements in MS SQL Server
Unlocking Advanced Data Comparison Techniques for Robust SQL Analysis
Comparing data from different SELECT statements in MS SQL Server is a common yet critical task for database administrators, developers, and analysts. This process helps identify discrepancies, validate data integrity, and ensure consistency across various datasets, whether they originate from different tables, modified views, or snapshots of the same data at different times. The complexity can range from simple equality checks between two columns to sophisticated analyses involving multiple columns and large datasets.
Key Insights into SQL Column Comparisons
- Versatile Techniques: SQL offers a rich set of operators and clauses like
JOIN,UNION,EXCEPT,INTERSECT, andCASEstatements to compare columns from different SELECT statements effectively. Each method serves distinct comparison objectives, from finding matching rows to identifying unique or divergent data. - Handling Nulls and Data Types: Proper handling of
NULLvalues is crucial, as standard equality operators treatNULLas unknown, not equal. Additionally, ensuring compatible data types between compared columns is essential to prevent errors and ensure accurate results. - Performance Considerations: For large datasets, the choice of comparison method significantly impacts performance. Techniques involving
HASHBYTESorBINARY_CHECKSUMcan offer efficiency for comparing multiple columns simultaneously, while careful indexing and query optimization are always recommended.
Fundamental Approaches to Column Comparison
When comparing two columns from different SELECT statements in MS SQL Server, you are essentially comparing two datasets. The goal might be to find rows that match, rows that differ, or to highlight specific discrepancies. Here are the foundational methods to achieve this.
Using JOINs for Direct Comparison
JOIN operations are fundamental for combining rows from two or more tables based on a related column between them. When comparing columns from different SELECT statements, you can treat each SELECT statement as a derived table or a Common Table Expression (CTE) and then apply a JOIN.
INNER JOIN: Finding Common Rows
An INNER JOIN returns only the rows that have matching values in both datasets based on the join condition. If you want to see records where columns from two different SELECT statements are identical, an INNER JOIN is a straightforward approach.
SELECT
t1.ColumnA,
t1.ColumnB,
t2.ColumnC,
t2.ColumnD
FROM
(SELECT ColA AS ColumnA, ColB AS ColumnB FROM Table1 WHERE Condition1) AS t1
INNER JOIN
(SELECT ColC AS ColumnC, ColD AS ColumnD FROM Table2 WHERE Condition2) AS t2
ON
t1.ColumnA = t2.ColumnC;
LEFT JOIN / RIGHT JOIN: Identifying Non-Matches and Uniqueness
LEFT JOIN (or LEFT OUTER JOIN) returns all rows from the left dataset and the matching rows from the right dataset. If there is no match, NULL is returned for the right side's columns. This is incredibly useful for finding rows present in one dataset but not the other, or where a specific column's value differs.
SELECT
t1.ColumnA,
t1.ColumnB,
t2.ColumnC,
t2.ColumnD
FROM
(SELECT ColA AS ColumnA, ColB AS ColumnB FROM Table1 WHERE Condition1) AS t1
LEFT JOIN
(SELECT ColC AS ColumnC, ColD AS ColumnD FROM Table2 WHERE Condition2) AS t2
ON
t1.ColumnA = t2.ColumnC
WHERE
t2.ColumnC IS NULL; -- Rows in t1 that have no match in t2
Similarly, a RIGHT JOIN would identify rows unique to the right dataset.
Set Operators for Distinctness and Differences
SQL's set operators (UNION, EXCEPT, INTERSECT) are powerful for comparing the entire result sets of two SELECT statements, which implicitly compares all columns in those statements that have the same order and compatible data types.
UNION: Combining and Removing Duplicates
UNION combines the result sets of two or more SELECT statements and removes duplicate rows. While primarily for combining, its distinct nature can indirectly highlight differences if used with care.
SELECT ColumnA, ColumnB FROM Table1
UNION
SELECT ColumnC, ColumnD FROM Table2;
Note: For UNION, EXCEPT, and INTERSECT, the number and order of columns must be identical, and data types must be compatible.
EXCEPT: Finding Unique Rows
EXCEPT returns distinct rows from the first SELECT statement that are not found in the second SELECT statement. This is ideal for identifying rows that exist in one dataset but not the other.
SELECT Col1, Col2 FROM MyTableA
EXCEPT
SELECT Col1, Col2 FROM MyTableB;
This query will return rows from MyTableA that do not have an exact match (across Col1 and Col2) in MyTableB.
INTERSECT: Identifying Common Rows
INTERSECT returns distinct rows that are common to both SELECT statements. It's a way to find exact matches across entire rows.
SELECT Col1, Col2 FROM MyTableA
INTERSECT
SELECT Col1, Col2 FROM MyTableB;
This returns only those rows that exist identically in both MyTableA and MyTableB.
Advanced Comparison Techniques
Comparing Specific Column Values with CASE Statements
The CASE statement allows you to perform conditional logic within your queries, making it excellent for creating a "bit field" or indicator column that shows whether two columns are equal or different.
SELECT
t1.ID,
t1.ValueA,
t2.ValueB,
CASE
WHEN t1.ValueA = t2.ValueB THEN 'Match'
ELSE 'Mismatch'
END AS ComparisonResult
FROM
(SELECT ID, SomeColumn AS ValueA FROM SourceTable1) AS t1
JOIN
(SELECT ID, AnotherColumn AS ValueB FROM SourceTable2) AS t2
ON
t1.ID = t2.ID;
This approach is particularly useful when you need to highlight differences at a row level, even if the primary key matches.
Handling NULLs in Comparisons
SQL's three-valued logic (True, False, Unknown for NULLs) means that NULL = NULL evaluates to unknown, not true. To correctly compare columns that might contain NULL values, you often need to use functions like IS NULL, COALESCE, or NULLIF.
SELECT
t1.ID,
t1.ValueA,
t2.ValueB,
CASE
WHEN t1.ValueA = t2.ValueB OR (t1.ValueA IS NULL AND t2.ValueB IS NULL) THEN 'Match'
ELSE 'Mismatch'
END AS ComparisonResult_IncludingNulls
FROM
(SELECT ID, SomeColumn AS ValueA FROM SourceTable1) AS t1
FULL OUTER JOIN
(SELECT ID, AnotherColumn AS ValueB FROM SourceTable2) AS t2
ON
t1.ID = t2.ID;
Alternatively, COALESCE can substitute NULLs with a placeholder value for comparison:
SELECT
t1.ID,
t1.ValueA,
t2.ValueB,
CASE
WHEN COALESCE(t1.ValueA, 'NULL_PLACEHOLDER') = COALESCE(t2.ValueB, 'NULL_PLACEHOLDER') THEN 'Match'
ELSE 'Mismatch'
END AS ComparisonResult_Coalesce
FROM
(SELECT ID, SomeColumn AS ValueA FROM SourceTable1) AS t1
FULL OUTER JOIN
(SELECT ID, AnotherColumn AS ValueB FROM SourceTable2) AS t2
ON
t1.ID = t2.ID;
Comparing Multiple Columns Efficiently
When comparing many columns between two SELECT statements, explicitly listing all columns in a WHERE clause can become cumbersome. For such scenarios, functions like CHECKSUM or HASHBYTES can offer a more concise solution.
Using CHECKSUM or BINARY_CHECKSUM
These functions generate a hash value for a list of expressions. If the hash values are identical, it's highly probable that the underlying column values are also identical. While not 100% collision-proof (especially CHECKSUM), they are very efficient for broad comparisons.
SELECT
t1.ID
FROM
(SELECT ID, Col1, Col2, Col3 FROM TableA) AS t1
JOIN
(SELECT ID, ColA, ColB, ColC FROM TableB) AS t2
ON
t1.ID = t2.ID
WHERE
CHECKSUM(t1.Col1, t1.Col2, t1.Col3) <> CHECKSUM(t2.ColA, t2.ColB, t2.ColC);
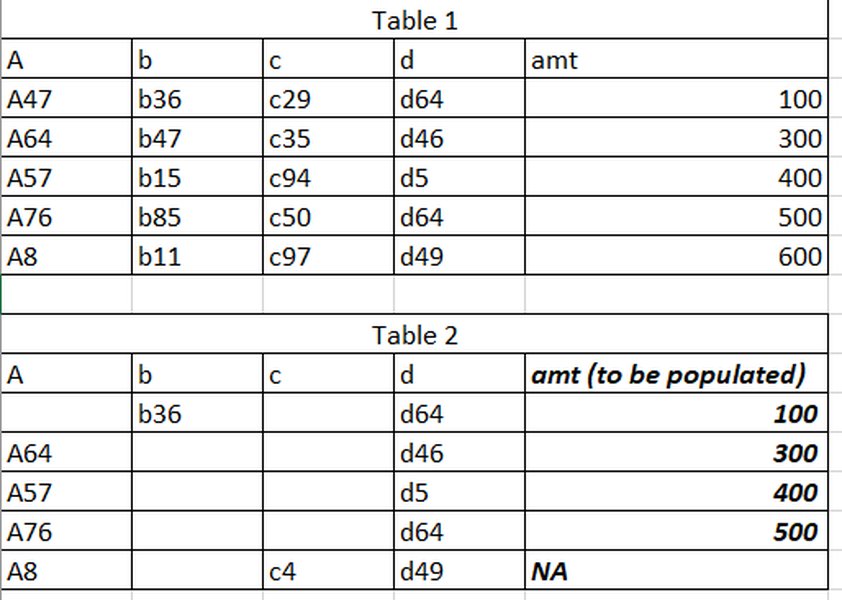
Example illustrating row-wise comparison of text columns across tables.
For more robust hashing with a lower chance of collisions, especially for large strings, HASHBYTES can be used with algorithms like SHA2_256 or SHA2_512.
SELECT
t1.ID
FROM
(SELECT ID, Col1, Col2 FROM TableA) AS t1
JOIN
(SELECT ID, ColA, ColB FROM TableB) AS t2
ON
t1.ID = t2.ID
WHERE
HASHBYTES('SHA2_256', CONCAT(t1.Col1, t1.Col2)) <> HASHBYTES('SHA2_256', CONCAT(t2.ColA, t2.ColB));
When using HASHBYTES, remember to convert column values to a string type (e.g., NVARCHAR(MAX)) before concatenating them to avoid data type conversion issues.
Visualizing Comparison Capabilities
To better understand the strengths and weaknesses of different comparison methods in SQL Server, consider this radar chart. It evaluates various techniques based on criteria like flexibility, performance, accuracy in handling NULLs, and ease of use.
This radar chart provides a quick overview. For instance, while EXCEPT and INTERSECT are excellent for identifying exact set differences and commonalities (high on "Identifying All Differences" and "Ease of Use"), they might be less flexible for highlighting specific column-level differences within matching rows (lower on "Flexibility"). HASHBYTES excels in "Performance" for many columns but requires careful handling of NULLs and has a minor risk of collisions, impacting "NULL Handling Accuracy" and "Identifying All Differences" if not handled properly. CASE statements offer superior "Flexibility" and "NULL Handling Accuracy" as they allow granular control over comparison logic but might be verbose for very large numbers of columns and could have moderate performance implications for huge datasets compared to hashing.
Practical Scenarios and Use Cases
Understanding when to apply each comparison technique is crucial. Here's a table summarizing common scenarios and the recommended SQL approach:
| Scenario | Comparison Goal | Recommended SQL Technique(s) | Key Considerations |
|---|---|---|---|
| Data Validation | Verify if data in a new table/view matches a source. | EXCEPT, INTERSECT, FULL OUTER JOIN with WHERE IS NULL clauses. |
Ensure primary keys for joining. Handle NULLs carefully. |
| Auditing Changes | Identify rows or columns that have been modified between two snapshots of data. | FULL OUTER JOIN + CASE statements, CHECKSUM/HASHBYTES. |
Requires a unique identifier for each row. Hashing is good for many columns. |
| Finding Duplicates | Locate identical rows within a single table or across two tables that should be distinct. | GROUP BY ... HAVING COUNT(*) > 1 (for single table), INNER JOIN or INTERSECT (across tables). |
Define what constitutes a "duplicate" (all columns, or a subset). |
| Data Migration Testing | Confirm all data from a source has been correctly migrated to a target. | EXCEPT (source minus target), EXCEPT (target minus source). |
Order and data types of columns must match perfectly. |
| Conditional Logic | Return a specific value or flag based on a comparison between columns. | CASE statement. |
Highly flexible for custom logic. Handles NULLs well with explicit checks. |
Diving Deeper: Visualizing SQL Comparisons
To further illustrate the practical application of these techniques, consider this video which provides a hands-on demonstration of comparing multiple columns in SQL. It covers common scenarios and helps solidify the concepts discussed.
This tutorial, "SQL Tutorial - How to compare multiple columns in SQL", offers a great visual explanation of comparing columns directly within the WHERE clause and using techniques like CHECKSUM. It complements the theoretical explanations by providing practical SQL examples, which are invaluable for understanding how these concepts translate into actionable queries. The video demonstrates how to set up queries for identifying differences and matches, providing a clearer picture of their utility in real-world database management tasks. It also touches upon performance considerations, which is a key aspect when dealing with large datasets and complex comparisons in SQL Server.
Frequently Asked Questions
INNER JOIN or a WHERE clause if the two SELECT statements can be joined on a common key, and then apply the equality operator (=) to the columns you wish to compare. For example, SELECT A.Col1, B.Col2 FROM (SELECT Col1 FROM Table1) A JOIN (SELECT Col2 FROM Table2) B ON A.ID = B.ID WHERE A.Col1 = B.Col2;
NULL values, use a FULL OUTER JOIN combined with a CASE statement that explicitly checks for NULLs. For instance, CASE WHEN t1.ColumnA = t2.ColumnB OR (t1.ColumnA IS NULL AND t2.ColumnB IS NULL) THEN 'Match' ELSE 'Mismatch' END. The COALESCE function can also be used to substitute NULLs with a non-NULL placeholder for comparison.
EXCEPT and INTERSECT. EXCEPT will show rows present in the first result set but not the second, while INTERSECT shows rows common to both. For these operators, both SELECT statements must have the same number of columns, and corresponding columns must have compatible data types.
CHECKSUM or HASHBYTES (with an appropriate algorithm like SHA2_256) on a concatenated string of all relevant columns can be highly performant. This reduces many column comparisons to a single hash value comparison.
Conclusion
Comparing columns from different SELECT statements in MS SQL Server is a cornerstone of data analysis and validation. By mastering various SQL techniques—from direct JOIN operations and powerful set operators to flexible CASE statements and efficient hashing functions—you can accurately identify similarities and differences across your datasets. The choice of method depends on the specific comparison goal, data characteristics (especially NULLs), and performance requirements for your particular scenario. A thoughtful approach to selecting the right technique will ensure data integrity and facilitate robust database management.
Recommended Further Exploration
- How to optimize SQL queries for large data comparisons?
- Understanding SQL Server's three-valued logic and NULL handling.
- Advanced uses of Common Table Expressions (CTEs) in SQL Server.
- What are the best schema comparison tools for SQL Server databases?