
Unveiling Discrepancies: A Deep Dive into Comparing SQL Query Results
Mastering the Art of Data Comparison Across Diverse SQL Selections
- Comprehensive Comparison Tools: SQL offers a rich set of operators like
UNION,EXCEPT, andINTERSECT, along with powerfulJOINclauses, to precisely identify differences between query results and table data. - Column-Specific Analysis: Techniques leveraging
FULL JOIN,CASEstatements, andIIFfunctions enable granular comparison of individual columns, highlighting mismatches while preserving shared data. - Beyond Data: Performance and Schema Comparison: Modern SQL Server Management Studio (SSMS) tools extend comparison capabilities to execution plans and database schemas, providing crucial insights for performance tuning and database consistency.
Comparing data between two different SELECT statements in SQL Server is a fundamental task for data validation, auditing, and debugging. Whether you're checking for data integrity, identifying changes between two versions of a dataset, or verifying the output of complex queries, SQL provides a robust set of tools and techniques to pinpoint discrepancies. This guide will explore various methods, from basic set operators to advanced column-by-column analysis and performance comparisons, ensuring you can effectively identify and present differences.
Fundamental Approaches to Comparing Query Results
At the heart of comparing two SELECT statements lies the concept of set operations. SQL provides specific operators that allow you to treat the results of queries as sets and find their common elements, unique elements, or differences.
Leveraging Set Operators: EXCEPT, INTERSECT, and UNION
The EXCEPT and INTERSECT operators are particularly powerful for identifying differences and commonalities between two query result sets. These operators require that the SELECT statements have the same number of columns, and the corresponding columns must have compatible data types and be in the same order.
EXCEPT: Finding Unique Rows in the First Query
The EXCEPT operator returns all distinct rows from the first SELECT statement that are not found in the second SELECT statement. This is ideal when you want to see what data exists in one result set but not the other.
SELECT Column1, Column2, Column3
FROM Query1_Result
EXCEPT
SELECT Column1, Column2, Column3
FROM Query2_Result;
Similarly, flipping the queries will show rows present in the second query but not the first:
SELECT Column1, Column2, Column3
FROM Query2_Result
EXCEPT
SELECT Column1, Column2, Column3
FROM Query1_Result;
Combining both EXCEPT operations with a UNION allows you to see all rows that are different in either query, regardless of which query they originated from:
SELECT * FROM (SELECT * FROM Query1_Result) AS Q1_Alias
EXCEPT
SELECT * FROM (SELECT * FROM Query2_Result) AS Q2_Alias
UNION ALL
SELECT * FROM (SELECT * FROM Query2_Result) AS Q2_Alias
EXCEPT
SELECT * FROM (SELECT * FROM Query1_Result) AS Q1_Alias;
This combined approach effectively highlights all rows that have any discrepancy between the two datasets.
INTERSECT: Identifying Common Rows
The INTERSECT operator returns all distinct rows that are present in both SELECT statements. While not directly showing differences, it's useful for understanding the overlapping data, which can then be contrasted with the EXCEPT results to get a full picture of all data points.
SELECT Column1, Column2, Column3
FROM Query1_Result
INTERSECT
SELECT Column1, Column2, Column3
FROM Query2_Result;
UNION/UNION ALL: Combining Results for Manual Review
The UNION operator combines the result sets of two or more SELECT statements and removes duplicate rows. UNION ALL also combines results but includes all duplicates. While not directly showing differences, you can use these to merge data for further analysis, especially when identifying rows that exist in one table but not the other, perhaps by adding a source identifier column.
Comparing Data with JOINs for Granular Differences
When you need to identify differences at a column level, or when the two result sets don't have a perfect one-to-one row correspondence, JOIN operations are essential. A FULL OUTER JOIN is particularly useful for this, as it returns all rows from both tables, matching them where possible and showing NULL where no match exists.
Using FULL OUTER JOIN to Pinpoint Discrepancies
By performing a FULL OUTER JOIN on a common primary key or a unique set of columns, you can then use WHERE clauses to filter for rows where specific columns differ. This method allows you to see both the original and the differing values side-by-side.
SELECT
ISNULL(T1.ID, T2.ID) AS CommonID,
T1.ColumnA AS Query1_ColumnA,
T2.ColumnA AS Query2_ColumnA,
CASE WHEN T1.ColumnA <> T2.ColumnA THEN 'DIFFERENT' ELSE 'MATCH' END AS ColumnA_Status,
T1.ColumnB AS Query1_ColumnB,
T2.ColumnB AS Query2_ColumnB,
CASE WHEN T1.ColumnB <> T2.ColumnB THEN 'DIFFERENT' ELSE 'MATCH' END AS ColumnB_Status
FROM
(SELECT ID, ColumnA, ColumnB FROM Table1) AS T1
FULL OUTER JOIN
(SELECT ID, ColumnA, ColumnB FROM Table2) AS T2
ON
T1.ID = T2.ID
WHERE
T1.ColumnA <> T2.ColumnA OR T1.ColumnB <> T2.ColumnB
OR T1.ID IS NULL OR T2.ID IS NULL; -- Catches rows unique to either table
This approach gives you a detailed report of exactly which columns have changed for a given row and whether a row is entirely new or missing. For handling NULL values in comparisons, using IS DISTINCT FROM (if supported by your SQL version) or (T1.ColumnA IS NULL AND T2.ColumnA IS NOT NULL) OR (T1.ColumnA IS NOT NULL AND T2.ColumnA IS NULL) OR (T1.ColumnA <> T2.ColumnA) is crucial, as NULL <> NULL evaluates to UNKNOWN and can filter out actual differences where one or both values are NULL.
Highlighting Differences with IIF or CASE Statements
To explicitly show discrepancies, you can employ IIF (Immediate IF) or CASE statements within your SELECT clause. This allows you to add a new column that indicates "Match" or "Difference" for each compared column.
SELECT
Q1.PrimaryKey,
Q1.ValueColumn,
Q2.ValueColumn,
IIF(Q1.ValueColumn = Q2.ValueColumn, 'Match', 'Mismatch') AS ComparisonStatus
FROM
Query1_Result Q1
JOIN
Query2_Result Q2 ON Q1.PrimaryKey = Q2.PrimaryKey
WHERE
Q1.ValueColumn <> Q2.ValueColumn;
For more complex scenarios, especially with multiple columns, CASE statements offer greater flexibility:
SELECT
COALESCE(T1.ID, T2.ID) AS ID,
T1.Name AS OldName,
T2.Name AS NewName,
CASE
WHEN T1.Name <> T2.Name THEN 'Name Changed'
WHEN T1.Name IS NULL AND T2.Name IS NOT NULL THEN 'Name Added'
WHEN T1.Name IS NOT NULL AND T2.Name IS NULL THEN 'Name Removed'
ELSE 'Name Match'
END AS NameDiff,
T1.Value AS OldValue,
T2.Value AS NewValue,
CASE
WHEN T1.Value <> T2.Value THEN 'Value Changed'
WHEN T1.Value IS NULL AND T2.Value IS NOT NULL THEN 'Value Added'
WHEN T1.Value IS NOT NULL AND T2.Value IS NULL THEN 'Value Removed'
ELSE 'Value Match'
END AS ValueDiff
FROM
TableA T1
FULL OUTER JOIN
TableB T2 ON T1.ID = T2.ID
WHERE
NOT (T1.Name = T2.Name OR (T1.Name IS NULL AND T2.Name IS NULL))
OR NOT (T1.Value = T2.Value OR (T1.Value IS NULL AND T2.Value IS NULL));
Visualizing Comparison Techniques
To better understand the strengths of different SQL comparison techniques, let's consider a radar chart. This chart will illustrate how various methods excel in different aspects of comparison, such as ease of implementation, ability to show specific column differences, performance for large datasets, and handling of NULLs.
Comparative Analysis of SQL Comparison Techniques
As the chart indicates, EXCEPT/INTERSECT are excellent for overall row differences and performance, but they lack the detail of pinpointing individual column changes. FULL OUTER JOIN with CASE/IIF shines in providing granular column-level differences and robust NULL handling, making it highly versatile for complex data validation. While CHECKSUM_AGG is fast for row-level equality checks, it doesn't tell you *what* changed, and its NULL handling can be a drawback.
Advanced Comparison Scenarios
Beyond basic data comparison, SQL Server offers features and tools to analyze and compare database objects and query performance.
Comparing Execution Plans for Performance Analysis
When two queries return the same results but one is performing poorly, comparing their execution plans is critical. SQL Server Management Studio (SSMS) provides a graphical execution plan comparison feature that visually highlights differences in operations, costs, and indexing strategies.
Comparing Execution Plans in SQL Server Management Studio
This feature allows you to load two `.sqlplan` files or compare an active plan against a saved one. It helps identify bottlenecks, missing indexes, or suboptimal join orders that might be causing performance disparities. The plan comparison tool highlights sections that are different, enabling a quick visual assessment of the changes in query execution strategy.
Understanding and Using SQL Server Management Studio to Compare Plans
The video above provides a concise overview of how to effectively use SQL Server Management Studio's execution plan comparison feature. This tool is invaluable for database administrators and developers who need to optimize query performance by dissecting the underlying operations and costs associated with different SQL statements. By visually identifying divergences in execution strategies, such as variations in index usage, join types, or data access patterns, users can quickly pinpoint the root causes of performance differences. This helps in making informed decisions for query tuning and ensuring efficient database operations.
Database Schema and Data Comparison Tools
For more extensive comparisons, especially between entire databases or large tables, specialized tools are often employed. These tools go beyond simple query result comparisons and can identify differences in schema (tables, views, stored procedures, indexes) and data across multiple databases or instances.
Third-Party Tools and SSDT
Tools like dbForge Schema Compare & Data Compare, Red Gate SQL Compare, and ApexSQL Diff are designed for robust schema and data comparison. SQL Server Data Tools (SSDT) in Visual Studio also provides schema compare functionality, which can compare a database project with a live database or two database projects.
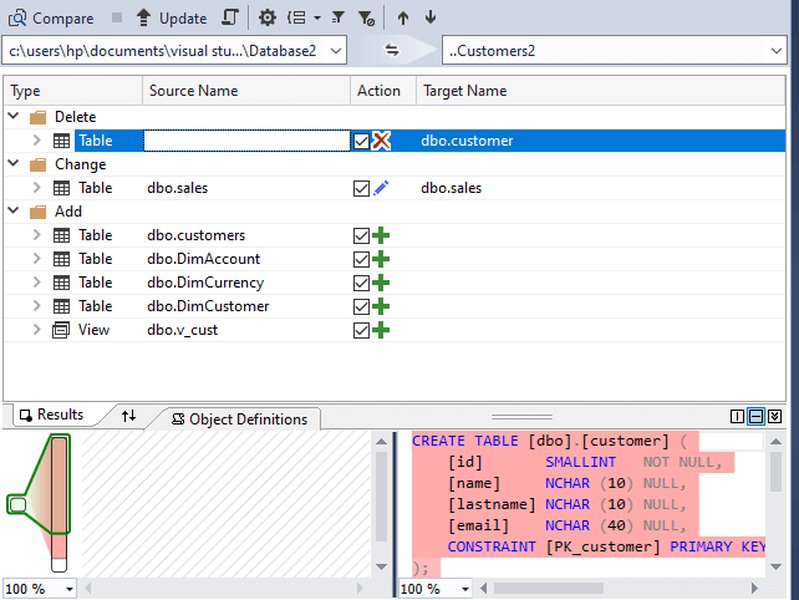
Schema Comparison in SQL Server Data Tools (SSDT)
These tools are particularly useful for migration validation, synchronization, and ensuring consistency across development, testing, and production environments. They often provide intuitive interfaces to highlight differences and generate synchronization scripts.
Summary of Comparison Techniques
Here's a table summarizing the main techniques for comparing SQL query results and their applications:
| Technique | Description | Best For | Pros | Cons |
|---|---|---|---|---|
EXCEPT |
Returns rows present in Query A but not in Query B. | Identifying rows unique to one dataset. | Simple syntax, good performance for distinct row differences. | Doesn't show column-level differences; strict column compatibility required. |
INTERSECT |
Returns rows present in both Query A and Query B. | Identifying common rows between two datasets. | Straightforward, good for confirming identical data. | Doesn't directly show differences; strict column compatibility required. |
FULL OUTER JOIN with CASE/IIF |
Combines rows from both queries and uses conditional logic to highlight column discrepancies. | Detailed column-level difference reporting, handling missing/new rows. | Granular control, shows specific column changes, excellent NULL handling. | More complex SQL, potentially slower on very large datasets without proper indexing. |
NOT EXISTS / LEFT JOIN IS NULL |
Identifies rows in one query that do not have a match in another. | Finding rows that are exclusively in one result set. | Efficient for identifying missing or added rows. | Doesn't show column-level differences for matching rows. |
CHECKSUM_AGG / BINARY_CHECKSUM |
Generates a checksum for rows/columns, allowing for quick comparison of large datasets. | Quickly checking if entire rows or tables are identical. | Very fast for large datasets. | Does not indicate *what* changed; sensitive to data type changes; `NULL` handling can be tricky. |
| SQL Server Management Studio (SSMS) Plan Comparison | Graphical tool to compare execution plans of two queries. | Performance tuning, optimizing query execution. | Visual and detailed insight into query performance differences. | Requires SSMS, focuses on execution strategy not data content. |
| Third-Party Schema/Data Comparison Tools | Dedicated applications for comparing entire database schemas and data. | Database migrations, synchronization, auditing, large-scale data validation. | Comprehensive, generates sync scripts, handles complex scenarios. | Often requires licensing, external tool dependency. |
Frequently Asked Questions (FAQ)
Conclusion
Comparing SQL query results and identifying differences is a multifaceted task with various solutions tailored to different needs. From simple row-level distinctions using `EXCEPT` and `INTERSECT` to detailed column-by-column analysis with `FULL OUTER JOIN` and conditional logic, SQL provides the flexibility to achieve precise comparisons. Beyond data, tools within SQL Server Management Studio and third-party applications extend comparison capabilities to execution plans and entire database schemas, empowering developers and DBAs to maintain data integrity, optimize performance, and ensure database consistency. By understanding and applying these techniques, you can confidently navigate data discrepancies and gain deeper insights into your SQL Server environment.
Recommended Further Exploration
- How to optimize SQL queries for performance?
- Explore advanced features of SQL Server Management Studio for database management.
- Discover techniques for robust data validation and auditing in SQL Server environments.
- Learn more about understanding and interpreting SQL Server execution plans for query tuning.