
Understanding CUDA: A Comprehensive Guide
Unlocking the Power of NVIDIA GPUs for High-Performance Computing
Key Takeaways
- Parallel Processing Power: Harnesses thousands of GPU cores to accelerate complex computations.
- Versatile Programming Model: Extends familiar programming languages, enabling seamless integration with CPU tasks.
- Wide Application Spectrum: Essential in fields ranging from artificial intelligence to scientific simulations.
Introduction to CUDA
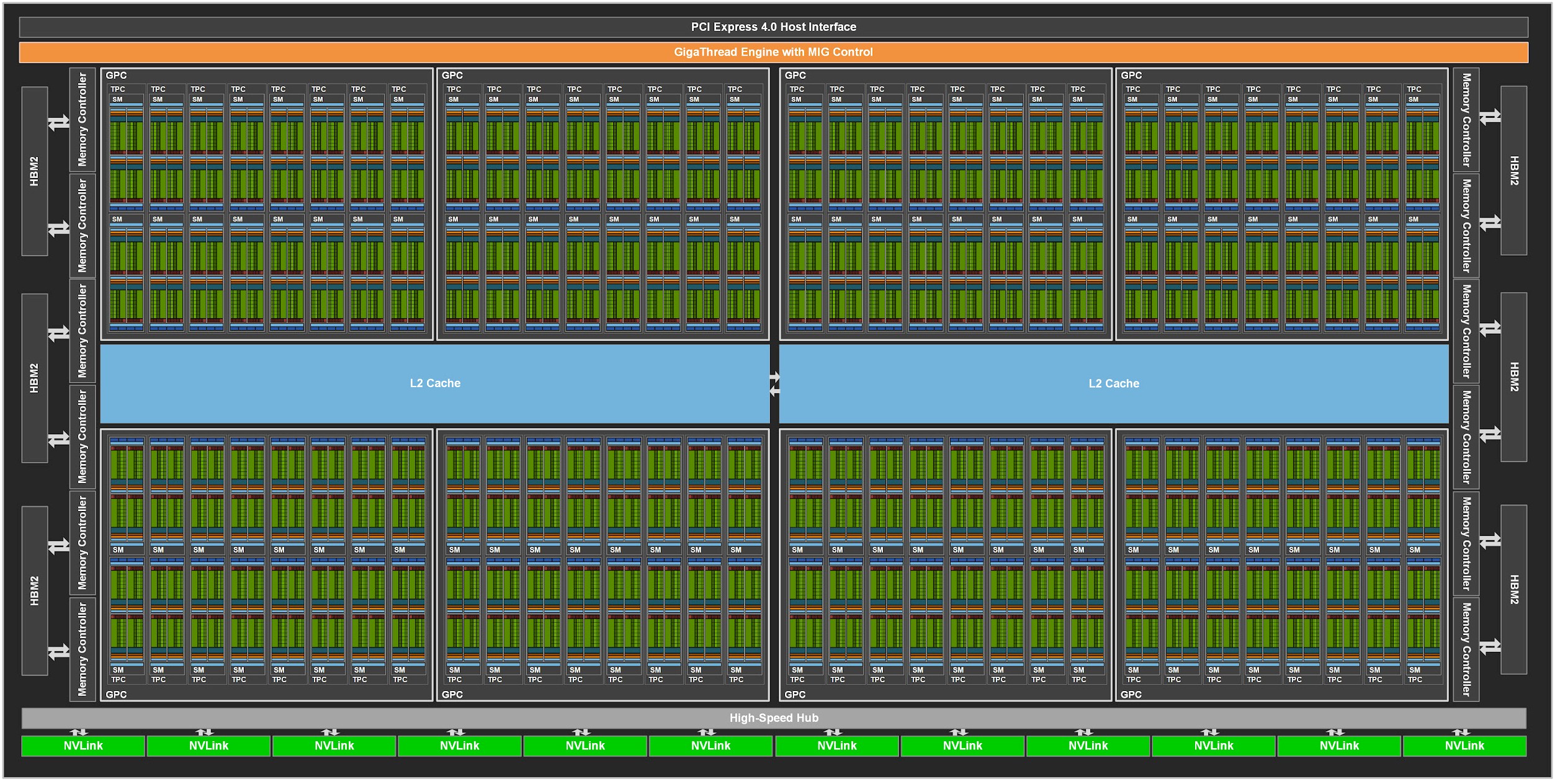
CUDA, an acronym for Compute Unified Device Architecture, is a parallel computing platform and application programming interface (API) model developed by NVIDIA. Introduced in 2006, CUDA revolutionized general-purpose computing on graphics processing units (GPGPU), allowing developers to leverage the massive parallel processing capabilities of NVIDIA GPUs for tasks beyond traditional graphics rendering.
The Evolution of CUDA
CUDA was created to bridge the gap between the high computational power of GPUs and the demands of modern computing applications. Prior to CUDA, programming GPUs for non-graphics tasks was complex and limited. CUDA introduced a more accessible and efficient programming model, enabling a wide range of industries to adopt GPU acceleration for various computational tasks.
Core Components of CUDA
CUDA Hardware and Drivers
The foundation of CUDA lies in its integration with NVIDIA GPUs. CUDA-compatible GPUs are equipped with thousands of cores optimized for parallel operations. The CUDA hardware driver is responsible for managing communication between the operating system and the GPU, ensuring efficient task execution and resource allocation.
CUDA API and Runtime
CUDA extends popular programming languages such as C, C++, Fortran, Python, and MATLAB by introducing parallel programming capabilities. The CUDA API provides developers with functions and tools to manage GPU resources, launch parallel kernels, and handle data transfers between the CPU and GPU. The runtime environment ensures that CUDA applications can efficiently execute across different platforms, from embedded systems to cloud-based infrastructures.
Optimized Mathematical Libraries
To facilitate high-performance computing, CUDA offers a suite of optimized mathematical libraries, including cuBLAS for linear algebra, cuFFT for fast Fourier transforms, and cuDNN for deep neural networks. These libraries are fine-tuned to exploit the parallel architecture of NVIDIA GPUs, providing out-of-the-box performance enhancements for a variety of computational tasks.
CUDA Programming Model
Thread-Level Parallelism
At the heart of CUDA's programming model is the concept of thread-level parallelism. CUDA allows developers to execute thousands of threads concurrently, enabling the simultaneous processing of large data sets. Threads are organized into blocks and grids, which map efficiently onto the GPU’s architecture, ensuring optimal utilization of resources.
Kernels and Memory Management
Kernels are specialized functions written to run on the GPU. When a kernel is launched, multiple instances of it execute in parallel, each handling different portions of the data. Efficient memory management is crucial in CUDA programming, as transferring data between the CPU and GPU can become a bottleneck. CUDA provides various memory spaces, such as global, shared, and local memory, each with different access speeds and scopes, allowing developers to optimize memory usage for their specific applications.
Applications of CUDA
Artificial Intelligence and Machine Learning
CUDA plays a pivotal role in the development and deployment of artificial intelligence (AI) and machine learning (ML) models. Frameworks like TensorFlow and PyTorch leverage CUDA to accelerate the training and inference phases of neural networks, significantly reducing the time required to develop sophisticated AI applications.
Scientific Computing and Simulations
In fields such as physics, chemistry, and biology, CUDA enables the simulation of complex systems and phenomena that would be computationally prohibitive using traditional CPU-based methods. From molecular dynamics to climate modeling, CUDA accelerates simulations by parallelizing calculations across GPU cores.
Image and Video Processing
CUDA enhances real-time image and video processing tasks, including rendering, encoding, decoding, and computer vision. Its ability to handle large volumes of data in parallel makes it indispensable for applications like autonomous driving, augmented reality, and video streaming services.
Financial Analysis and Data Mining
In the financial sector, CUDA accelerates quantitative analysis, risk assessment, and data mining operations. The parallel processing capabilities of GPUs enable faster computation of complex algorithms, facilitating real-time data analysis and decision-making.
CUDA Ecosystem and Tools
CUDA Toolkit
The CUDA Toolkit is an essential suite of development tools that includes compilers, libraries, and debuggers tailored for CUDA programming. It provides an integrated environment for developing, optimizing, and deploying CUDA applications across various platforms and NVIDIA hardware.
Development Environments
CUDA supports a range of development environments and integrated development environments (IDEs), such as NVIDIA Nsight, Visual Studio, and Eclipse. These tools offer features like code profiling, performance analysis, and debugging, streamlining the development process and enhancing productivity.
Community and Support
NVIDIA fosters a robust developer community, offering extensive documentation, tutorials, forums, and support channels. This community-driven approach ensures that developers can access the resources and assistance needed to effectively utilize CUDA in their projects.
Performance Optimization in CUDA
Memory Hierarchy Optimization
Optimizing memory access patterns is crucial for achieving high performance in CUDA applications. By effectively utilizing different memory hierarchies, such as shared memory and caches, developers can minimize latency and maximize data throughput. Techniques like memory coalescing and avoiding bank conflicts are common strategies for enhancing memory performance.
Parallelism and Load Balancing
Effective parallelization involves distributing workloads evenly across GPU cores to prevent bottlenecks and ensure all cores are utilized efficiently. Load balancing techniques, such as dynamic scheduling and task partitioning, help achieve optimal performance by balancing the computational load among available resources.
Kernel Fusion and Minimization of Divergence
Kernel fusion combines multiple small kernels into a single larger kernel to reduce overhead and improve cache utilization. Additionally, minimizing thread divergence within warps—groups of threads executing the same instruction—ensures that GPU cores operate efficiently without unnecessary branching.
CUDA in the Industry
Healthcare and Biomedical Research
In healthcare, CUDA accelerates medical imaging, genomic sequencing, and drug discovery processes. High-throughput data analysis and real-time processing capabilities enable breakthroughs in diagnostic tools and personalized medicine.
Autonomous Vehicles
CUDA powers the computation-intensive algorithms required for sensor data processing, object detection, and path planning in autonomous vehicles. The ability to process vast amounts of data in real-time is essential for the safe and efficient operation of self-driving cars.
Entertainment and Media
The entertainment industry leverages CUDA for high-fidelity rendering, special effects, and real-time video processing. From blockbuster movies to virtual reality experiences, CUDA enhances the visual quality and interactivity of multimedia content.
Future of CUDA
Advancements in GPU Architecture
NVIDIA continues to innovate GPU architectures, increasing the number of cores, memory bandwidth, and energy efficiency. These advancements will further enhance CUDA's capabilities, enabling even more complex and resource-intensive applications to benefit from GPU acceleration.
Integration with Emerging Technologies
CUDA is poised to integrate with emerging technologies such as quantum computing, edge computing, and 5G networks. These integrations will expand the horizons of high-performance computing, enabling new applications and solutions across various domains.
Enhanced Software Ecosystem
The CUDA software ecosystem will continue to evolve, offering more sophisticated tools, libraries, and frameworks. Improvements in compiler technology, debugging tools, and performance optimization techniques will make CUDA even more accessible and powerful for developers.
Technical Workflow of CUDA Applications
1. Kernel Development
Developers write parallel functions, known as kernels, in CUDA C/C++ or other supported languages. These kernels define the operations to be performed concurrently on the GPU cores.
2. Data Transfer
Data required for computation is transferred from the CPU (host) memory to the GPU (device) memory. Efficient data management is critical to minimize transfer times and maximize performance.
3. Kernel Execution
The developed kernels are launched on the GPU cores. Threads are organized into blocks and grids, which map to the GPU’s architecture, allowing for scalable and efficient parallel execution of tasks.
4. Result Retrieval
After computation, the processed data is transferred back from the GPU to the CPU memory. This data can then be utilized by the application or further processed as needed.
Comparison of CUDA with Other Parallel Computing Platforms
| Feature | CUDA | OpenCL | HIP |
|---|---|---|---|
| Developer | NVIDIA | Khronos Group | AMD |
| Language Support | C, C++, Fortran, Python, MATLAB | C, C++, Python | C++, Python |
| Ecosystem | Extensive with proprietary libraries | Open standard libraries | Compatible with CUDA and OpenCL |
| Performance | Highly optimized for NVIDIA GPUs | More generic, potentially less optimized | Optimized for AMD GPUs, can translate CUDA code |
| Hardware Dependency | NVIDIA GPUs only | Multiple vendors | AMD GPUs primarily, with CUDA compatibility |
Advantages of Using CUDA
Unmatched Performance
CUDA provides unparalleled performance in parallel processing tasks, leveraging the full potential of NVIDIA GPUs. Its ability to handle thousands of threads simultaneously makes it ideal for computation-intensive applications.
Comprehensive Toolset
The CUDA Toolkit offers a wide array of tools, including compilers, debuggers, and profilers, which streamline the development process and enhance the performance tuning of applications.
Strong Community and Support
NVIDIA’s active developer community and extensive documentation ensure that developers have access to the resources and support necessary to effectively utilize CUDA in their projects.
Scalability
CUDA applications can scale across a range of platforms, from individual workstations to large-scale data centers and supercomputers, providing flexibility in deployment and scalability to meet growing computational demands.
Challenges and Considerations
Hardware Dependency
CUDA is proprietary to NVIDIA GPUs, which means applications built with CUDA are tied to NVIDIA hardware. This limitation can be a constraint in environments where diverse or non-NVIDIA hardware is prevalent.
Learning Curve
While CUDA offers powerful parallel programming capabilities, it introduces complexity that requires developers to have a solid understanding of parallel computing concepts and GPU architecture to optimize performance effectively.
Resource Management
Effective management of GPU resources, memory allocation, and data transfer between CPU and GPU is critical to avoid bottlenecks and ensure optimal application performance. This requires careful design and optimization strategies.
Getting Started with CUDA
Setting Up the Development Environment
To begin developing CUDA applications, developers need to install the CUDA Toolkit, which includes the necessary compilers, libraries, and tools. Compatible NVIDIA drivers must also be installed to ensure proper communication between the system and the GPU.
Writing Your First CUDA Program
A typical CUDA program involves writing a kernel function that executes on the GPU and a host function that runs on the CPU. Here’s a simple example of vector addition using CUDA:
// Kernel function to add two vectors
__global__ void vectorAdd(float *A, float *B, float *C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main() {
int N = 1000;
size_t size = N * sizeof(float);
// Allocate memory on host
float *h_A = (float*)malloc(size);
float *h_B = (float*)malloc(size);
float *h_C = (float*)malloc(size);
// Initialize vectors
for(int i = 0; i < N; i++) {
h_A[i] = i;
h_B[i] = i * 2;
}
// Allocate memory on device
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
// Copy data from host to device
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Define block and grid sizes
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// Launch kernel
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// Copy result back to host
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Cleanup
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
free(h_A);
free(h_B);
free(h_C);
return 0;
}
Compiling and Running CUDA Programs
CUDA programs are compiled using the NVIDIA CUDA Compiler (nvcc). To compile the above example, use the following command:
nvcc -o vectorAdd vectorAdd.cu
After compilation, the executable can be run to perform vector addition using the GPU.
Best Practices for CUDA Development
Maximize Parallelism
Design applications to exploit the full parallel processing capabilities of GPUs. Break down tasks into smaller, independent operations that can be executed concurrently.
Optimize Memory Access Patterns
Ensure efficient memory access by coalescing memory transactions and minimizing divergent memory accesses. Utilize shared memory where appropriate to reduce latency and improve throughput.
Minimize Data Transfer Overhead
Reduce the frequency and volume of data transfers between the CPU and GPU. Where possible, keep data on the GPU for the duration of the computation to minimize transfer times.
Profile and Benchmark
Use profiling tools provided by the CUDA Toolkit to identify bottlenecks and optimize performance. Regular benchmarking helps in assessing the impact of optimization strategies and ensuring that performance goals are met.
Conclusion
CUDA stands as a transformative platform in the realm of high-performance computing, enabling developers to harness the unparalleled parallel processing power of NVIDIA GPUs. Its robust programming model, extensive ecosystem, and wide-ranging applications make it an indispensable tool across various industries, from artificial intelligence and scientific research to entertainment and finance. As GPU architectures continue to evolve and integrate with emerging technologies, CUDA's role in driving computational advancements is set to expand further, fostering innovation and solving increasingly complex challenges.
References
Last updated February 5, 2025