
Comprehensive Guide to Data Engineering
Bridging the Gap from Data Science to Data Engineering Mastery
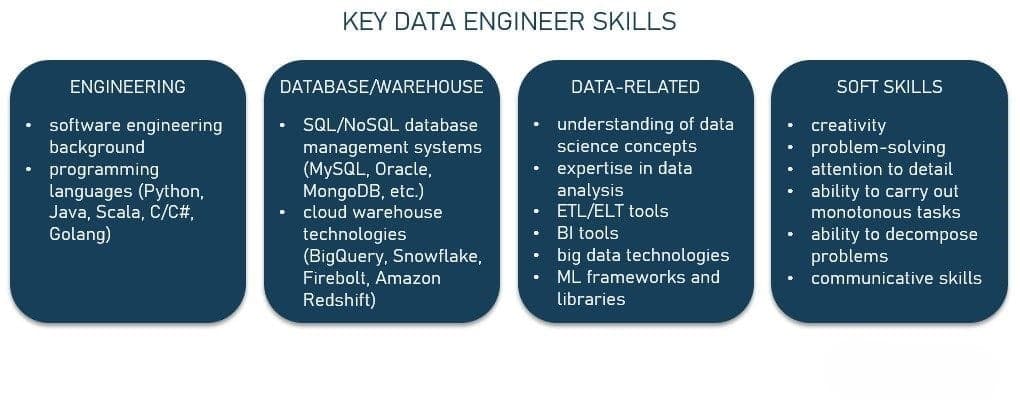
Key Highlights
- Deep Dive into Core Concepts: Explore data warehousing, ETL processes, data pipelines, and data modeling with detailed technical explanations.
- Comprehensive Technical Framework: Transition from Python and SQL expertise to mastering cloud platforms, big data technologies, and container orchestration.
- Practical Guidance: Emphasis on hands-on practice and project-based learning integrated with best practices and real-world architectural decisions.
1. Understanding Data Engineering Fundamentals
1.1. What is Data Engineering?
Data engineering is the discipline of building and maintaining the infrastructure that supports data collection, storage, processing, and analysis. It is the backbone that enables data science by ensuring that data flows reliably and efficiently from diverse sources to data storage systems and finally into analytics platforms.
While data science focuses on extracting insights and building models, data engineering is responsible for setting up robust systems and pipelines that handle large-scale data operations. This involves the design and development of architectures, data models, data warehouses, ETL processes, and real-time data pipelines.
1.2. The Lifecycle of Data Engineering
1.2.1. Data Ingestion
Data ingestion is the first step in the data engineering lifecycle. It involves gathering data from various sources, which can include databases, web APIs, log files, sensors, and more. Technologies and protocols vary greatly depending on the source:
- Batch ingestion: Data is collected over a period and processed together, which is useful when real-time processing is not critical.
- Streaming ingestion: Data is processed in real time upon generation, essential for real-time analytics and monitoring applications.
The goal is to ensure that data reaches the appropriate systems reliably, and in a format suitable for subsequent stages of processing.
1.2.2. Data Integration
After ingesting data, the next step is integration. Data integration involves combining data from multiple sources to create a unified and consistent view. This critical process includes:
- Combining Data Formats: Data might come in structured, semi-structured, or unstructured forms.
- Resolving Data Conflicts: Differences in data structure, naming conventions, or formats need to be resolved to ensure consistency.
- Data Merging: Integrating datasets across different systems to support comprehensive analytics, often performed through robust ETL processes.
1.2.3. Data Transformation
Data transformation converts raw, ingested data into a clean, organized, and analytical format. This step is crucial since raw data is often inconsistent or contains noise that can lead to errors in analysis and reporting.
Transformation processes include:
- Cleaning: Removing duplicates, handling missing values, and correcting inconsistencies.
- Normalization: Structuring data to reduce redundancy and improve integrity.
- Data Aggregation: Summarizing information to reduce complexity for analysis.
- Formatting: Ensuring that data types and structures satisfy analytical requirements.
1.2.4. Data Storage
The final stage of the initial data lifecycle involves storing the transformed data in appropriate repositories. Data storage can take on different forms:
- Data Warehouses: Optimized for analytic queries, data warehouses store structured historical data and support business intelligence tools.
- Data Lakes: They allow storage of raw, unstructured, or semi-structured data, offering more flexibility for future analysis or data discovery.
- Databases: Relational (SQL) and non-relational (NoSQL) databases are selected based on the type of data and performance requirements.
2. Diving Deeper into Core Concepts
2.1. Data Modeling
Data modeling is the process of designing a blueprint of how data is stored in a system. It involves creating visual representations (such as entity-relationship diagrams) that outline the structure, relationships, and constraints of the data.
Types of Data Models:
- Conceptual Model: Provides a high-level understanding of the overall structure without getting into details of implementation. It communicates the overall organization and relationships among data entities to stakeholders.
- Logical Model: Offers detailed relationships, key attributes, and logical grouping while remaining technology-agnostic. It defines the rules and constraints that govern data.
- Physical Model: Represents the actual implementation of the data in databases, focusing on performance, indexing, and storage details.
Detailed data modeling not only aids in efficient data storage but also ensures data integrity and optimizes query performance.
2.2. Data Warehousing
Data warehousing is central to modern analytics and business intelligence. A data warehouse consolidates data from various sources into one repository, designed to support complex queries and analysis.
2.2.1. Importance of Data Warehousing
Data warehouses integrate disparate data sources, providing a single, reliable foundation for data analytics. They support sophisticated queries, trend analysis, and historical reporting which are essential for strategic decision making.
2.2.2. Dimensional Modeling and Schemas
Key to data warehouse design is dimensional modeling, which often employs:
- Star Schema: Consists of a central fact table linked directly to dimension tables, simplifying data structures and promoting efficient query performance.
- Snowflake Schema: An extension of the star schema, where dimension tables are normalized into multiple related tables. This can reduce redundancy but may add complexity to queries.
This design facilitates efficient Online Analytical Processing (OLAP) whereby analytical queries run fast and yield informative insights on historical trends.
2.3. ETL Processes: Extract, Transform, Load
ETL is the backbone of data engineering processes that encompass:
2.3.1. Extract
The extraction phase involves retrieving data from various sources. This step must consider data format variability and the reliability of data sources. Whether it is legacy systems, modern APIs, or streaming data, the extraction process ensures that raw data is captured accurately.
2.3.2. Transform
Transformation is where raw data is converted into a usable format. This involves cleaning the data, applying business logic, aggregating values, and changing data types as needed to prepare for analysis. It is essential because:
- Data Quality: Ensures that inaccurate or incomplete records are corrected or removed.
- Consistency: Standardizes data formats and units across disparate sources.
- Efficiency: Reduces data volume by summarizing information, making it more efficient for downstream processing.
2.3.3. Load
Loading is the process of inserting transformed data into target repositories such as data warehouses or lakes. Performance and reliability are key at this stage, as data integrity must be maintained during transfer. Automated pipelines and scheduling systems that ensure consistency and timely updates are essential to maintain data freshness.
2.4. Data Pipelines and Real-Time Processing
Data pipelines refer to the end-to-end flow of data from source to target systems. The steps within a pipeline often encompass extraction, transformation, and load procedures as explained above. However, pipelines also integrate monitoring, error handling, and data validation practices to maintain high data quality.
Two major types are typically used:
- Batch Processing Pipelines: Process data in large chunks on a scheduled basis (like nightly builds or hourly jobs), ideal for scenarios where immediate data availability is not critical.
- Stream Processing Pipelines: Handle data in real time as it is generated, which is vital for time-sensitive applications such as monitoring systems, live dashboards, and fraud detection systems. Technologies supporting these pipelines include Apache Kafka, Apache Flink, and Spark Streaming.
3. Database Technologies and Data Storage Approaches
3.1. Relational vs. NoSQL Databases
A robust data engineer must understand the trade-offs between relational and NoSQL databases:
- Relational Databases (SQL): These databases structure data into tables with defined schemas. They excel in transactional systems (OLTP) and support complex joins, making them ideal for structured data requirements. Examples include PostgreSQL, MySQL, and Microsoft SQL Server.
- NoSQL Databases: Designed for flexibility, these databases can manage unstructured or semi-structured data. They provide horizontal scalability and high performance for large volumes of data. Examples include MongoDB, Cassandra, and Redis.
3.2. Table: Comparison of Database Technologies
| Feature | Relational Databases | NoSQL Databases |
|---|---|---|
| Data Structure | Tabular with strict schemas | Flexible schemas; document, key-value, wide-column, or graph |
| Scalability | Vertical scaling | Horizontal scaling |
| Transaction Support | ACID compliant | Eventual consistency; some support ACID |
| Use Cases | OLTP, complex queries and joins | Big data, real-time analytics, flexible data models |
4. Big Data Technologies and Cloud Data Engineering
4.1. Big Data Technologies
Mastery of big data tools is essential since they enable processing and analytics over extremely large datasets.
4.1.1. Apache Spark
Apache Spark is a unified analytics engine known for its speed and ease of use. It supports diverse workloads ranging from batch processing to machine learning and real-time stream processing. Spark’s in-memory computing capabilities enable faster data processing compared to traditional disk-based systems.
4.1.2. Hadoop Ecosystem
Hadoop provides a distributed framework for storing and processing large datasets. It primarily consists of:
- HDFS: A distributed file system that stores data across multiple nodes ensuring scalability and fault tolerance.
- MapReduce: A programming model for parallel processing of large data sets.
- YARN: Resource management that schedules and executes jobs on clusters.
Although newer technologies like Spark have emerged, Hadoop remains fundamental in many legacy systems and large-scale environments.
4.2. Cloud Data Engineering
Cloud platforms have revolutionized data engineering by offering scalable, flexible, and cost-effective infrastructures for managing massive amounts of data. Transitioning into cloud data engineering involves understanding both the architectural and operational differences compared to traditional on-premise solutions.
4.2.1. Major Cloud Providers and Their Offerings
- AWS: Key services include Amazon S3 for storage, Amazon Redshift for data warehousing, and EMR for big data processing.
- Google Cloud Platform (GCP): BigQuery serves as a serverless data warehouse, while Cloud Storage and Dataproc support various data engineering tasks.
- Microsoft Azure: Offers Azure Blob Storage, Azure Synapse Analytics, and Azure Databricks that cater to different data processing needs.
4.2.2. Containerization and Orchestration
In today’s dynamic production environments, tools like Docker and Kubernetes are indispensable. Containerization with Docker encapsulates applications in a consistent environment, while Kubernetes manages container orchestration, ensuring scalable, resilient, and efficient deployments of microservices and data processing tasks.
4.2.3. Infrastructure as Code (IaC)
Embracing IaC using tools like Terraform enables you to programmatically manage and provision your infrastructure. This practice ensures consistency across environments, reduces manual errors, and facilitates version control in your infrastructure setup.
5. Data Quality, Governance, and Best Practices
5.1. Data Quality and Validation
Ensuring high data quality is non-negotiable in data engineering. It involves implementing stringent data validation and cleansing procedures to guarantee that subsequent analytics and decision-making are grounded on reliable data. Key considerations include:
- Accuracy: Validating that data precisely represents real-world conditions.
- Completeness: Making sure no essential data is missing.
- Consistency: Ensuring uniformity of data across multiple sources.
- Timeliness: Keeping data updated so that it reflects current states.
5.2. Data Governance
Data governance is the framework of policies and standards that ensures data is used properly, securely, and in compliance with regulations. Effective data governance practices involve:
- Access Controls: Defining who can view or modify data.
- Data Auditing: Monitoring data usage and changes to maintain accountability.
- Compliance: Ensuring adherence to regulatory frameworks like GDPR or HIPAA.
5.3. Documentation and Collaboration
An often overlooked but essential part of data engineering is thorough documentation. Documenting data pipelines, data models, and architecture helps not only in maintenance but also in onboarding team members. Leveraging version control systems (e.g., Git) alongside continuous integration/continuous deployment (CI/CD) practices enhances collaboration and improves project outcomes.
6. Practical Experience and Hands-On Projects
6.1. Building Your Own Data Pipelines
Theoretical knowledge is crucial, but nothing matches hands-on experience. Start with small projects and gradually work on more complex end-to-end systems:
- Project Ideas: Set up a data pipeline that extracts data from a public API, transforms it (cleaning and aggregation), and loads it into a cloud-based data warehouse.
- Tools to Explore: Apache Airflow for orchestrating pipelines, Apache Kafka for handling real-time data streams, and Spark for batch and stream processing.
- Experimentation: Experiment with different ETL tools, and compare the performance of batch versus streaming pipelines.
6.2. Incorporating Big Data and Cloud Technologies
Leverage your knowledge of Python and SQL to interact with advanced technologies. For instance, design a pipeline that integrates Apache Spark on a cloud platform, utilizing Spark’s DataFrame API to perform complex transformations. Integrate containerization via Docker to ensure consistency between development and production, and manage deployments using Kubernetes.
6.3. Continuous Learning and Networking
Join online communities, subscribe to technical blogs, and participate in workshops or certifications related to cloud data engineering or big data technologies. Networking with experienced data engineers can provide insights into the latest industry trends and best practices, further solidifying your theoretical and practical understanding.
7. Essential Reading List for Data Engineering Mastery
7.1. Recommended Books
A number of comprehensive texts can bridge your knowledge gap between data science and data engineering:
- Data Engineering Fundamentals: This book introduces fundamental concepts like data modeling, system design, and building scalable data infrastructures. It ensures a robust theoretical foundation helping you understand how data flows across systems.
- Designing Data-Intensive Applications: This work is critical for understanding the challenges inherent in distributed systems, distributed data storage, and the trade-offs in system design. It provides a deep dive into scalability and performance optimization that is essential for any aspiring data engineer.
- Data Engineering with Python: Tailored for those already proficient in Python, this book offers practical insights into constructing data pipelines, handling real-world data problems, and efficiently processing large datasets.
- The Data Engineering Cookbook: A collection of recipes and best practices that guide you through the complexities and nuances of day-to-day data engineering challenges.
- Data Warehouse Toolkit: Focused on the practical aspects of dimensional modeling and data warehousing, this book outlines various schema designs and their suitability for different analytical workloads.
7.2. Recommended Online Courses and Resources
In addition to books, consider these practical resources:
- Data Engineering Specializations on Coursera: In-depth courses covering cloud data engineering, big data technologies, and hands-on projects.
- DataCamp Tracks: Interactive courses that allow you to practice SQL, Python, and big data processing techniques.
- Udacity Data Engineering Nanodegree: A comprehensive program focusing on data architecture, pipeline construction, and cloud computing fundamentals.
- YouTube Technical Channels: Follow channels that focus on real-world data engineering solutions and case studies to learn best practices and advanced techniques.
References
- Data Engineering Books - ProjectPro
- Books for Data Engineers - LearnSQL
- Data Engineering: Best Books - Simplilearn
- Best Data Engineer Books - Interview Query
- Influential Books for Data Engineers - Arecadata
- Must Read Data Engineering Books - Medium
- Introduction to Data Engineering - MongoDB
-
Key Data Engineering Concepts - Data Expertise
- Data Engineer Learning Resources - KnowledgeHut
- Advanced Data Engineering Resources - Interview Query
Recommended Queries
Last updated March 1, 2025