
Unveiling the Power of Database Architectures: From Embedded Simplicity to Distributed Scalability
Explore the fundamental concepts of SQLite, distributed database systems, and multi-tiered application architectures that drive modern software.
Key Insights into Database Architectures
- SQLite: The Embedded Workhorse – A self-contained, serverless, and zero-configuration database engine ideal for lightweight applications and local data storage.
- Distributed Databases: Scaling for Resilience – Systems that spread data across multiple sites to enhance scalability, fault tolerance, and performance through fragmentation, replication, and autonomy.
- Tiered Architectures: Structuring for Success – Two-tier models offer simplicity for small applications, while three-tier designs provide superior scalability, security, and maintainability for complex enterprise systems.
Delving into SQLite: The Lightweight Database Solution
SQLite stands as a unique and widely adopted relational database management system (RDBMS) primarily recognized for its self-contained, serverless, and zero-configuration nature. Unlike traditional databases such as MySQL or PostgreSQL, SQLite does not operate as a separate server process. Instead, it functions as an in-process library, reading and writing directly to ordinary disk files. This design philosophy, pioneered by Dr. Richard Hipp in 2000, aimed to provide a transactional, self-contained, and highly portable database engine. The "lite" in its name perfectly encapsulates its minimal setup, administration, and resource requirements.
A complete SQLite database, encompassing tables, indices, triggers, and views, is encapsulated within a single disk file. This singular file format boasts exceptional cross-platform compatibility, allowing databases to be effortlessly transferred and utilized across diverse operating systems and hardware architectures (e.g., 32-bit to 64-bit, big-endian to little-endian systems). Its portability and ease of integration have made it an extremely popular choice for application file formats, even garnering recommendation as a storage format by the US Library of Congress.
Core Attributes and Advantages of SQLite:
- Simplicity and Ease of Use: Developers can seamlessly integrate the SQLite library into their projects with minimal overhead, as it operates as a single-file database.
- Zero-Configuration: No complex setup procedures, user management, or network configurations are required. It's truly "plug and play."
- Self-Contained and Embedded: The entire database engine resides within the application, eliminating the need for a separate server process.
- Portability: Its single-file design enables unparalleled ease of transfer and usage across various platforms and operating systems.
- ACID Compliance: SQLite strictly adheres to the Atomicity, Consistency, Isolation, and Durability (ACID) properties, ensuring reliable transaction processing and data integrity, even during system failures.
- Performance: Being an embedded engine, SQLite can be highly optimized for specific application use cases, leading to efficient query execution, particularly for read-heavy operations.
- Widespread Deployment: It holds the distinction of being the most widely deployed database engine globally, integral to mobile operating systems (Android, iOS), web browsers (Google Chrome, Mozilla Firefox, Safari), and countless desktop applications.
- SQL Standards Support: SQLite supports a significant portion of the SQL-92 standard, including standard SQL constructs and dynamic typing, though it might omit some advanced enterprise-level features like stored procedures.
- Open Source: The source code is freely available in the public domain, fostering transparency and community contributions.
Limitations to Consider:
- While efficient for embedded and local storage, SQLite is generally not suited for high-concurrency, multi-user environments typical of large-scale enterprise applications, where server-based RDBMS solutions excel.
- It lacks some advanced features found in larger DBMS, such as comprehensive user management and certain advanced
functionalities.ALTER TABLE
To further illustrate the simplicity and utility of SQLite, here's a conceptual overview of its typical integration, as might be seen in a Python environment:
import sqlite3
# Connect to (or create) a database file
conn = sqlite3.connect('my_application_data.db')
cursor = conn.cursor()
# Create a table
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL
)
''')
# Insert data
cursor.execute("INSERT INTO users (name, email) VALUES (?, ?)", ('Alice', 'alice@example.com'))
cursor.execute("INSERT INTO users (name, email) VALUES (?, ?)", ('Bob', 'bob@example.com'))
# Commit changes and close connection
conn.commit()
conn.close()
This brief code snippet demonstrates how easily SQLite can be incorporated into an application, requiring no separate server setup or complex configurations, truly embodying its "zero-configuration" principle.
This radar chart visually compares the strengths of SQLite against a typical enterprise RDBMS across various dimensions. Notice SQLite's dominance in simplicity, portability, and resource efficiency, contrasted with an enterprise RDBMS's superior multi-user scalability.
Architecting Resilience: Understanding Distributed Database Systems
A distributed database system (DDBS) represents a collection of multiple, interconnected databases managed by a central controlling system. The core principle of a DDBS is to store data across various physical locations (computers or sites) connected by a network, while presenting a unified, logical view of the database to the user. This architecture is designed to significantly enhance performance, reliability, scalability, and availability by distributing both data and processing loads.
Fundamental Parameters Defining DDBS Architecture:
- Distribution: This refers to how data is physically scattered across different sites or nodes. Key techniques include:
- Fragmentation: The process of splitting the database into smaller, logical or physical units (fragments) that are then distributed across different nodes. This can be horizontal (splitting rows) or vertical (splitting columns).
- Replication: Maintaining copies of data across multiple nodes to improve availability, fault tolerance, and reduce access latency.
- Allocation: The strategic placement of fragments or replicas at specific sites.
- Autonomy: Describes the degree of independence each individual database management system (DBMS) at a local site can exercise. This can range from tightly coordinated systems, where sites have limited independence, to loosely coupled federated systems, where sites maintain significant autonomy.
- Heterogeneity: Indicates the diversity in the databases, system components, and data models used across various sites. A homogeneous DDBS uses identical DBMS and operating systems across all sites, while a heterogeneous system integrates different types of DBMS.
Common Architectural Models for Distributed Databases:
Several architectural models facilitate the implementation of distributed database systems, each with distinct advantages and use cases:
- Client-Server Architecture: This is a two-level model where clients send requests to servers that manage data storage and processing. In a distributed context, multiple database servers might exist, with clients communicating with the relevant server. It's relatively simple due to centralized server control but can face bottlenecks if a single server is overloaded.
- Peer-to-Peer Architecture: In this decentralized model, every node within the distributed database system can function as both a client and a server. This design offers increased resilience, load balancing, and a high degree of decentralization, as data and processing can be distributed among peers.
- Federated Architecture (Multi-DBMS Architecture): This setup integrates multiple independent and potentially heterogeneous databases through a middleware layer. Each site maintains its own local database system, and the middleware provides a common interface for accessing and querying data across these disparate sources, making it ideal for integrating legacy systems.
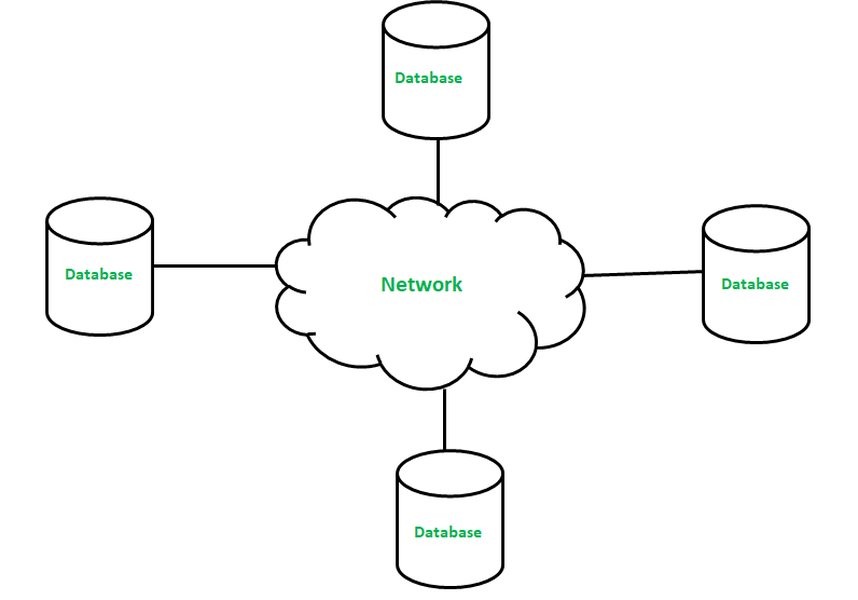
An illustration showcasing the interconnected nature of sites in a distributed database system, emphasizing data distribution and network communication.
Crucial Design Considerations for DDBS:
Designing and managing a distributed database system is complex and requires careful consideration of several factors to ensure optimal performance, consistency, and security:
- Data Transfer Optimization: Minimizing the amount of data transferred over the network and enhancing data transfer rates are crucial for performance.
- Consistency Control: Protocols are essential to ensure data integrity and consistency across all distributed sites, especially with data replication.
- Concurrency Control: Mechanisms to manage simultaneous access and modifications to data by multiple users, preventing conflicts and ensuring transactional isolation.
- Fault Tolerance and Availability: Designing the system to continue operation even if one or more sites fail, often achieved through replication and robust recovery mechanisms.
- Security and Privacy: Implementing strong authentication, encryption, and access control measures to protect sensitive data across distributed environments.
& Replication"] idC2["Consistency
& Concurrency Control"] idC3["Network Communication"] idC4["Security
& Privacy"] nodeD["Benefits"] idD1["Scalability"] idD2["Fault Tolerance"] idD3["Improved Performance"] idD4["High Availability"]
This mindmap illustrates the core components, architectural models, and critical design considerations that define distributed database systems.
Understanding Tiered Architectures: Two-Tier vs. Three-Tier Models
Database architectures, specifically two-tier and three-tier models, define how different components of an application interact, significantly impacting its scalability, security, and performance. These models are fundamental in client-server computing environments, structuring the application into logical and often physical layers.
Two-Tier Architecture: The Client-Server Direct Model
In a two-tier architecture, the application is divided into two primary layers:
- Client Layer (Presentation/Application Logic): This layer resides on the user's desktop or client machine. It typically handles the user interface (UI) and often contains a significant portion of the application's business logic.
- Data Layer (Database Server): This layer consists of the database management system (DBMS) and the stored data. It usually resides on a separate server, managing data storage, retrieval, and fundamental database operations.
In this model, the client communicates directly with the database server. It's essentially a "fat client" approach where much of the application's intelligence resides on the client side.
Advantages of Two-Tier Architecture:
- Simplicity: Relatively straightforward to design, develop, and deploy, making it suitable for smaller or simpler applications.
- Fast Development: The direct communication between client and database can accelerate development for applications with a limited scope.
Disadvantages of Two-Tier Architecture:
- Limited Scalability: It supports a relatively small number of users. As the user base grows, direct client-database interactions can lead to bottlenecks and increased load on the database server.
- Lower Security: Direct client access to the database can pose security risks, as data access control might be less centralized and potentially vulnerable.
- Maintainability Challenges: Changes in business logic often require updates across all client machines, making maintenance cumbersome.
- Performance Issues: Can experience slower performance for larger applications due to the heavy load on the database server and network traffic from direct queries.
A visual representation of the two-tier architecture, showing direct interaction between the client and the database.
Three-Tier Architecture: The Scalable and Secure Standard
A three-tier architecture introduces an intermediary layer, logically and often physically separating the application into three distinct tiers:
- Presentation Tier (Client/User Interface): Similar to the client layer in a two-tier system, this tier is responsible for displaying information to the user and handling user input. It typically resides on the client machine (e.g., a web browser or a desktop application).
- Application Tier (Business Logic/Middle Tier): This crucial intermediary layer contains the core business logic, processing rules, and application functionality. It acts as a mediator, receiving requests from the presentation tier, processing them, and then interacting with the data tier. This tier can include application servers, web servers, or message servers.
- Data Tier (Database Server): This layer is identical to the data layer in a two-tier system, comprising the database server and the stored data. It manages data storage, retrieval, and manipulation.
In this model, the client (presentation tier) communicates with the application tier, which in turn communicates with the data tier. This separation of concerns significantly enhances the system's robustness.
Advantages of Three-Tier Architecture:
- Enhanced Scalability: The middle tier allows for better load distribution and can easily accommodate a growing number of users and application demands, making it ideal for complex and dispersed systems.
- Improved Security: The client does not directly access the database, adding an essential layer of security. Centralized access control and business logic in the middle tier provide better protection.
- Increased Maintainability and Flexibility: Clear separation of concerns makes the application more modular, easier to update, and more flexible. Changes in business logic only require modifications in the application tier, without affecting clients or the database directly.
- Better Performance: By distributing processing tasks and offloading business logic from the database, a three-tier architecture can run faster for larger and more complex applications.
- Interoperability: Can easily integrate data from various sources and support diverse client types.
This video provides a clear explanation of two-tier and three-tier architectures, highlighting their key differences and benefits in system design. It delves into how the three-tier model improves scalability and security by introducing a dedicated business logic layer.
Comparison of Two-Tier and Three-Tier Architectures:
The choice between two-tier and three-tier architecture largely depends on the project's size, complexity, scalability requirements, and security needs.
| Feature | Two-Tier Architecture | Three-Tier Architecture |
|---|---|---|
| Layers | Client Layer, Data Layer | Presentation Tier, Application Tier, Data Tier |
| Communication Flow | Client <--> Database Directly | Client <--> Application Tier <--> Data Tier |
| Scalability | Limited, suitable for small user bases | High, can accommodate large user bases and complex systems |
| Security | Lower (direct database access) | Higher (indirect database access, centralized logic) |
| Maintainability | More challenging as application logic is often duplicated across clients | Easier, due to modularity and centralized business logic |
| Complexity | Simpler to develop and deploy | More complex to develop and manage |
| Ideal Use Case | Small, simple applications; departmental systems | Large-scale enterprise applications; web-based systems requiring high robustness |
In essence, while two-tier systems are easier to build for straightforward applications, three-tier architectures are the preferred choice for robust, scalable applications that demand enhanced security and distributed processing capabilities.
Frequently Asked Questions (FAQ)
Conclusion
From the nimble, self-contained SQLite database ideal for embedded systems and local storage, to the robust and scalable distributed database systems that power global operations, and the structured clarity of tiered architectures that dictate application design, the landscape of database management offers diverse solutions tailored to specific needs. SQLite’s simplicity and portability make it a staple for lightweight applications, while distributed systems are crucial for managing vast, geographically dispersed data with high availability and resilience. Similarly, the evolution from two-tier to three-tier architecture reflects a strategic move towards greater scalability, security, and maintainability, essential for complex, modern applications. Understanding these fundamental database concepts and architectural patterns is paramount for designing efficient, reliable, and adaptable software systems in today’s rapidly evolving technological environment.
Recommended Further Exploration
- What are the specific advanced SQL features missing in SQLite compared to enterprise databases?
- How do data fragmentation and replication strategies impact performance and consistency in distributed databases?
- What are N-tier architectures and how do they extend the concepts of two-tier and three-tier designs?
- Can you explain the ACID properties in detail and how they are ensured in different database systems?