
Databricks vs. Snowflake: Decoding the Cloud Data Titans (2025 Update)
Which platform reigns supreme for your data needs? Discover the crucial differences in architecture, use cases, performance, and cost.
Key Differences at a Glance
- Architecture & Focus: Databricks offers a unified "lakehouse" platform built on Apache Spark, excelling in data engineering, ML, and diverse data types. Snowflake is a cloud-native data warehouse optimized for SQL analytics and BI on structured/semi-structured data.
- Core Strengths: Databricks shines in complex data processing, real-time analytics, and end-to-end machine learning workflows. Snowflake is renowned for its ease of use, fast query performance for BI, and seamless data sharing.
- Target Users & Use Cases: Databricks caters primarily to data scientists and engineers for AI/ML and big data tasks. Snowflake targets data analysts and business users requiring efficient data warehousing and reporting.
Understanding the Platforms: Databricks and Snowflake
Databricks and Snowflake stand as two leading forces in the modern cloud data landscape. Both provide powerful solutions for managing, processing, and analyzing vast amounts of data, but they approach these challenges with distinct philosophies, architectures, and feature sets. Choosing the right platform hinges on understanding these fundamental differences and aligning them with your organization's specific goals, technical expertise, and primary workloads.
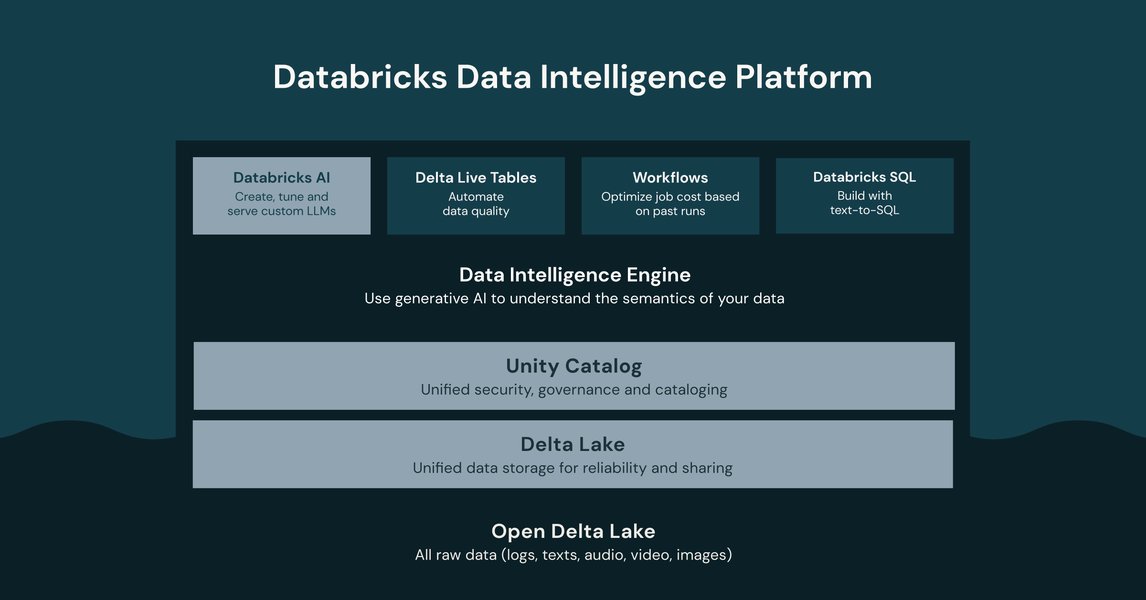
Databricks positions itself as a Data Intelligence Platform, unifying various data tasks.

Snowflake's architecture separates storage and compute layers for independent scaling.
Architectural Foundations: Lakehouse vs. Cloud Data Warehouse
Databricks: The Unified Lakehouse Approach
Databricks is built upon the open-source Apache Spark engine, renowned for its distributed computing capabilities. It champions the "lakehouse" architecture, aiming to merge the scalability and flexibility of data lakes (handling raw, unstructured data) with the performance and ACID transactional reliability of data warehouses (handling structured data). Key components include:
- Apache Spark: Provides the core engine for large-scale data processing, analytics, and machine learning.
- Delta Lake: An open-format storage layer that brings reliability (ACID transactions, schema enforcement, time travel) to data lakes, effectively enabling the lakehouse.
- MLflow: An integrated platform for managing the end-to-end machine learning lifecycle.
- Collaborative Workspace: Offers interactive notebooks and tools facilitating collaboration among data engineers, scientists, and analysts.
This architecture makes Databricks exceptionally versatile, capable of handling structured, semi-structured, and unstructured data within a single platform, making it ideal for complex ETL, real-time streaming, data science, and AI/ML workloads.
Snowflake: The Purpose-Built Cloud Data Warehouse
Snowflake operates as a Software-as-a-Service (SaaS) cloud data warehouse. Its unique, proprietary architecture is designed for simplicity, performance, and elasticity, centered around SQL-based analytics. Key architectural features include:
- Separation of Storage and Compute: Data is stored centrally, while multiple independent compute clusters (Virtual Warehouses) can access it simultaneously. This allows scaling compute resources up, down, or out without affecting storage, and vice-versa.
- Multi-Cluster, Shared Data: Enables high concurrency and workload isolation, as different teams or tasks can use separate compute resources without interfering with each other.
- Optimized Storage: Data is automatically compressed and stored in an optimized columnar format.
- SQL Focus: Primarily designed for efficient execution of SQL queries, making it highly suitable for business intelligence (BI) and standard analytical tasks.
Snowflake excels at providing a highly scalable, easy-to-manage environment for storing and analyzing structured and semi-structured data, emphasizing performance for BI tools and ad-hoc querying.
Feature Face-Off: Capabilities Compared
Data Handling and Processing
Databricks
Databricks inherently supports a wider variety of data types, including raw, unstructured data (text, images, video) alongside structured and semi-structured formats (like JSON, Parquet, Avro). Its Spark engine is optimized for large-scale transformations (ETL/ELT) and both batch and real-time streaming data processing.
Snowflake
Snowflake shines with structured and semi-structured data. While it can ingest various formats, its core strength lies in optimizing and querying data that fits a relational or semi-relational model. Its streaming capabilities are evolving but traditionally less robust than Databricks' native Spark Streaming.
Machine Learning and AI Integration
Databricks
This is a core strength. Databricks provides an integrated environment for the entire ML lifecycle, from data preparation and feature engineering to model training (leveraging libraries like scikit-learn, TensorFlow, PyTorch via Spark), deployment, and monitoring using MLflow. It offers native support for advanced AI tasks and integration with LLMs.
Snowflake
Snowflake is expanding its ML capabilities through features like Snowpark (allowing code in Python, Java, Scala) and integrations with third-party ML platforms. However, its native ML tooling is less comprehensive than Databricks. It's more often used as the data source/serving layer for models developed elsewhere, or for in-database SQL-based ML functions.
Performance and Scalability
Databricks
Leverages Spark's distributed, in-memory processing for high throughput on complex data transformations and ML training. Scalability is achieved by adjusting Spark cluster sizes. Performance can be highly optimized but may require more configuration and tuning expertise.
Snowflake
Offers instant, elastic scalability by resizing virtual warehouses on demand, often with near-zero downtime. Its architecture is optimized for high concurrency and fast SQL query execution, particularly beneficial for BI dashboards and interactive analysis.
Ease of Use and Administration
Databricks
Provides a powerful, flexible environment but generally has a steeper learning curve, especially for optimizing Spark jobs. It requires more administrative effort for cluster management and configuration compared to Snowflake's SaaS model.
Snowflake
Widely praised for its simplicity and ease of use. As a fully managed SaaS offering, it requires minimal administration for infrastructure management, scaling, and maintenance, making it accessible to users familiar with SQL.
Cost Structure
Databricks
Pricing is typically based on compute usage (Databricks Units - DBUs) per hour, varying by VM type and cluster configuration. Can be more cost-effective for heavy, continuous ETL/ML workloads where Spark's efficiency can be maximized. Costs can be less predictable without careful monitoring.
Snowflake
Uses a consumption-based model, charging separately for storage used and compute time (per-second billing for virtual warehouses). Compute resources automatically suspend when idle, leading to potentially predictable costs, especially for intermittent query workloads common in BI. However, heavy, continuous processing might become expensive.
Visualizing Strengths: Capability Radar Chart
This radar chart provides a visual comparison of Databricks and Snowflake across key capabilities, based on general industry perception and typical use cases. Scores are relative interpretations (1=Lower Strength, 10=Higher Strength) and not based on specific benchmarks.
As illustrated, Databricks generally leads in ML/AI, complex data engineering, streaming, and handling unstructured data. Snowflake excels in BI performance, ease of administration, structured/semi-structured data querying, data sharing, and often provides more predictable costs for typical BI workloads.
Mindmap: Core Distinctions
This mindmap visually summarizes the fundamental differences between Databricks and Snowflake across key areas.
Delta Lake Reliability
Complex Transformations
Diverse Data Handling"] UserFocus1["Data Engineers
Data Scientists"] Admin1["More Configuration
Cluster Management"] CostModel1["Compute (DBUs)
Potentially Cheaper for Heavy ETL/ML"] Snowflake["Snowflake"] Arch2["Cloud Data Warehouse (SaaS)"] CoreTech2["Proprietary SQL Engine
Storage/Compute Separation"] DataTypes2["Structured, Semi-structured"] PrimaryUse2["BI & Analytics
Data Warehousing
Reporting"] Strengths2["SQL Performance
Ease of Use
Scalability & Concurrency
Data Sharing
Simple Admin"] UserFocus2["Data Analysts
Business Users"] Admin2["Minimal Admin
Fully Managed"] CostModel2["Storage + Compute (Per Second)
Predictable for BI
Auto-Suspend"]
Comparative Summary Table
Here's a table summarizing the key distinctions discussed:
| Feature | Databricks | Snowflake |
|---|---|---|
| Primary Focus | Unified Analytics Platform (Data Engineering, ML/AI, Data Science) | Cloud Data Warehouse (BI, Analytics, Reporting) |
| Architecture | Lakehouse (Data Lake + Data Warehouse) | Cloud-Native Data Warehouse |
| Core Technology | Apache Spark, Delta Lake, MLflow | Proprietary SQL Engine, Separate Storage/Compute |
| Data Types Handled | Structured, Semi-structured, Unstructured, Streaming | Primarily Structured and Semi-structured |
| ML & AI Support | Deep, native integration (MLflow, Spark MLlib) | Growing support (Snowpark, SQL functions, integrations), less native tooling |
| Performance Strength | Complex transformations, large-scale ETL, ML training | High-concurrency SQL queries, BI dashboarding |
| Scalability | Cluster scaling (requires configuration) | Instant, elastic scaling of compute (Virtual Warehouses) |
| Ease of Use | Steeper learning curve, requires more technical expertise | Simpler interface, easy to manage, familiar SQL environment |
| Administration | Requires cluster management and optimization | Fully managed SaaS, minimal admin overhead |
| Cost Model | Compute-based (DBUs), potentially better for heavy processing | Consumption-based (Storage + Compute), predictable for BI |
| Ideal User | Data Scientists, Data Engineers | Data Analysts, BI Professionals, Business Users |
Exploring Further: Video Insights
For a dynamic discussion and comparison of Databricks and Snowflake, including perspectives on their evolution and positioning in the market, consider this video:
This video compares Databricks and Snowflake, discussing performance aspects relevant for 2025.
The video delves into performance comparisons and practical considerations when choosing between the two platforms, offering valuable context alongside the technical differences outlined here. It reinforces the idea that while both are powerful, their optimal use cases differ significantly based on workload characteristics and team expertise.
Frequently Asked Questions (FAQ)
Which platform is better for Machine Learning?
Is Snowflake or Databricks easier to use?
Which platform is more cost-effective?
Can Databricks and Snowflake be used together?
Recommended Reads
- Explore the intricacies of the Databricks lakehouse architecture and Delta Lake.
- Understand how Snowflake's virtual warehouses provide elastic scaling and query performance.
- Analyze the cost implications of running ETL workloads on Databricks versus Snowflake.
- Discover strategies for integrating Databricks and Snowflake within a cohesive data platform strategy.
References
Last updated May 5, 2025