
Understanding Large Language Models: An In-Depth Exploration
Unveiling the Mechanics Behind Advanced AI Text Generation
Key Takeaways
- Transformer Architecture: The foundational framework enabling efficient processing of language data.
- Training Phases: Pre-training on massive datasets followed by fine-tuning for specific tasks.
- Applications and Challenges: Versatile uses in various domains with ongoing challenges in bias and interpretability.
Introduction to Large Language Models
Large Language Models (LLMs) represent a significant advancement in artificial intelligence, specifically in the realm of natural language processing. These models are designed to understand, interpret, and generate human-like text by leveraging extensive data and sophisticated algorithms. The ability of LLMs to perform a variety of language-based tasks has made them integral to applications ranging from chatbots and virtual assistants to automated content creation and translation services.
Core Architecture of Large Language Models
Transformer Architecture
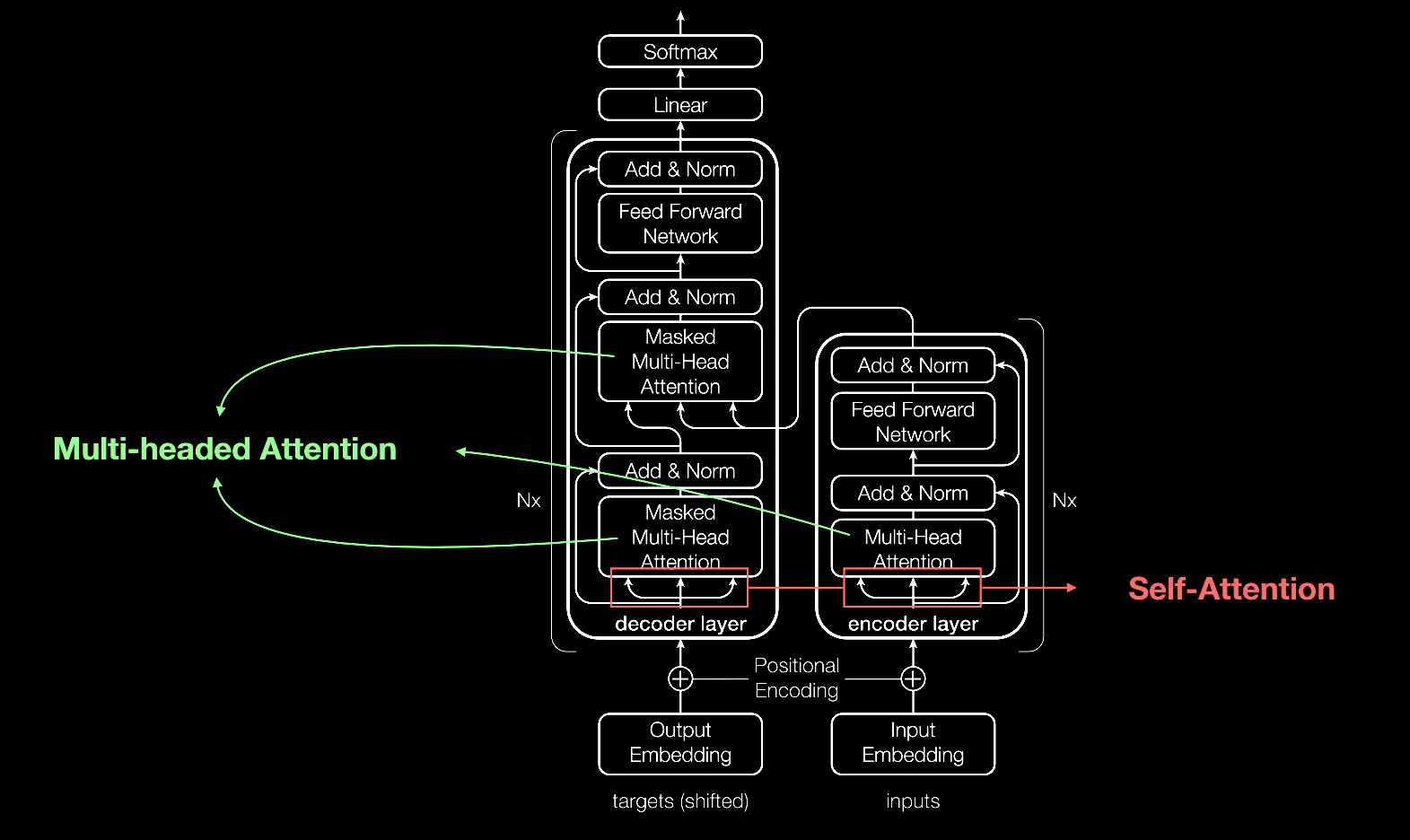
At the heart of LLMs lies the transformer architecture, introduced in the seminal paper "Attention Is All You Need" by Vaswani et al. in 2017. Transformers have revolutionized the field by enabling models to handle long-range dependencies and complex language structures more effectively than previous architectures like Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs).
Key Components of Transformers
- Encoder and Decoder: The transformer consists of an encoder that processes the input text and a decoder that generates the output. However, many LLMs utilize only the decoder part for tasks like text generation.
- Self-Attention Mechanism: This allows the model to weigh the importance of different words in a sequence relative to each other, facilitating a deeper understanding of context.
- Multi-Head Attention: By employing multiple attention heads, the model can focus on different aspects of the input simultaneously, enhancing its ability to capture diverse linguistic features.
- Feed-Forward Networks: Positioned after the attention layers, these networks further process the information, enabling complex transformations of the input data.
- Positional Encoding: Since transformers do not inherently process data sequentially, positional encodings are added to the input embeddings to provide information about the order of tokens.
Tokenization and Embedding
Before processing text, LLMs tokenize the input into smaller units called tokens. Tokenization can be based on characters, words, or subwords, depending on the model's design. Each token is then converted into a numerical representation known as an embedding. These embeddings capture semantic information, allowing the model to understand relationships and similarities between different tokens.
Embeddings
Embeddings are multi-dimensional vectors that represent tokens in a continuous space. Words with similar meanings have embeddings that are closer together, facilitating the model's ability to generalize and understand nuanced language patterns.
Training Large Language Models
Pre-Training Phase
The pre-training phase involves exposing the model to vast amounts of text data sourced from books, articles, websites, and other text-rich repositories. During this phase, the model learns to predict the next word in a sequence, a task known as language modeling. This self-supervised learning process enables the model to grasp grammar, syntax, semantics, and factual knowledge implicitly.
Objectives of Pre-Training
- Language Understanding: Developing a comprehensive grasp of language structures and patterns.
- Contextual Relationships: Learning how different parts of a text relate to each other to maintain coherence.
- Knowledge Acquisition: Accumulating factual information embedded within the training data.
Fine-Tuning Phase
After pre-training, LLMs undergo fine-tuning on specialized datasets tailored to specific tasks such as sentiment analysis, translation, or question-answering. This supervised learning phase refines the model's parameters to enhance performance in targeted applications, ensuring that the model can deliver more accurate and contextually appropriate responses.
Techniques in Fine-Tuning
- Supervised Learning: Utilizing labeled data to guide the model towards desired outputs for specific tasks.
- Reinforcement Learning with Human Feedback (RLHF): Incorporating human evaluations to refine the model's responses, promoting alignment with human expectations and ethical standards.
- Domain Adaptation: Adjusting the model to perform optimally within specific domains, such as medical or legal text processing.
Operational Workflow of Large Language Models
Input Encoding and Tokenization
The initial step in processing involves tokenizing the raw input text. Tokenization breaks down the text into manageable units, which are then transformed into numerical embeddings. Positional encodings are added to these embeddings to retain the sequential information, crucial for understanding the context and flow of the text.
Core Processing with Transformers
The processed tokens pass through multiple transformer layers, each comprising self-attention and feed-forward mechanisms. The self-attention mechanism dynamically assesses the relevance of each token concerning others in the sequence, allowing the model to maintain contextual coherence. Multi-head attention further enhances this by enabling the model to focus on different aspects of the input simultaneously.
Output Generation
During inference, the model generates text by predicting one token at a time, using the probabilities learned during training. Decoding strategies such as greedy decoding, beam search, or sampling methods can be employed to balance between coherence and creativity in the generated output.
Decoding Strategies
-
Greedy Decoding: Selecting the token with the highest probability at each step, ensuring the most likely path.
-
Beam Search: Maintaining multiple hypotheses simultaneously to explore a broader range of possible continuations.
-
Sampling Methods: Introducing randomness by sampling tokens based on their probability distribution, fostering diverse and creative outputs.
Applications of Large Language Models
Text Generation and Content Creation
One of the most prominent applications of LLMs is in generating human-like text. This capability is leveraged in various domains, including automated article writing, creative story generation, and even composing poetry. By understanding context and maintaining coherence, LLMs can produce content that is both relevant and engaging.
Translation Services
LLMs facilitate accurate and contextually appropriate translations between languages. By capturing nuanced meanings and idiomatic expressions, these models enhance the quality of machine translation, making it more reliable for communication across different languages.
Question Answering and Virtual Assistants
In virtual assistant applications, LLMs enable more natural and informative interactions. They can comprehend user queries, retrieve relevant information, and provide coherent answers, enhancing user experience and efficiency in obtaining information.
Summarization
LLMs excel at condensing large volumes of text into concise summaries. This application is invaluable in fields like journalism, research, and business, where swift comprehension of extensive documents is essential.
Code Generation and Assistance
Beyond natural language, LLMs are adept at generating and understanding code. They assist programmers by suggesting code snippets, debugging, and even writing entire functions, thereby increasing productivity and reducing the likelihood of errors.
Challenges and Limitations
Bias and Ethical Concerns
LLMs are trained on vast datasets sourced from the internet, which may contain inherent biases. Consequently, models can inadvertently perpetuate or amplify these biases in their outputs, raising ethical concerns regarding fairness and representation.
Interpretability and Transparency
The complex nature of LLMs makes it challenging to interpret their decision-making processes. The "black-box" nature of these models hinders the ability to understand how specific outputs are generated, complicating efforts to ensure accountability and trustworthiness.
Resource Intensity
Training and deploying LLMs require substantial computational resources, including powerful GPUs and extensive memory. This resource intensity poses challenges in terms of cost, energy consumption, and accessibility, potentially limiting the widespread adoption of these models.
Hallucinations and Accuracy
Despite their advanced capabilities, LLMs can produce outputs that are factually incorrect or nonsensical, a phenomenon known as hallucination. Ensuring the accuracy and reliability of generated content remains a significant challenge.
Security Concerns
LLMs can be susceptible to adversarial attacks and malicious inputs that manipulate their outputs. Ensuring the security and robustness of these models is crucial to prevent misuse and maintain their integrity in sensitive applications.
Enhancements and Future Directions
Improving Interpretability
Researchers are actively developing techniques to make LLMs more interpretable, such as attention visualization and feature attribution methods. These advancements aim to shed light on the internal workings of models, fostering greater transparency and trust.
Addressing Bias and Fairness
Efforts to mitigate bias involve curating more balanced training datasets, implementing fairness-aware algorithms, and conducting thorough bias assessments. These strategies strive to ensure that LLMs produce equitable and unbiased outputs.
Enhancing Efficiency
Innovations in model architecture, such as sparse models and efficient transformers, aim to reduce the computational burden of LLMs. Techniques like model pruning, quantization, and knowledge distillation are being explored to make models more efficient without compromising performance.
Expanding Multimodal Capabilities
Integrating multiple data modalities, such as text, images, and audio, is an emerging trend. Multimodal models enhance the versatility of LLMs, enabling them to understand and generate content across different types of media.
Scalability and Accessibility
Advancements in distributed computing and cloud-based solutions are making it easier to scale LLMs and make them more accessible to a broader range of users and applications. Efforts to democratize access to powerful language models aim to foster innovation and inclusive growth.
Technical Specifications and Scalability
| Aspect | Description |
|---|---|
| Parameters | Modern LLMs can have from hundreds of millions to several hundred billion parameters, enabling them to capture intricate language patterns. |
| Training Data | Trained on diverse and extensive datasets encompassing books, articles, websites, and other text sources to ensure comprehensive language understanding. |
| Computational Resources | Requires powerful GPUs and substantial memory for both training and inference, often utilizing distributed computing frameworks. |
| Training Duration | Training can span weeks or months, depending on the model size and available computational resources. |
| Energy Consumption | Significant energy is consumed during training, raising concerns about the environmental impact and sustainability of large-scale AI models. |
Conclusion
Large Language Models have fundamentally transformed the landscape of artificial intelligence and natural language processing. By leveraging transformer architectures and vast amounts of data, these models achieve remarkable proficiency in understanding and generating human-like text. Their wide-ranging applications continue to drive innovation across various industries, from technology and healthcare to entertainment and education. However, the challenges associated with bias, interpretability, and resource demands underscore the need for ongoing research and responsible development. As advancements in AI continue, LLMs are poised to become even more integral to the way we interact with technology and harness the power of language.
References
 aws.amazon.com
aws.amazon.com
Last updated February 2, 2025