
Dynamic Context Pruning via Information Bottleneck Theory
Enhancing Model Efficiency and Interpretability through Intelligent Context Reduction
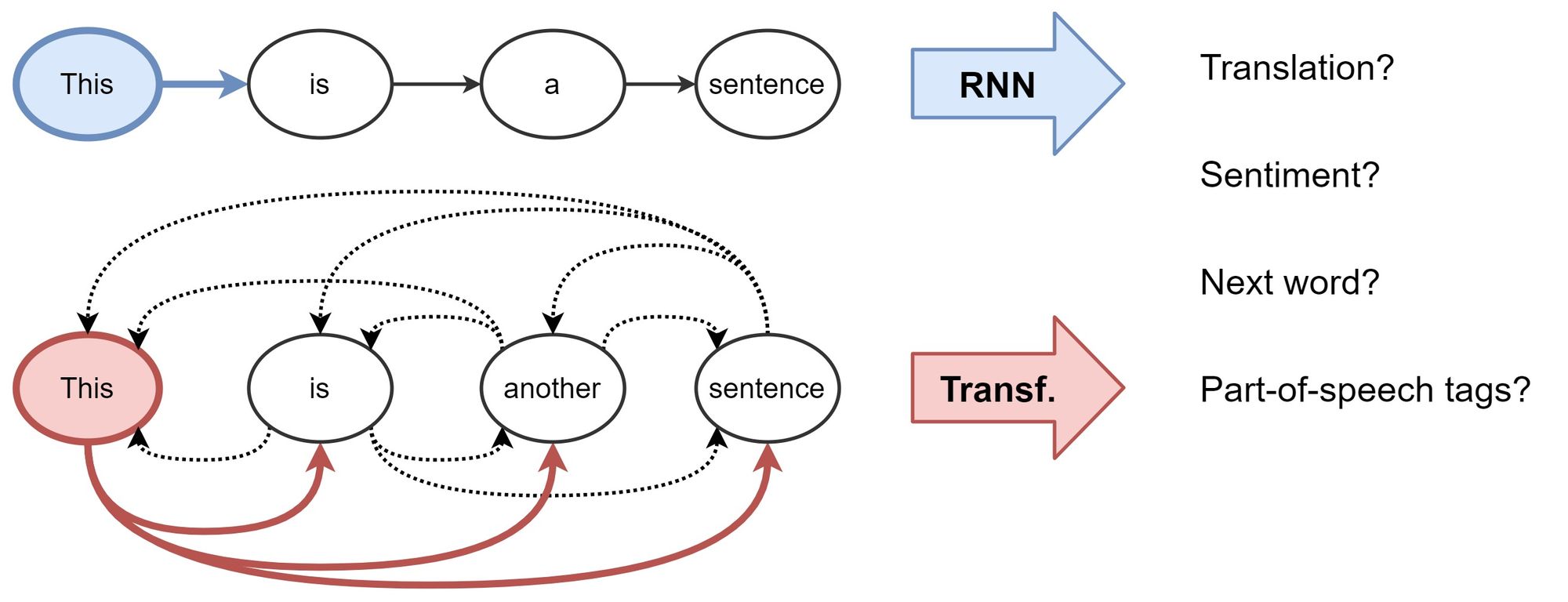
Key Takeaways
- Efficient Computational Management: Up to 80% of context can be pruned, significantly reducing computational and memory overhead.
- Theoretical Foundation: Utilizes Information Bottleneck Theory to ensure pruned context retains essential task-relevant information.
- Enhanced Interpretability: Pruning provides insights into which contextual elements are most influential for model decisions.
Introduction
In the landscape of deep learning, particularly within autoregressive models like Large Language Models (LLMs), the management of contextual information is paramount. As models grow in complexity and size, efficiently handling extensive input sequences without compromising performance becomes a significant challenge. Dynamic Context Pruning emerges as a sophisticated solution, leveraging the principles of Information Bottleneck (IB) Theory to intelligently reduce context, thereby enhancing both efficiency and interpretability.
Understanding the Information Bottleneck Theory
Foundational Concepts
The Information Bottleneck Theory, rooted in information theory, provides a framework for extracting relevant information from input variables. The core objective is to compress the input data (X) into a representation (T) that retains maximal information about the target variable (Y) while minimizing unnecessary details. Formally, this involves optimizing the following trade-off:
$$ \min I(X; T) - \beta I(T; Y) $$
where I(X; T) represents the mutual information between the input and the representation, and I(T; Y) denotes the mutual information between the representation and the target. The parameter β balances the trade-off between compression and preservation of relevant information.
Applications in Neural Networks
In the context of neural networks, IB Theory has been instrumental in guiding the pruning of networks by identifying and removing less relevant neurons or filters. This not only reduces the model's complexity but also enhances its generalization capabilities by eliminating redundant or noisy information.
Dynamic Context Pruning: An Overview
Conceptual Framework
Dynamic Context Pruning involves the adaptive reduction of contextual information in autoregressive transformers and LLMs during the generation process. The primary goal is to identify and prune uninformative tokens or segments of the input sequence without significantly impacting the model's performance on downstream tasks.
This dynamic approach contrasts with static pruning methods that apply fixed rules or thresholds, instead enabling the model to make context-dependent pruning decisions based on the relevance of each input segment.
Integration with Information Bottleneck Theory
By integrating IB Theory, Dynamic Context Pruning ensures that the pruned context retains the maximal amount of task-relevant information. The IB-based pruning mechanism evaluates the mutual information between different parts of the context and the target task, selectively removing those elements that contribute least to the predictive performance.
This theoretically grounded approach provides a principled way to balance the trade-off between computational efficiency and model accuracy, as opposed to heuristic methods that may lack such rigorous underpinnings.
Implementation Strategies
Pruning Mechanism
The pruning process in Dynamic Context Pruning involves several key components:
- Encoder: Transforms the input sequence into an internal representation.
- Pruner: A gating mechanism that decides which tokens or segments to retain or discard based on their mutual information with the target task.
- Decoder: Processes the pruned representation to perform the desired task, such as translation, summarization, or classification.
Dynamic Adjustment Through Sparsity Parameters
A critical aspect of this approach is the dynamic adjustment of pruning strength via sparsity parameters. These parameters enable fine-tuning of the pruning process, allowing the model to adaptively balance between computational efficiency and performance based on specific requirements or constraints.
Optimization Objectives
The training objective for Dynamic Context Pruning incorporates both predictive performance and compression:
- Predictive Loss: Ensures that the pruned context maintains high mutual information with the target task.
- Regularization Term: Encourages compression by penalizing excessive retention of contextual information.
This dual-objective optimization ensures that the pruning process is both effective in reducing context and preserving essential information for accurate predictions.
Empirical Performance and Benefits
Efficiency Gains
Empirical studies demonstrate that Dynamic Context Pruning can achieve significant reductions in computational requirements. For instance, models have successfully pruned up to 80% of context without notable degradation in performance, leading to:
- Reduced FLOPs: Lower floating-point operations, enhancing inference speed.
- Memory Savings: Decreased memory footprint, facilitating deployment on resource-constrained devices.
- Increased Throughput: Enhanced throughput, allowing for faster processing of inputs.
Maintained Performance
Despite substantial pruning, models retain a high degree of accuracy and effectiveness on downstream tasks. For example, pruning 66.42% of FLOPs in a ResNet-50 model resulted in only a 1.17% drop in top-5 accuracy, showcasing the method's ability to preserve critical information while eliminating redundancy.
Enhanced Interpretability
By explicitly identifying and retaining the most relevant contextual elements, Dynamic Context Pruning offers insights into the model's decision-making process. This transparency aids in understanding which parts of the input are most influential, contributing to the overall interpretability of the model.
Practical Applications and Use Cases
Large Language Models
In LLMs, where input sequences can be extensive, Dynamic Context Pruning effectively manages context length without sacrificing comprehension or generation quality. This is particularly beneficial for tasks such as:
-
Summarization
-
Machine Translation
-
Question Answering
-
Content Generation
Resource-Constrained Environments
Deploying deep learning models on devices with limited computational resources, such as mobile phones or edge devices, benefits greatly from reduced model complexity. Dynamic Context Pruning facilitates efficient model deployment by lowering the computational and memory demands.
Real-Time Systems
Applications requiring real-time processing, such as interactive chatbots or autonomous systems, can leverage the increased inference speed provided by dynamic pruning to deliver timely responses and maintain high performance under stringent latency constraints.
Challenges and Considerations
Optimization Complexity
Implementing Dynamic Context Pruning involves optimizing mutual information measures, which can be computationally intensive. Ensuring that the pruning mechanism itself remains efficient and does not introduce significant overhead is crucial for maintaining overall model performance.
Maintaining Differentiability
For the pruning process to be integrated seamlessly into gradient-based training, it must remain differentiable. Techniques such as stochastic gating or continuous relaxations are employed to preserve differentiability, enabling effective training of the pruning mechanism alongside the rest of the model.
Balancing Pruning Strength
Determining the optimal level of context to prune is a delicate balance. Excessive pruning may lead to loss of important information and model degradation, while insufficient pruning may not yield the desired efficiency gains. Fine-tuning sparsity parameters based on specific tasks and datasets is essential to achieve optimal results.
Performance Summary
The table below summarizes key performance metrics observed in studies applying Dynamic Context Pruning via Information Bottleneck Theory:
| Model | Pruned Context (%) | FLOPs Reduction (%) | Performance Drop (%) | Throughput Increase |
|---|---|---|---|---|
| LLM-Transformer | 80% | 2x | Minimal | 2x Inference Speed |
| ResNet-50 | 66.42% | 66% | 1.17% Top-5 Accuracy Drop | Not Specified |
| Generic Autoregressive Model | Up to 80% | Up to 2x | Insignificant Performance Impact | Enhanced Throughput |
Future Directions
Integration with Other Pruning Techniques
Combining Dynamic Context Pruning with other model compression techniques, such as quantization or knowledge distillation, could further enhance model efficiency and performance. Exploring synergistic approaches may lead to more robust and versatile pruning strategies.
Adaptive Sparsity Parameters
Developing adaptive methods for adjusting sparsity parameters in real-time based on input complexity or task requirements could optimize pruning dynamically, ensuring that the model remains both efficient and effective across diverse scenarios.
Broader Applicability
Extending the principles of Dynamic Context Pruning to other types of neural architectures, beyond transformers and LLMs, could broaden its applicability. Investigating its effectiveness in recurrent neural networks or convolutional neural networks may uncover new avenues for efficiency improvements.
Conclusion
Dynamic Context Pruning via Information Bottleneck Theory represents a significant advancement in the quest for more efficient and interpretable deep learning models. By intelligently reducing contextual information while preserving essential task-relevant data, this approach addresses the dual challenges of computational complexity and model transparency. The integration of a theoretically grounded framework ensures that pruning decisions are both effective and principled, offering substantial benefits across various applications, from large language models to resource-constrained environments. As research continues to refine and expand upon these methods, Dynamic Context Pruning stands poised to play a pivotal role in the future of efficient neural network design.
References
Last updated February 5, 2025