
Comprehensive Guide to Ensemble Machine Learning Methods for Highly Imbalanced Datasets
Enhancing Model Performance in Critical Applications with Advanced Ensemble Techniques
Key Takeaways
- Effective Handling of Class Imbalance: Ensemble methods significantly improve the detection of minority classes by combining multiple models and leveraging various sampling techniques.
- Diverse Approaches: Techniques such as bagging, boosting, hybrid, and cost-sensitive methods offer tailored solutions to address different aspects of imbalance in datasets.
- Enhanced Performance Metrics: Utilizing appropriate evaluation metrics like F1-score and AUC-ROC ensures a balanced assessment of model performance on imbalanced data.
Introduction
In the realm of machine learning, highly imbalanced datasets pose significant challenges, particularly in critical fields such as fraud detection, medical diagnosis, and anomaly detection. These datasets are characterized by a disproportionate ratio between majority and minority classes, often leading to biased models that overlook the minority class. Ensemble learning methods have emerged as potent solutions to this problem, combining multiple models to enhance predictive performance and ensure better detection of minority classes. This comprehensive guide explores various ensemble techniques tailored for highly imbalanced datasets, their mechanisms, advantages, and practical applications.
Understanding Class Imbalance
Class imbalance occurs when one class significantly outnumbers others in the training data. This imbalance can lead to models that are skewed toward the majority class, thereby neglecting the minority class, which is often more critical. The primary challenges associated with imbalanced datasets include:
- Bias Toward Majority Class: Machine learning algorithms tend to optimize for overall accuracy, which can result in poor performance on the minority class.
- Metric Insensitivity: Traditional evaluation metrics like accuracy fail to capture the nuances of minority class performance, necessitating the use of metrics such as precision, recall, F1-score, and AUC-ROC.
Ensemble Learning Methods
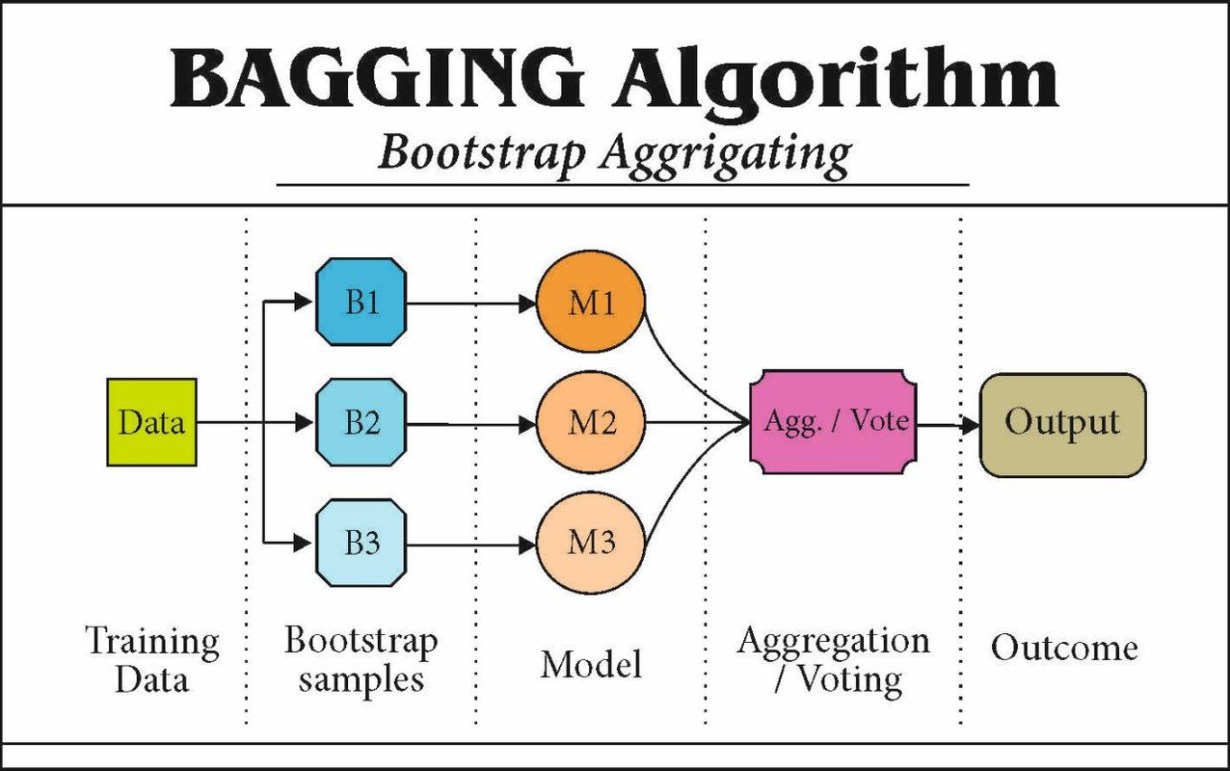
1. Bagging-Based Methods
Bagging, or Bootstrap Aggregating, is an ensemble technique that aims to reduce variance by training multiple models on different subsets of the data and aggregating their predictions. For imbalanced datasets, bagging can be adapted with resampling techniques to balance class distributions.
Random Forest with Class Weights
Random Forest is a popular bagging method that combines multiple decision trees to create a robust classifier. When dealing with imbalanced data, Random Forest can be enhanced by adjusting class weights to give more importance to the minority class or by implementing a Balanced Random Forest that undersamples the majority class in each bootstrap sample.
SMOTEBagging
SMOTEBagging integrates the Synthetic Minority Over-sampling Technique (SMOTE) with bagging. SMOTE generates synthetic samples for the minority class, thereby balancing the dataset. Bagging then ensures diversity in training subsets, improving the model's ability to generalize.
UnderBagging
UnderBagging employs random undersampling of the majority class in combination with bagging. By reducing the number of majority class samples, UnderBagging creates balanced training sets, mitigating the bias toward the majority class.
2. Boosting-Based Methods
Boosting focuses on sequentially training models, where each subsequent model aims to correct the errors of its predecessor. This approach is particularly effective for imbalanced datasets as it emphasizes the minority class by giving more weight to misclassified instances.
AdaBoost with Cost-Sensitivity
AdaBoost adjusts the weights of training samples, increasing the weight for misclassified instances. By incorporating cost-sensitive learning, AdaBoost assigns higher misclassification costs to the minority class, thereby focusing the learning process on these critical samples.
SMOTEBoost
SMOTEBoost combines SMOTE with the boosting process. In each iteration, SMOTE generates synthetic minority class samples, which are then used to train the boosted model. This integration enhances the model's ability to recognize and correctly classify minority class instances.
RUSBoost
RUSBoost integrates Random Undersampling (RUS) with boosting. By undersampling the majority class in each boosting iteration, RUSBoost maintains a balanced class distribution, ensuring that the model does not become biased toward the majority class.
3. Hybrid Ensemble Methods
Hybrid methods combine multiple techniques, such as bagging, boosting, and resampling, to effectively address class imbalance from different angles.
EasyEnsemble
EasyEnsemble creates multiple balanced subsets by undersampling the majority class and trains a separate classifier on each subset. The final prediction is made by aggregating the predictions from all classifiers, enhancing the detection of the minority class.
BalanceCascade
BalanceCascade sequentially trains classifiers on balanced subsets, removing correctly classified majority class samples in each iteration. This approach focuses subsequent classifiers on harder-to-classify samples, improving overall model performance on the minority class.
Stacking with Sampling
Stacking combines different base learners trained on resampled data. By leveraging the strengths of multiple algorithms and sampling strategies, stacking enhances the model's robustness and sensitivity to the minority class.
4. Cost-Sensitive Ensemble Methods
Cost-sensitive methods incorporate misclassification costs into the learning process, assigning higher penalties to errors on the minority class. This approach ensures that the model prioritizes the correct classification of minority instances.
Cost-Sensitive Random Forest
Cost-Sensitive Random Forest adjusts the class weights within the Random Forest algorithm, penalizing misclassifications of the minority class more heavily. This modification leads to improved precision and recall for the minority class.
Cost-Sensitive AdaBoost
Cost-Sensitive AdaBoost modifies the boosting algorithm to incorporate a cost matrix, assigning higher costs to minority class misclassifications. This ensures that the boosting process focuses more on correctly classifying the minority class.
5. Advanced Ensemble Techniques
Recent advancements have introduced innovative ensemble approaches that further enhance performance on imbalanced datasets by focusing on critical samples and reducing noise.
Anomaly Scoring-Based Ensemble (ASE)
ASE utilizes anomaly scoring to identify and prioritize minority class samples during training. By focusing on these critical samples, ASE enhances the model's ability to detect rare events effectively.
Iterative-Partitioning Filter (IPF)
IPF applies a data-level preprocessing filter to reduce noise and improve the quality of training data before ensemble methods are applied. This preprocessing step leads to more accurate and reliable model performance.
Implementation Considerations
When deploying ensemble methods for highly imbalanced datasets, several factors must be considered to ensure optimal performance:
- Data Preprocessing: Feature selection, scaling, normalization, and handling missing values are crucial steps that can significantly impact model performance.
- Sampling Strategies: Choosing the appropriate resampling technique, whether oversampling like SMOTE or undersampling like RUS, is essential for balancing the dataset.
- Algorithm Modifications: Incorporating class weights or cost-sensitive learning within ensemble algorithms helps prioritize the minority class.
- Evaluation Metrics Optimization: Utilizing metrics such as precision, recall, F1-score, and AUC-ROC provides a more balanced assessment of model performance beyond mere accuracy.
- Performance Optimization: Employing cross-validation with stratified sampling, careful parameter tuning, and monitoring for overfitting are vital for robust model development.
Applications
Ensemble methods for handling imbalanced datasets are widely applicable across various domains where minority class predictions are critical:
-
Healthcare: Early detection of rare diseases or disorders, where accurate classification of minority classes can save lives.
-
Fraud Detection: Identifying fraudulent transactions in financial systems, where fraudulent cases are significantly outnumbered by legitimate transactions.
-
Customer Retention: Predicting customer churn in subscription-based services, enabling proactive retention strategies.
-
Credit Risk Analysis: Assessing credit defaults, which typically involve a small subset of borrowers compared to the overall population.
Practical Example: Implementing SMOTEBagging
To illustrate the application of ensemble methods on imbalanced datasets, consider implementing SMOTEBagging using Python's scikit-learn and imbalanced-learn libraries:
# Import necessary libraries
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# Load dataset
X, y = load_your_data()
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
# Define the SMOTEBagging pipeline
pipeline = Pipeline([
('smote', SMOTE(sampling_strategy='minority')),
('bagging', BaggingClassifier(base_estimator=DecisionTreeClassifier(),
n_estimators=50,
random_state=42))
])
# Train the model
pipeline.fit(X_train, y_train)
# Make predictions
y_pred = pipeline.predict(X_test)
# Evaluate the model
print(classification_report(y_test, y_pred))
In this example, SMOTEBagging is implemented by first applying SMOTE to generate synthetic minority class samples, followed by a BaggingClassifier that aggregates multiple Decision Trees. The classification report provides metrics to evaluate the model's performance on both majority and minority classes.
Conclusion
Handling highly imbalanced datasets is a critical challenge in machine learning, especially in applications where the minority class holds significant importance. Ensemble learning methods, through their ability to combine multiple models and incorporate various sampling and cost-sensitive techniques, offer robust solutions to this problem. By leveraging methods such as bagging, boosting, hybrid approaches, and cost-sensitive learning, practitioners can significantly enhance the performance of their models on imbalanced data. The choice of ensemble method should be informed by the specific characteristics of the dataset and the contextual requirements of the application, ensuring a balanced trade-off between precision, recall, and computational efficiency.
References
Last updated January 23, 2025