
Unlock Web Data Effortlessly: Your Guide to Google Gemini 2.0 & Top Scraping Alternatives (May 2025)
Discover how AI-powered Google Gemini 2.0 revolutionizes web scraping, and explore leading free, open-source alternatives for all your data extraction needs.
Key Insights: Web Scraping in 2025
- Gemini 2.0 Simplifies Scraping: Google Gemini 2.0 offers a revolutionary no-code/low-code approach, allowing users to extract web data using natural language prompts, significantly lowering the barrier to entry for web scraping.
- Open-Source Remains Powerful: Despite AI advancements, traditional open-source tools like Scrapy and Beautiful Soup continue to be vital for developers needing high customization, control, and scalability for complex projects.
- Hybrid Approaches Emerge: The trend is towards combining AI's ease of use with the robustness of existing libraries, enabling more efficient and sophisticated data extraction workflows, even for dynamic and complex websites.
The Dawn of AI-Powered Web Scraping: Google Gemini 2.0
As of May 2025, the landscape of web scraping is undergoing a significant transformation, largely driven by advancements in Artificial Intelligence. Extracting data from websites, once a task predominantly for those with coding expertise, is becoming increasingly accessible. Google Gemini 2.0 stands at the forefront of this evolution, offering an intuitive, AI-driven method to gather information from the web.
Conceptual image illustrating the ease of web scraping with AI like Google Gemini 2.0.
What Makes Google Gemini 2.0 a Game-Changer?
Google Gemini 2.0 is an advanced multimodal AI model that can understand and process information from webpages much like a human. This allows it to interpret complex layouts, dynamic content loaded with JavaScript, and unstructured data, translating it all into structured formats (e.g., JSON, CSV) with remarkable ease. Its primary appeal lies in its ability to perform web scraping tasks based on natural language instructions, often eliminating the need for users to write any code.
Core Features and Advantages:
- No-Code/Low-Code Operation: Users can often initiate scraping tasks by simply telling Gemini what data to extract, either through text prompts or even voice commands when integrated with appropriate interfaces. This significantly democratizes data extraction.
- Multimodal Understanding: Gemini combines Natural Language Processing (NLP) with computer vision capabilities to parse diverse web elements, including text, tables, lists, and sometimes even image-related data.
- Dynamic Content Handling: It's designed to tackle modern websites that rely heavily on JavaScript (AJAX, Single Page Applications - SPAs) to load content, a common hurdle for simpler scraping tools.
- AI-Powered Adaptability: The AI can often adapt to minor changes in website structure, reducing the maintenance overhead that plagues traditional scrapers.
- Structured Output: Gemini can directly provide data in organized formats like JSON or CSV, ready for analysis or integration into other systems.
- Accessibility: Google typically provides access to Gemini models via APIs (like the Google AI Python SDK) and user-friendly interfaces like Google AI Studio, often with a free tier for experimentation and smaller tasks.
Step-by-Step: Easy Web Scraping with Google Gemini 2.0
While specific interfaces might vary, the general workflow for using Gemini 2.0 for web scraping, particularly for users preferring ease, involves the following steps:
-
Access and Setup:
Obtain access to Gemini, typically through Google AI Studio (requiring a Google account and generating an API key) or by using the Google AI Python SDK. For no-code approaches, an interface allowing direct prompting or screen sharing (as described in some scenarios for voice commands) would be used.
-
Define Your Target and Data:
Clearly identify the URL of the webpage you wish to scrape. Formulate a precise natural language prompt detailing the specific information you need. For example: "Extract all product names, their prices, and customer ratings from this webpage: [URL]. Provide the output as a JSON list."
-
Execute the Scraping Task:
No-Code/Voice Command: If using a direct interface, you might share your screen and verbally instruct Gemini (e.g., "Scrape the restaurant names and addresses visible on this map area").
Via API (e.g., Python): For more programmatic control or integration into scripts, you'd use the API. This might involve fetching the page content first (potentially with a library like
requestsandBeautifulSoupfor initial HTML parsing) and then feeding it to Gemini.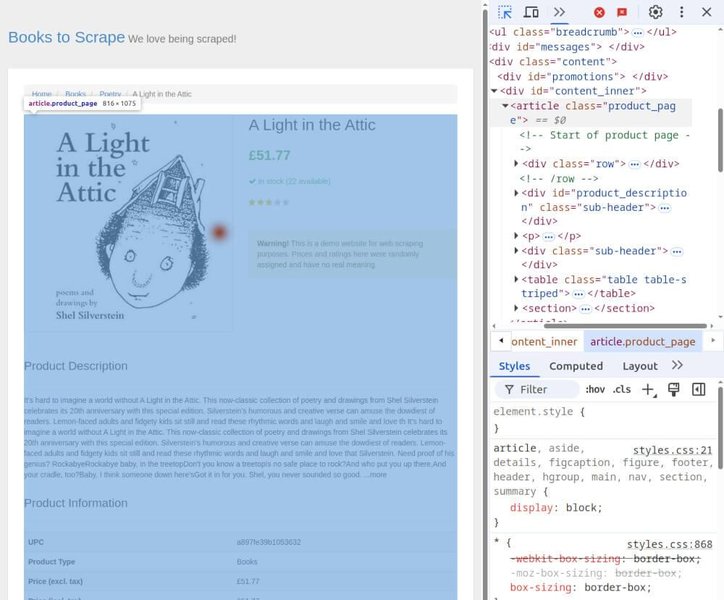
Understanding basic HTML structure can help in formulating precise prompts for Gemini.
Here’s a conceptual Python snippet illustrating an API call:
# Python example using the Google AI SDK import google.generativeai as genai import requests from bs4 import BeautifulSoup # Configure your API key genai.configure(api_key="YOUR_API_KEY") # Replace with your actual API key # Target URL url = "https://example-ecommerce-site.com/products" # Replace with the target URL try: response = requests.get(url, timeout=10) response.raise_for_status() # Ensure the request was successful soup = BeautifulSoup(response.content, "html.parser") page_text_content = soup.get_text(separator='\\n', strip=True) # Extract text for context # Initialize the Gemini model # Ensure you use a model version that supports your intended use case, e.g., "gemini-1.5-flash" or "gemini-pro" # The exact model name might vary; refer to Google's documentation for the latest. # For this example, let's assume a generic model name "gemini-2.0-flash-lite" as mentioned in one source. # In practice, use "gemini-1.5-flash-latest" or similar as per current Google AI documentation. model = genai.GenerativeModel("gemini-1.5-flash-latest") # Use an appropriate model name # Craft the prompt prompt = f""" Given the following text content from the webpage {url}: --- {page_text_content[:4000]} # Provide a snippet of text content --- Please extract all product names, their corresponding prices, and customer review scores. Return the data as a JSON array, where each object has 'product_name', 'price', and 'review_score' keys. If a piece of information is not available for an item, use null for its value. Example: [{{ "product_name": "Example Product", "price": "$19.99", "review_score": 4.5 }}] """ # Generate content gemini_response = model.generate_content(prompt) print(gemini_response.text) except requests.exceptions.RequestException as e: print(f"Error fetching URL: {e}") except Exception as e: print(f"An error occurred: {e}")Note: The Python code above is conceptual. Ensure you have the `google-generativeai`, `requests`, and `beautifulsoup4` libraries installed (`pip install google-generativeai requests beautifulsoup4`). Always refer to the latest Google AI documentation for model names and API usage.
-
Review and Utilize Data:
Gemini will return the extracted data, typically in your specified format (e.g., JSON). Review this output for accuracy. You can then parse this data for analysis, storage, or further processing.
Potential Limitations:
- API Limits and Costs: While free tiers are often available, extensive use or access to the most powerful models might incur costs or be subject to rate limits.
- Accuracy on Highly Complex Sites: For extremely convoluted or heavily protected websites, AI interpretation might still face challenges or yield inaccuracies. Human oversight is often recommended.
- Ethical and Legal Constraints: Web scraping must always be conducted responsibly, respecting website `robots.txt` files, terms of service, and legal regulations like GDPR or CCPA.
Alternative Web Scraping Strategies: The Free & Open-Source Toolkit
While Google Gemini 2.0 offers a compelling easy-to-use solution, a rich ecosystem of free and open-source web scraping tools continues to thrive. These alternatives cater to various needs, particularly for users who require more control, customization, or work on large-scale, budget-constrained projects.

The open-source community provides a wealth of powerful web scraping tools for various needs in 2025.
1. Scrapy (Python Framework)
Scrapy is a powerful and flexible open-source web crawling and scraping framework written in Python. It's designed for efficiency and can handle large-scale projects, including complex crawling logic, data processing pipelines, and more.
- Pros: Highly extensible, asynchronous processing for speed, built-in support for exporting data (JSON, CSV, XML), robust middleware and pipeline architecture.
- Cons: Steeper learning curve than no-code tools; requires Python programming knowledge.
- Best For: Developers building custom crawlers, large-scale data extraction, and projects requiring fine-grained control.
2. Beautiful Soup (Python Library)
Beautiful Soup is a Python library designed for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It's often used in conjunction with the `requests` library (to fetch web pages).
- Pros: Relatively easy to learn for basic HTML parsing, great for beginners in Python web scraping, flexible.
- Cons: Not a complete scraping framework (needs `requests` or similar for fetching pages), less efficient for very large projects or complex JavaScript-heavy sites on its own.
- Best For: Smaller projects, parsing static HTML content, learning web scraping fundamentals.
3. Apify SDK (JavaScript/Node.js)
The Apify SDK is an open-source library for building reliable and scalable web crawlers and scrapers in Node.js. It provides tools for managing concurrency, proxies, and browser automation (e.g., via Puppeteer or Playwright).
- Pros: Excellent for handling JavaScript-rendered websites, scalable, good for developers in the JavaScript ecosystem, integrates with the Apify platform for deployment and scheduling (though the SDK itself is open source).
- Cons: Requires JavaScript/Node.js knowledge.
- Best For: Scraping modern web applications, developers comfortable with JavaScript, projects needing robust browser automation.
4. Selenium (Browser Automation)
Selenium is primarily a browser automation framework. While not exclusively a scraping tool, it's widely used for scraping dynamic websites that heavily rely on JavaScript to load content by simulating user interactions within a web browser.
- Pros: Can interact with virtually any web element like a human user (clicking buttons, filling forms), excellent for JavaScript-heavy sites. Bindings for various languages (Python, Java, C#, etc.).
- Cons: Can be slower and more resource-intensive than direct HTTP request-based scrapers like Scrapy due to full browser rendering.
- Best For: Scraping sites with complex user interactions or heavy JavaScript, end-to-end testing that includes data extraction.
5. No-Code/Visual Scraping Tools (with Free Tiers)
Several tools offer a visual, point-and-click interface for web scraping, often with generous free tiers that are suitable for smaller tasks or learning.
- ParseHub: Offers a desktop application with a free plan for a limited number of projects. It can handle dynamic content, forms, and pagination through a visual interface.
- Octoparse: Provides both cloud-based and desktop solutions with a free tier. It features AI-powered data recognition and templates for common scraping scenarios.
- Webscraper.io: A browser extension that allows users to set up scraping sitemaps with a point-and-click interface. The free version runs locally in your browser.
These tools are excellent for non-programmers or for quickly prototyping scraping tasks.
6. Emerging AI-Integrated Open-Source Tools
Projects like Firecrawl and Crawl4AI are examples of newer open-source initiatives (as of early 2025) that aim to combine traditional crawling techniques with AI models (like LLMs) for more intelligent data extraction and structuring. These often build upon existing libraries or offer SDKs to integrate AI into the scraping workflow, providing a middle ground between fully manual coding and purely AI-driven tools like Gemini.
Comparative Analysis: Gemini 2.0 vs. Alternatives
Choosing the right web scraping strategy depends on your technical skills, project complexity, scale, and specific requirements. The table below provides a comparative overview:
| Tool/Strategy | Coding Required | AI/ML Features | Dynamic Content Handling | Free/Open Source Status | Ease of Use (Beginner) | Best For |
|---|---|---|---|---|---|---|
| Google Gemini 2.0 | No (Primarily) / Low (API) | Advanced (Built-in NLP, Vision) | Excellent (Designed for JS/AJAX) | Free tier usually available; Core tech is proprietary | Very Easy | Non-coders, rapid extraction, complex dynamic sites via natural language |
| Scrapy | Yes (Python) | Manual integration possible | Good (via middlewares like Splash, or Selenium integration) | Yes (Open Source) | Difficult | Developers, large-scale & highly customized projects, efficient crawling |
| Beautiful Soup (with Requests) | Yes (Python) | No (Primarily a parser) | Poor (for dynamic sites, needs Selenium/Playwright) | Yes (Open Source) | Easy (for basics) | Small projects, static HTML parsing, learning fundamentals |
| Apify SDK | Yes (JavaScript/Node.js) | Can integrate AI models | Excellent (via headless browsers) | Yes (Open Source SDK) | Moderate | JS developers, scalable scraping of modern web apps |
| Selenium | Yes (Python, Java, etc.) | No (Automation tool) | Excellent (Full browser interaction) | Yes (Open Source) | Moderate | Complex interactions, sites heavily reliant on JavaScript not easily handled by other tools |
| No-Code Visual Tools (e.g., ParseHub, Octoparse - Free Tiers) | No | Basic AI (e.g., element detection, templates in some) | Good to Very Good | Free tier with limitations; Core platforms often commercial | Easy to Very Easy | Non-coders, visual setup, quick extraction from moderately complex sites |
| Firecrawl / Crawl4AI | Yes (Typically SDKs) | Yes (Core to their design, integrating LLMs) | Good (Often leverages underlying browser automation) | Yes (Open Source) | Moderate | Developers wanting AI-enhanced structured data extraction from crawled content |
Visualizing Scraper Capabilities: A Comparative Radar Chart
To better understand the strengths of different web scraping approaches, the following radar chart compares Google Gemini 2.0 (Easy Mode), Scrapy, Beautiful Soup (with Requests), and a representative No-Code Tool (like Octoparse's free tier) across several key attributes. Scores are on a scale of 1 (Low) to 5 (High). For 'Learning Curve', a higher score indicates an *easier* curve (less steep).
This chart visually represents how different tools cater to different priorities. Gemini 2.0 excels in ease of use and AI capabilities for straightforward tasks, while Scrapy offers unparalleled power and scalability for developers. No-code tools provide a user-friendly entry point, and Beautiful Soup is great for simpler, static parsing tasks.
Navigating the Web Scraping Landscape: A Mindmap
The world of web scraping involves various tools, techniques, and considerations. This mindmap provides a high-level overview to help you understand the ecosystem, with Google Gemini 2.0 as a key player in the evolving AI-driven scraping domain.
This mindmap highlights that while Gemini 2.0 simplifies many aspects, a diverse range of tools and important ethical and technical considerations remain crucial in the field of web scraping.
Watch & Learn: Gemini 2.0 Web Scraping Tutorial
For a practical demonstration of how Google Gemini 2.0 can be used for real-time web scraping and data extraction, the following video provides a helpful tutorial. It showcases the ease with which data can be extracted, aligning with the "easy web scraping" focus of your query.
This tutorial, "Scrape Any Website EASILY using Google Gemini 2.0," illustrates the practical application of Gemini's capabilities, showing how users can leverage its AI to simplify the data extraction process from various websites without needing to delve into complex coding.
Frequently Asked Questions (FAQ)
Recommended Further Exploration
- How can I integrate Google Gemini 2.0 with Python for automated daily web scraping tasks?
- What are the best practices for handling anti-scraping measures when using open-source tools like Scrapy in 2025?
- Compare the costs and benefits of using AI-driven scraping services versus building an in-house scraping solution with open-source libraries.
- Explore advanced techniques for scraping JavaScript-heavy single-page applications (SPAs) using tools like Apify SDK or Selenium.
References
Last updated May 8, 2025