
Approfondimento sulle Generative Adversarial Networks (GAN)
Esplorazione completa delle GAN, delle loro instabilità e delle varianti avanzate
Principali Punti Chiave
- Struttura delle GAN: Composte da un generatore e un discriminatore che competono in un processo di addestramento.
- Instabilità delle GAN: Derivano principalmente dallo squilibrio tra le due reti, problemi di convergenza e fenomeni come la mode collapse.
- Varianti Avanzate: Le Relativistic Pairing GAN (RpGAN) introducono approcci relativistici per migliorare la stabilità e la diversità dei dati generati.
1. Cosa sono le Generative Adversarial Networks (GAN)?
Definizione e Struttura di Base
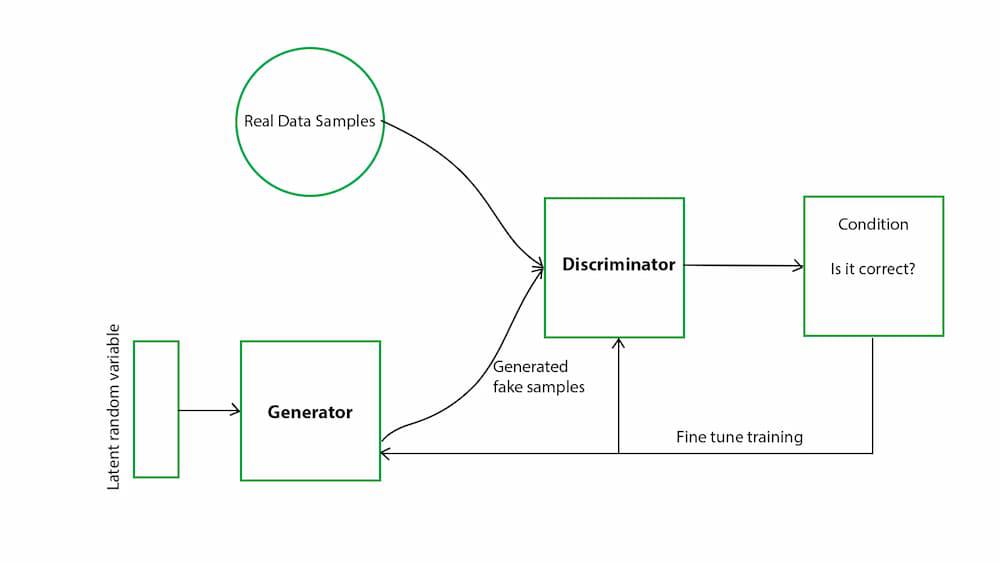
Le Generative Adversarial Networks (GAN) rappresentano una classe di modelli di apprendimento automatico introdotta da Ian Goodfellow e colleghi nel 2014. Le GAN sono progettate per generare nuovi dati che imitano quelli presenti in un dataset di addestramento, risultando particolarmente efficaci nella creazione di immagini, testi e altri tipi di dati complessi.
Una GAN è composta da due reti neurali principali:
- Generatore (G): Il generatore ha il compito di creare dati sintetici a partire da un input casuale o da una distribuzione di rumore. La sua missione è produrre dati che siano indistinguibili dai dati reali presenti nel dataset.
- Discriminatore (D): Il discriminatore valuta i dati in entrata, cercando di distinguere tra dati reali e dati generati dal generatore. Fornisce feedback al generatore sulla qualità dei dati sintetici prodotti.
Il processo di addestramento delle GAN è un gioco minmax, in cui il generatore cerca di "ingannare" il discriminatore, mentre quest'ultimo cerca di migliorare la sua capacità di distinguere i dati reali da quelli sintetici. Questo rapporto competitivo continua fino a quando il generatore produce dati che il discriminatore non riesce più a distinguere dai dati reali.
2. Perché le GAN rischiano di essere instabili?
Cause Principali dell'Instabilità
Nonostante la loro potenza, le GAN sono note per essere difficili da addestrare a causa di diverse sfide intrinseche al loro funzionamento competitivo:
a. Squilibrio tra Generatore e Discriminatore
Un squilibrio nella capacità delle due reti neurali può portare a problemi significativi durante l'addestramento. Se il discriminatore diventa troppo potente rispetto al generatore, il generatore può avere difficoltà a migliorare, poiché il discriminatore fornisce un feedback troppo severo. Al contrario, se il generatore è troppo forte, il discriminatore potrebbe non essere in grado di fornire feedback utili, impedendo al sistema di apprendere in modo efficace.
b. Problemi di Convergenza
Le GAN spesso non convergono a un equilibrio stabile. Le oscillazioni tra il miglioramento del generatore e del discriminatore possono portare a divergenze nel processo di addestramento, impedendo al modello di raggiungere un punto in cui il generatore produce dati realistici.
c. Mode Collapse
La mode collapse è un problema specifico delle GAN in cui il generatore inizia a produrre un insieme limitato di output, riducendo la diversità dei dati sintetici. Questo accade quando il generatore scopre che alcuni output sono particolarmente efficaci nell'ingannare il discriminatore e si concentra esclusivamente su di essi, ignorando altre modalità presenti nei dati reali.
d. Oscillazioni durante l'Addestramento
Il comportamento oscillante durante l'addestramento può impedire alle GAN di raggiungere una soluzione stabile. Piccoli cambiamenti nell'aggiornamento dei pesi possono destabilizzare l'equilibrio tra le due reti, portando a fluttuazioni nella qualità dei dati generati.
3. Cosa è la "Mode Collapse"?
Definizione e Implicazioni
La mode collapse è un fenomeno in cui il generatore di una GAN inizia a produrre un numero limitato di output, spesso ripetendo gli stessi dati o una piccola varietà di essi. Questo compromette la diversità e la qualità dei dati generati, rendendo il modello meno utile per compiti che richiedono una varietà elevata.
Esempio Pratico
Consideriamo una GAN addestrata per generare immagini di volti umani. In caso di mode collapse, il generatore potrebbe produrre solo volti molto simili tra loro, ignorando la varietà naturale dei volti reali in termini di età, sesso, espressioni e altre caratteristiche. Questo riduce drasticamente l'efficacia del modello nel catturare la reale distribuzione dei dati.
Cause della Mode Collapse
Il generatore può finire per concentrarsi su un sottoinsieme di output che riesce a ingannare efficacemente il discriminatore, trascurando altre modalità della distribuzione dei dati reali. Questo accade perché il generatore tenta di massimizzare il suo guadagno cercando di sfruttare le debolezze del discriminatore.
Conseguenze della Mode Collapse
La principal conseguenza della mode collapse è la perdita di diversità nei dati generati, che può limitare l'utilizzo delle GAN in applicazioni pratiche dove la varietà è cruciale, come nella generazione di immagini realistiche, nella progettazione di nuovi farmaci o nella creazione di sintesi vocali personalizzate.
4. Cosa è "l'Objective" di una GAN?
Funzione di Perdita e Gioco Minimax
L'objective di una GAN è definito dalla funzione di perdita che guida l'addestramento delle due reti neurali, generatore e discriminatore. Questo obiettivo è formulato come un gioco minmax, dove il generatore e il discriminatore cercano di ottimizzare la loro funzione di perdita in direzioni opposte.
Formalmente, l'obiettivo può essere espresso come:
$$ \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))] $$
In questa formulazione:
- Discriminatore (D): Cerca di massimizzare la probabilità di assegnare la label corretta ai dati reali e falsi, massimizzando $$\log D(x)$$ per dati reali e $$\log(1 - D(G(z)))$$ per dati generati.
- Generatore (G): Cerca di minimizzare $$\log(1 - D(G(z)))$$, ovvero di ingannare il discriminatore in modo che classifichi i dati generati come reali.
Questa interazione crea un equilibrio dinamico in cui il generatore migliora progressivamente nella produzione di dati realistici, mentre il discriminatore affina la sua capacità di distinguere tra dati reali e sintetici.
5. Cosa è la "Training Loss"?
Metrica di Performance Durante l'Addestramento
La training loss rappresenta la metrica che misura quanto bene il modello sta performando durante l'addestramento. Nelle GAN, ci sono due tipi principali di perdite:
a. Perdita del Generatore
La perdita del generatore misura quanto efficacemente il generatore riesce a ingannare il discriminatore. Formalmente, è definita come $$\log(1 - D(G(z)))$$, dove l'obiettivo del generatore è minimizzare questa perdita. In pratica, ciò significa che il generatore cerca di produrre dati che il discriminatore classifichi come reali.
b. Perdita del Discriminatore
La perdita del discriminatore misura la sua capacità di distinguere correttamente tra dati reali e dati generati. È definita come $$\log D(x) + \log(1 - D(G(z)))$$, e il suo obiettivo è massimizzare questa funzione. Un discriminatore efficace assegnerà alte probabilità ai dati reali e basse probabilità ai dati sintetici.
c. Interpretazione e Limiti della Training Loss
Interpretare la training loss nelle GAN può essere complesso. Una bassa perdita del generatore non garantisce necessariamente che i dati sintetici siano di alta qualità; potrebbe semplicemente indicare che il generatore sta attualmente ingannando il discriminatore in modo efficace. Inoltre, la perdita del discriminatore non sempre riflette direttamente la qualità dei dati reali, specialmente se il discriminatore diventa troppo potente o troppo debole rispetto al generatore.
d. Monitoraggio della Training Loss
Durante l'addestramento, è cruciale monitorare entrambe le perdite per assicurarsi che nessuna delle due reti diventi troppo dominante. Un equilibrio sottile tra la perdita del generatore e quella del discriminatore è essenziale per un addestramento efficace e per evitare problemi come la mode collapse.
6. Cosa è la Relativistic Pairing GAN (RpGAN)?
Una Variante Avanzata delle GAN per Migliorare la Stabilità
La Relativistic Pairing GAN (RpGAN) è una delle numerose varianti delle GAN concepite per affrontare le sfide di instabilità e mode collapse riscontrate nelle GAN tradizionali. Le RpGAN introducono un approccio relativistico nella funzione di perdita del discriminatore, contribuendo a bilanciare meglio le due reti e a migliorare la diversità dei dati generati.
a. Differenze Principali rispetto alle GAN Tradizionali
Nelle GAN tradizionali, il discriminatore valuta ogni campione in modo indipendente, assegnando una probabilità che un dato sia reale o sintetico. Nell'RpGAN, invece, il discriminatore valuta la probabilità che un dato reale sia più realistico di un dato generato, considerando coppie di dati relativi anziché campioni singoli.
b. Vantaggi delle RpGAN
Introducendo un approccio relativistico, le RpGAN riescono a:
-
Migliorare la Stabilità dell'Addestramento: Bilanciando meglio il feedback tra generatore e discriminatore, riducono la probabilità di oscillazioni e divergenze durante l'addestramento.
-
Ridurre il Mode Collapse: L'approccio relativistico incoraggia il generatore a produrre una maggiore varietà di dati, poiché deve considerare come i dati sintetici si posizionano rispetto ai dati reali.
-
Aumentare la Diversità dei Dati Generati: Le RpGAN favoriscono un miglior equilibrio nella produzione di dati sintetici, aumentando la diversità e realisticità dei risultati.
c. Funzione di Perdita nelle RpGAN
La funzione di perdita nelle RpGAN è modificata per valutare la relatività tra dati reali e sintetici. Questo significa che il discriminatore non assegna solo una probabilità a ciascun campione, ma valuta anche come un dato reale si confronta con quelli sintetici. Questa valutazione relativa fornisce un feedback più ricco e bilanciato al generatore, facilitandone l'apprendimento e migliorando la qualità dei dati generati.
d. Implementazione delle RpGAN
// Esempio di implementazione della perdita relativistica nel discriminatore
def relativistic_discriminator_loss(real_output, fake_output):
real_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=real_output - tf.reduce_mean(fake_output), labels=tf.ones_like(real_output)))
fake_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=fake_output - tf.reduce_mean(real_output), labels=tf.zeros_like(fake_output)))
return real_loss + fake_loss
In questo esempio, la funzione di perdita valuta la differenza tra le uscite del discriminatore per dati reali e sintetici, incentivando il discriminatore a dare una valutazione comparativa piuttosto che assoluta.
Conclusione
Le Generative Adversarial Networks (GAN) rappresentano uno degli strumenti più potenti nel campo dell'apprendimento automatico per la generazione di dati sintetici realistici. Tuttavia, il loro addestramento comporta sfide significative legate all'instabilità e a fenomeni come la mode collapse. Varianti avanzate come le Relativistic Pairing GAN (RpGAN) offrono soluzioni promettenti, migliorando la stabilità dell'addestramento e la diversità dei dati generati. Comprendere le dinamiche interne delle GAN e le sfide che affrontano è cruciale per sviluppare applicazioni efficaci e innovative in una vasta gamma di settori, dalla generazione di immagini realistiche alla sintesi di dati per applicazioni scientifiche e industriali.
Riferimenti
Last updated January 21, 2025