
生成AIの性能を徹底比較:最適なベンチマークサイト完全ガイド
多様な評価基準を提供する主要なAIベンチマークサイトを網羅的にご紹介します。
ハイライト
- 多様なベンチマークの存在: 一般的なLLMリーダーボードから、特定のタスク(コーディング、ツール使用)、ハードウェア性能、日本語能力に特化したサイトまで、多種多様なベンチマークが存在します。
- 重要な評価指標: AIモデルの評価には、精度、速度、コストといった基本的な指標に加え、コンテキストウィンドウの大きさ、多言語対応能力、推論能力、特定の応用分野での性能などが考慮されます。
- 主要なリソース: Artificial AnalysisやLLM Leaderboardのような総合比較サイト、MLPerfやGeekbench AIのような技術的ベンチマーク、JGLUEのような言語特化ベンチマークなど、目的に応じて参照すべきサイトが異なります。
主要なLLMリーダーボードと総合比較プラットフォーム
大規模言語モデル(LLM)の性能を多角的に比較・評価できる主要なウェブサイトを紹介します。これらのサイトは、モデル選択の重要な判断材料となります。
Artificial Analysis
品質、価格、出力速度、遅延、コンテキストウィンドウといった主要なパフォーマンス指標に基づいてAIモデルを比較・分析できるプラットフォームです。個々のモデルをクリックすると、さらに詳細なメトリクスを確認できます。LLM APIプロバイダーのリーダーボードも提供しています。
LLM Leaderboard (llm-stats.com)
最新の大規模言語モデル(LLM)のパフォーマンスを評価し、ランキング形式で表示するサイトです。速度、品質、コスト、機能など、複数の指標に基づいてGPT-4o、Llama、Geminiなどの主要モデルを比較検討できます。
RankedAI.co
モデルのリリースから数時間以内に情報を追加することを目指しており、鮮度の高い情報が特徴です。20以上のベンチマーク結果に加え、リリース日、モデルサイズ、コンテキスト長、知識カットオフ日、コスト、ライセンスタイプといった詳細情報も提供しています。
Generative AI Models Leaderboard (Accubits)
複数の生成AIモデルを比較するためのランキングサイトです。様々な性能指標に基づいてモデルを評価しており、業界全体のトレンドを把握するのに役立ちます。
benchmarks.ai
多数のベンチマーク、メソッド、結果を集約したAIベンチマークのディレクトリサイトです。特定のタスクやデータセットに対するモデルの性能を横断的に調査する際に便利です。
専門ベンチマークスイートとタスク特化評価
特定のタスクや能力、あるいは学術的な評価基準に基づいてAIモデルの性能を深く掘り下げるためのベンチマークスイートや分析レポートを紹介します。
MLPerf
AIモデルの推論性能を測定するための業界標準ベンチマークの一つです。NVIDIAなどが参画し、様々なタスクとモデルを対象としており、特にハードウェア上での実行性能評価に重点を置いています。
Epoch AI - AI Benchmarking Dashboard
GPQA DiamondやMATH Level 5といった学術的なベンチマークを含む、多数のテストにおけるAIモデルのパフォーマンスデータを収集し、リアルタイムに近い形で結果を表示するダッシュボードです。研究動向の把握に適しています。
Vellum.ai Blog Analysis
ブログ記事形式で、主要なLLMモデルのランキングや性能分析を提供しています。例えば、Claude 3.5 Sonnetが多言語(MGSM)、ツール使用(BFCL)、コード(HumanEval)などのカテゴリで高い性能を示しているといった具体的な分析が見られます。
Salesforce AI Research - LLM Benchmark for CRM
Salesforceが提供する、CRM(顧客関係管理)データに基づいたLLM評価ベンチマークです。実際のビジネスシナリオ、特に顧客対応や営業支援といった文脈でのモデル性能を評価する点でユニークです。
タスク特化ベンチマーク
WebArena
AIがウェブサイト上で指定されたタスク(情報の検索、フォームへの入力、予約など)を自律的に実行できるかを測定します。実世界での応用能力を評価する指標となります。
ToolBench
AIが外部のツールやAPIを適切に理解し、利用できるかを評価するベンチマークです。複数のツールを組み合わせる複雑なタスクの実行能力を測ります。
MC-BENCH
最新のAI言語モデルのパフォーマンスを比較するために設計された無料のベンチマークツールです。
AIモデルの多角的性能比較(レーダーチャート)
主要なAIモデルの能力を視覚的に比較するために、いくつかの重要な側面から評価したレーダーチャートを示します。このチャートは、各モデルの強みと弱みを相対的に理解するのに役立ちます。スコアは一般的な評価や公開されているベンチマーク結果に基づいた相対的なものであり、特定のタスクにおける絶対的な性能を示すものではありません。
AIベンチマークの世界:全体像(マインドマップ)
AIベンチマークは多岐にわたります。以下のマインドマップは、ベンチマークの種類、評価される主要な指標、そして代表的なプラットフォームを整理し、その全体像を把握する手助けとなります。
(World of AI Benchmarking)"] ["ベンチマークの種類
(Types of Benchmarks)"] ["大規模言語モデル (LLMs)"] ["ハードウェア (Hardware)"] ["特定タスク (Specific Tasks)"] ["例: コーディング、ツール使用
(e.g., Coding, Tool Use)"] ["言語特化 (Language-Specific)"] ["例: 日本語 (e.g., Japanese)"] ["主要な評価指標
(Key Metrics)"] ["パフォーマンス (Performance)"] ["精度、速度、遅延
(Accuracy, Speed, Latency)"] ["コスト (Cost)"] ["機能 (Features)"] ["コンテキストウィンドウ、API
(Context Window, API)"] ["能力 (Capabilities)"] ["推論、創造性
(Reasoning, Creativity)"] ["代表的なプラットフォーム
(Popular Platforms)"] ["Artificial Analysis"] ["LLM Leaderboard"] ["Epoch AI"] ["MLPerf"] ["Geekbench AI"] ["日本語ベンチマーク (JGLUEなど)
(Japanese Benchmarks (JGLUE, etc.))"]
ハードウェア性能評価ベンチマーク
AIモデルの性能は、それを実行するハードウェア(CPU, GPU, NPUなど)にも大きく依存します。ここでは、デバイスやインフラのAI処理能力を測定するためのベンチマークを紹介します。
Geekbench AI
CPU、GPU、NPU(Neural Processing Unit)のAIパフォーマンスを評価するためのクロスプラットフォーム(Windows, macOS, iOS, Androidなど)対応ベンチマークです。デバイス間でのAI処理能力比較に利用されます。
AI-Benchmark
主にスマートフォンやIoTデバイスのAIパフォーマンスを評価するために設計されたツールです。モバイルデバイス上での機械学習タスクの実行速度や効率を測定します。
CUDO Compute GPU Benchmarks
特にGPU(Graphics Processing Unit)を用いたAI計算のパフォーマンス評価に焦点を当てたベンチマークスイートです。ディープラーニングなどのGPU負荷が高いタスクにおける性能比較に役立ちます。
AIBench
データセンター、HPC(High-Performance Computing)、IoT、エッジコンピューティング環境向けに設計された、スケーラブルで包括的なAIベンチマークスイートです。様々な規模のシステムにおけるAIワークロード性能を評価します。
日本語特化型生成AIベンチマーク
日本語のニュアンスや文脈を正確に捉え、処理する能力は、グローバルなモデル評価だけでは測りきれない側面があります。以下は、日本語に特化した評価を行う主要なベンチマークです。
- JGLUE (Japanese General Language Understanding Evaluation): 早稲田大学とLINEヤフー株式会社によって作成された、日本語の総合的な言語理解能力を評価するためのベンチマーク。
- Rakuda: YuzuAIの有志グループが考案・運用するベンチマーク。評価プロセスにGPT-4が用いられる点が特徴です。
- Japanese MT-Bench: Stability AIが提供する、対話型AIの性能を評価するMT-Benchの日本語版。
- LLM-jp-eval: 国立情報学研究所を中心としたLLM-jpプロジェクトが提供する、日本語LLMの評価基盤。
- ELYZA-task-100: 東京大学松尾研究室発のスタートアップELYZAが提供する、日本語の指示実行能力を評価するためのタスクセット。
主要AIベンチマークプラットフォーム概要
様々なAIベンチマークサイトとその特徴を一覧表にまとめました。目的や評価したい側面に応じて、最適なプラットフォームを選択するための参考にしてください。
| プラットフォーム名 | 主な焦点 | 主な評価指標・特徴 |
|---|---|---|
| Artificial Analysis | LLM比較(総合) | 品質、価格、速度、遅延、コンテキストウィンドウ、APIプロバイダー評価 |
| LLM Leaderboard (llm-stats.com) | LLM比較(ランキング) | 速度、品質、コスト、機能、主要モデル(GPT, Llama, Gemini等)比較 |
| Epoch AI Dashboard | 学術ベンチマーク集約 | GPQA, MATHなど多数のベンチマーク結果、研究動向 |
| RankedAI.co | 最新LLM情報 | 迅速な情報更新、20+ベンチマーク、モデル詳細(サイズ、リリース日、ライセンス等) |
| MLPerf | 推論・学習性能(業界標準) | ハードウェア上での実行速度、効率性(NVIDIAなどが推進) |
| Geekbench AI | デバイスAI性能 | CPU, GPU, NPU性能、クロスプラットフォーム比較 |
| AI-Benchmark | モバイル/IoT AI性能 | スマートフォン等でのAIタスク実行速度・効率 |
| Japanese Benchmarks (JGLUE, Rakuda, etc.) | 日本語能力評価 | 日本語理解、対話能力、指示実行能力など |
| Salesforce CRM Benchmark | CRM応用性能 | ビジネスシナリオ(顧客対応等)でのLLM性能 |
| Catchpoint Gen AI Benchmark | ツール性能(企業利用) | 応答時間、可用性など、実用面での性能 |
視覚的な洞察:AIベンチマーク関連画像
AIの性能評価やベンチマークは、しばしばグラフや図を用いて視覚化されます。以下の画像は、ベンチマーク結果の表示例や、AIモデルを動作させるハードウェア、そしてAI技術の進化を示すチャートなど、この分野の理解を深めるための視覚的な補助資料となります。
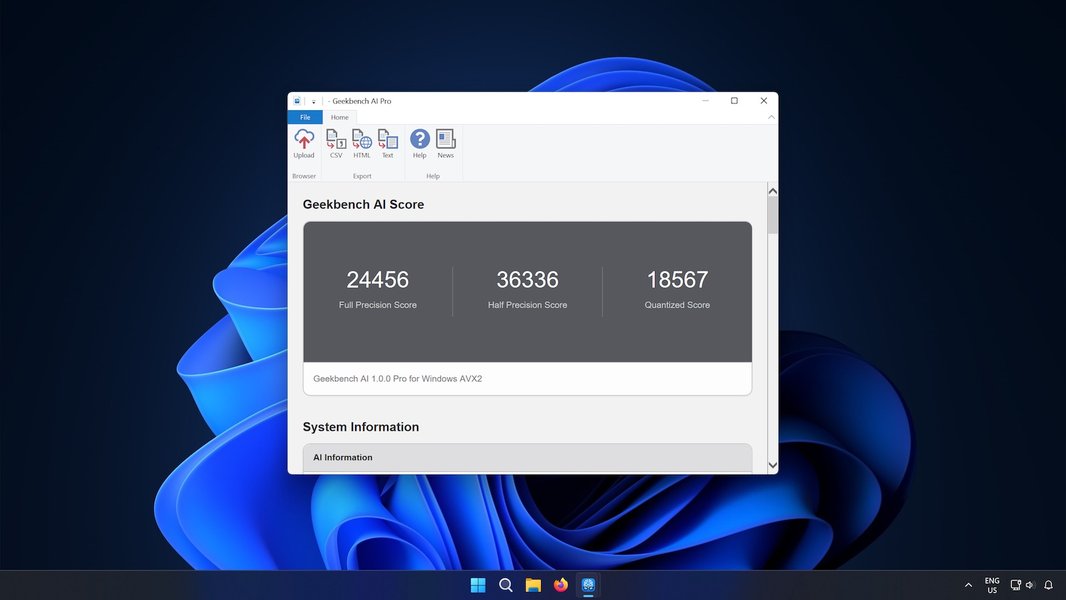
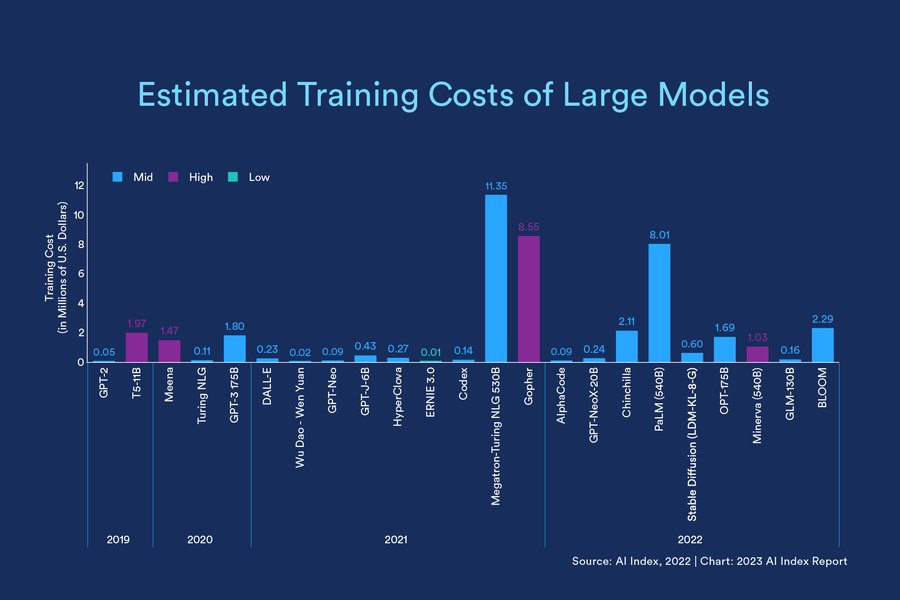
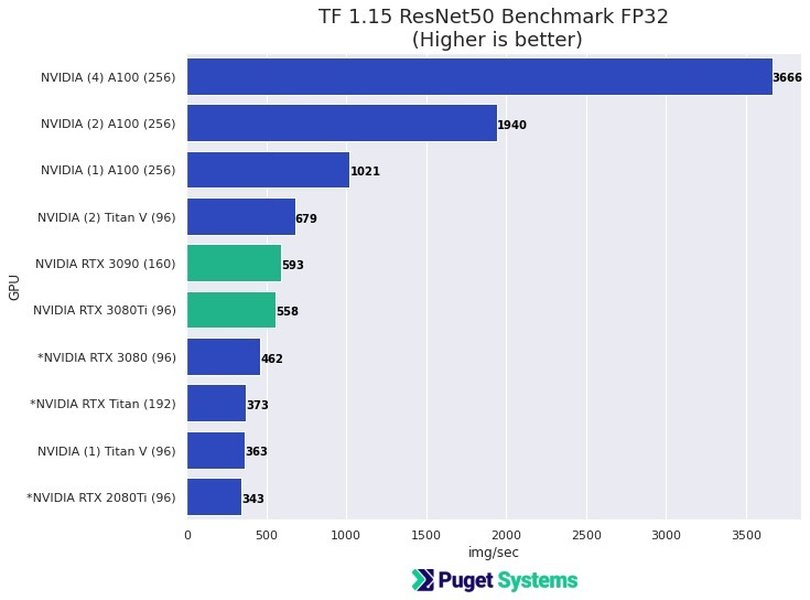
これらの画像は、Geekbenchのようなツールがどのように結果を表示するか、スタンフォード大学のような研究機関がAIの進歩をどのように追跡しているか、リーダーボードがどのようにモデルをランク付けするか、そして高性能なAI計算に必要なハードウェアの種類を示唆しています。
ベンチマークの理解を深める:解説動画
AIモデルのベンチマークは複雑であり、その結果を正しく解釈するには背景知識が役立ちます。以下の動画は、トップAIモデルの比較やパフォーマンスデータに基づいたランキングについて解説しており、どのモデルが特定のプロジェクトに適しているかを判断する上で有益な情報を提供します。
この動画「The Best AI Models Ranked By REAL Performance Data 2025」では、画像生成やその他のタスクにおける主要なAIモデルが比較され、実際のパフォーマンスデータに基づいたランキングが示されています。ベンチマークサイトの情報を補完し、より実践的な視点を得るのに役立ちます。
よくある質問 (FAQ)
なぜAIベンチマークは重要ですか?
AIモデルの評価にはどのような指標が一般的に使われますか?
日本語に特化したAIベンチマークはありますか?
ベンチマークの結果はどのくらいの頻度で更新されますか?
ベンチマークはAIの性能の全てを捉えていますか?
参考文献
- Comparison of AI Models across Intelligence, Performance, Price - Artificial Analysis
- LLM Leaderboard 2025 - Verified AI Rankings - llm-stats.com
- AI Benchmarking Dashboard - Epoch AI
- LLM Benchmarks Overview, Limits, and Model Comparison - Vellum.ai Blog
- MLPerf AI Benchmarks - NVIDIA
- AI Benchmarks - Geekbench Browser
- AI Benchmark - Evaluate AI performance of your smartphone
- AIBench - BenchCouncil
- Generative AI Models Leaderboard - Accubits
- Gen AI Tool Performance Benchmark 2024 - Catchpoint
おすすめの検索
Last updated April 5, 2025