
Unlock a New Era of API Efficiency: A Deep Dive into GraphQL for REST Veterans
Discover how GraphQL revolutionizes data fetching, offering precision and flexibility beyond traditional REST APIs.
As an experienced software engineer familiar with REST APIs, you're well-positioned to appreciate the paradigm shift GraphQL offers. It's not merely an alternative but a powerful query language and server-side runtime designed to optimize data exchange between client and server. Let's explore its intricacies and how it compares to the RESTful approach you know.
Key Highlights of GraphQL
- Precise Data Fetching: Clients request exactly the data they need, eliminating over-fetching (receiving too much data) and under-fetching (requiring multiple API calls for related data), common challenges with REST.
- Single Endpoint: Unlike REST's multiple endpoints for different resources, GraphQL typically operates over a single endpoint, simplifying API management and client requests.
- Strongly Typed Schema: GraphQL APIs are defined by a schema that acts as a contract between client and server, enabling powerful developer tools, introspection, and validation.
Understanding the Core of GraphQL
GraphQL, developed by Facebook in 2012 and open-sourced in 2015, was conceived to address the evolving needs of complex applications, especially on mobile platforms where bandwidth and request efficiency are paramount. It has since been governed by the GraphQL Foundation, hosted by the Linux Foundation.
The Schema: Your API's Blueprint
At the heart of any GraphQL service is its schema. The schema is a comprehensive description of all the data that clients can query. It's defined using the GraphQL Schema Definition Language (SDL).
Key Components of a Schema:
- Types: These define the kinds of objects you can fetch from your service and what fields they have. Standard scalar types include
Int,Float,String,Boolean, andID. You also define custom object types (e.g.,User,Post). - Fields: These are the properties of an object type. For instance, a
Usertype might have fields likename(String) andage(Int). - Relationships: The schema defines how types are connected. For example, a
Usermight have a list ofPostobjects they've authored.
This strong type system allows for query validation before execution and enables powerful developer tools like auto-completion and documentation generation.
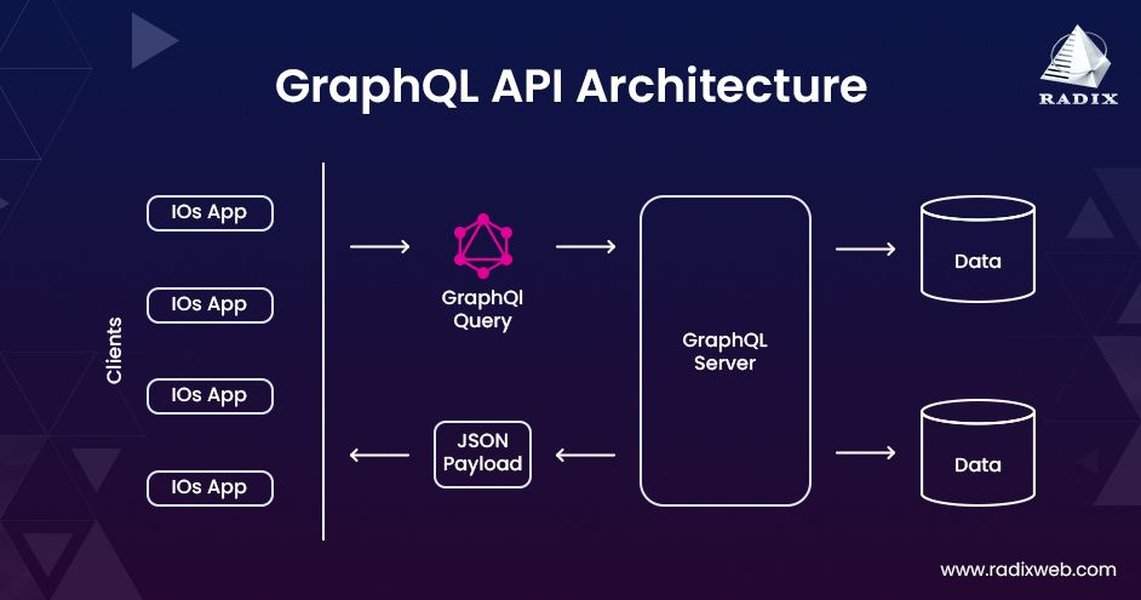
The Single Endpoint Philosophy
A significant departure from REST is GraphQL's use of a single endpoint (e.g., /graphql). All client requests (queries, mutations, subscriptions) are sent to this one URL, typically via HTTP POST. The specific operation and data requested are defined in the request payload, not by the URL path or HTTP verb.
Client-Specified Data: Ask for What You Need
GraphQL empowers clients to dictate the exact structure and content of the data they receive. This solves two common problems with REST APIs:
- Over-fetching: REST endpoints often return more data than the client needs. For example, a
/users/{id}endpoint might return all user attributes, even if the client only requires the user's name. - Under-fetching: To get all necessary data, clients often need to make multiple requests to different REST endpoints. For instance, fetching a user and their posts might require a call to
/users/{id}and then another to/users/{id}/posts. GraphQL can retrieve this related data in a single request.
GraphQL allows clients to request specific data fields, optimizing data transfer.
Core Operations in GraphQL
GraphQL defines three primary types of operations:
Queries: Fetching Data
Queries are used to read or fetch data, analogous to HTTP GET requests in REST. Clients specify the structure of the data they want, and the server returns a JSON object mirroring that structure.
Example Query:
query GetUserDetails {
user(id: "1") {
id
name
email
posts {
title
publishedDate
}
}
}
This query asks for the id, name, and email of the user with ID "1", along with the title and publishedDate of their posts.
Mutations: Modifying Data
Mutations are used to create, update, or delete data, similar to HTTP POST, PUT, PATCH, and DELETE requests in REST. Like queries, mutations can also specify which data to return after the modification.
Example Mutation:
mutation UpdateUserEmail {
updateUserEmail(userId: "1", newEmail: "new.email@example.com") {
id
email
updatedAt
}
}
This mutation updates a user's email and requests the user's id, new email, and updatedAt timestamp in response.
Subscriptions: Real-Time Updates
Subscriptions allow clients to listen for real-time data changes from the server. When a specific event occurs or data is updated on the server, it pushes the new information to subscribed clients, typically using WebSockets. This is a powerful feature for building interactive applications like live chats or dashboards.
Resolvers: The Data Fetching Logic
On the server-side, each field in the GraphQL schema is backed by a function called a resolver. When a query comes in, the GraphQL server traverses the query field by field, executing the resolver for each field. Resolvers are responsible for fetching the data for their specific field from any data source (e.g., database, REST API, microservice, static data).
Introspection and Schema Evolution
GraphQL allows clients to query the schema itself using introspection. This means clients can ask the API what queries, types, and fields it supports. This feature powers tools like GraphiQL (an in-browser IDE for exploring GraphQL APIs) and enables automatic documentation generation.
For API evolution, GraphQL encourages adding new fields and types rather than versioning the entire API (e.g., /v1, /v2). Old fields can be marked as deprecated but remain functional, giving clients time to migrate. This approach simplifies API maintenance and client adoption of new features.
GraphQL vs. REST: A Comparative Look
While both GraphQL and REST are used to build APIs over HTTP, they have fundamental differences in their approach. As an experienced REST developer, understanding these distinctions is key.
The radar chart above provides a visual comparison of GraphQL and REST across several dimensions. "Data Fetching Efficiency" highlights GraphQL's ability to get just the needed data. "Flexibility for Client" refers to the client's power to define data requirements. "Caching Complexity" acknowledges that REST's URL-based caching is simpler than GraphQL's more granular needs. "Learning Curve" can be steeper for GraphQL initially. "Tooling & Ecosystem" is strong for both, though GraphQL's introspection fosters powerful tools. "Endpoint Management" is simpler in GraphQL due to its single endpoint.
Feature Comparison Table
The following table provides a more detailed, side-by-side comparison of key features:
| Feature | GraphQL | REST |
|---|---|---|
| Endpoint Structure | Typically a single endpoint (e.g., /graphql) for all operations. | Multiple endpoints, resource-based (e.g., /users, /posts/{id}). |
| Data Fetching | Client specifies exactly what data is needed; prevents over/under-fetching. | Server defines fixed data structure per endpoint; can lead to over/under-fetching. |
| HTTP Methods | Primarily uses POST for queries and mutations. GET can be used for queries. | Uses various HTTP verbs (GET, POST, PUT, DELETE, PATCH) for different operations. |
| Schema & Typing | Strongly typed schema (SDL) is central; contract between client and server. | Schema (e.g., OpenAPI/Swagger) is optional but recommended; type enforcement varies. |
| Versioning | Schema evolution (add/deprecate fields) without API versioning. | Often requires versioned APIs (e.g., /v1/, /v2/) for breaking changes. |
| Real-time Updates | Native support for real-time data via Subscriptions. | Requires separate mechanisms like WebSockets or Server-Sent Events. |
| Caching | More complex; typically requires client-side libraries or specific server strategies (e.g., persisted queries, field-level caching). | Leverages standard HTTP caching mechanisms (ETags, Cache-Control headers) effectively. |
| Error Handling | Errors are typically part of the JSON response (often with a 200 OK status), within an errors array. |
Uses HTTP status codes (e.g., 404, 500, 400) to indicate errors. |
| Developer Tooling | Rich tooling (e.g., GraphiQL, Apollo Studio) enabled by schema introspection. | Good tooling (e.g., Postman, Swagger UI), often dependent on schema definition. |
Visualizing GraphQL Concepts
A mindmap can help illustrate the interconnectedness of GraphQL's core components:
This mindmap shows how the central Schema underpins operations like Queries, Mutations, and Subscriptions. Resolvers bridge these operations to your data sources. The benefits and considerations branch out, providing a holistic view of the GraphQL ecosystem.
Benefits and When to Choose GraphQL
GraphQL offers several compelling advantages, particularly for modern applications:
- Improved Performance: By fetching only necessary data, GraphQL reduces payload sizes and the number of network requests, leading to faster load times, especially on mobile or slow networks.
- Enhanced Developer Experience: The strongly typed schema, introspection, and tools like GraphiQL make APIs easier to explore, understand, and consume. Frontend developers can iterate faster without waiting for backend changes to expose new data.
- API Evolution without Versioning: Adding new fields or types to the schema doesn't break existing clients. Deprecated fields can be clearly marked, allowing for graceful transitions.
- Unified Data Access: GraphQL can act as an abstraction layer over multiple backend services (databases, microservices, legacy REST APIs), providing a single, consistent API for clients.
Ideal Use Cases:
- Applications with complex UIs that need to aggregate data from multiple sources.
- Mobile applications where minimizing data transfer and network requests is critical. * Microservice architectures where GraphQL can serve as an API gateway.
- Projects with rapidly evolving frontend requirements.
- Real-time applications requiring live updates (e.g., chat, notifications).
Watch: GraphQL vs REST Explained
For a dynamic overview and comparison, this video offers valuable insights into the practical differences and use cases for GraphQL and REST:
This video breaks down the differences between GraphQL and REST API styles and discusses how the choice can impact development workflows.
Challenges and Considerations with GraphQL
While powerful, GraphQL also introduces new challenges:
- Caching: HTTP caching is straightforward with REST due to distinct URLs. GraphQL's single endpoint and dynamic queries make caching more complex. Solutions involve client-side libraries (like Apollo Client) or server-side strategies like persisted queries.
- The N+1 Problem: Naively implemented resolvers can lead to inefficient data fetching, where fetching a list of items and then a related field for each item results in N+1 database queries. Data loading patterns (e.g., using DataLoader in JavaScript) are essential to mitigate this.
- Rate Limiting and Query Complexity: Malicious or poorly constructed queries can request deeply nested data, potentially overwhelming the server. Implementing query depth limiting, complexity analysis, and timeouts is crucial.
- File Uploads: GraphQL doesn't natively specify file uploads. While solutions like
graphql-uploadexist, it's not as standardized asmultipart/form-datain REST. - Initial Setup and Learning Curve: Setting up a GraphQL server and understanding its concepts can be more involved than a simple REST API, especially for teams new to the technology.
FAQ: Understanding GraphQL
errors array within the JSON response body, alongside any data that was successfully fetched. This allows for partial data returns even if some parts of a query fail.Conclusion
GraphQL represents a significant evolution in API design, offering a powerful and flexible alternative to traditional REST APIs. Its client-driven data fetching, strong typing via a schema, and single-endpoint architecture address many of the inefficiencies associated with REST, such as over-fetching and under-fetching. For experienced software engineers like yourself, understanding GraphQL opens up new possibilities for building more performant, scalable, and developer-friendly applications. While it comes with its own set of challenges, particularly around caching and query complexity, the robust ecosystem and growing adoption demonstrate its value in the modern web landscape. Evaluating its fit for your projects will depend on specific requirements, team familiarity, and the complexity of your data interactions.
Recommended Further Exploration
- How do I design an effective GraphQL schema for complex applications?
- What are the best practices for securing a GraphQL API against common vulnerabilities?
- Can you compare popular GraphQL client libraries like Apollo Client and Relay for frontend development?
- Could you explain GraphQL Federation and how it's used in microservice architectures?
