
Is Grok-3-Mini the New Champion? Analyzing the AI Model's Performance
A deep dive into Grok-3-Mini's benchmarks, capabilities, and comparisons to other leading LLMs.
Key Highlights of Grok-3-Mini
- Benchmark Performance: Grok-3-Mini demonstrates strong performance in math, science, and coding, outperforming models like GPT-4o and DeepSeek-V3 in some tests.
- Reasoning Capabilities: Enhanced reasoning allows Grok-3-Mini to solve complex problems, especially when given more "thinking time."
- Model Variants: Grok-3 comes in multiple versions, including Grok-3 Reasoning Beta (for advanced reasoning) and Grok-3 Mini (a faster, smaller model that sacrifices some accuracy for quicker responses).
Understanding Grok-3-Mini
Grok-3-Mini is the smaller variant of Grok-3, the latest large language model (LLM) developed by xAI. Trained on the Colossus supercomputer, Grok-3-Mini is designed to be a more efficient and faster alternative to its larger counterpart, while still maintaining competitive performance across a range of tasks. This model is part of a broader family of models that includes Grok-3 and specialized "Reasoning" versions designed for advanced problem-solving.
The Grok Family: A Quick Overview
Grok-3 isn’t just a single LLM; it's a family of several models, with the initial releases focusing on Grok-3 and Grok-3 Mini. xAI also introduced Grok-3 Reasoning and Grok-3 Mini Reasoning, which, similarly to OpenAI's o3-mini and DeepSeek R1 models, tackle problems using a step-by-step logical approach.
Key Features of Grok-3-Mini:
- Efficiency: Grok-3-Mini is designed to provide faster responses compared to larger models, making it suitable for applications where quick processing is essential.
- Reasoning capabilities: Grok-3-Mini has enhanced reasoning capabilities that allow it to solve complex problems in innovative ways. Moreover it has outperformed existing models in logical reasoning and problem-solving internal benchmarks.
- Multimodal Capabilities: Both the models can generate images, but Grok 3 is still learning.
Grok-3-Mini's Benchmark Performance
Grok-3-Mini has been evaluated across various benchmarks to assess its capabilities in different domains. These benchmarks provide a quantitative measure of its performance compared to other leading LLMs.
Performance Metrics
Benchmarks shown by the xAI team reveal Grok-3 mini model outperforming its competition, including Gemini-2 Pro, DeepSeek-V3, Claude 3.5 Sonnet, and GPT-4o, in several tests, including Math (AIME), Science (GPQA), and Coding (LCB). The reasoning models, which are accessible via the Grok app, also outperform the competition using the same benchmarks.
Key Benchmarks:
- AIME (Math): Measures mathematical reasoning capabilities. Grok 3 Mini Reasoning outperforms all the other models when given more thinking time.
- GPQA (Science): Assesses general knowledge and reasoning in scientific domains.
- LCB (Coding): Evaluates coding skills and problem-solving abilities.
Grok-3-Mini vs. Other Models: A Detailed Comparison
Here's a detailed look at how Grok-3-Mini stacks up against other prominent LLMs like o3-mini, GPT-4o, and DeepSeek-V3 across various benchmarks:
| Model | AIME (Math) | GPQA (Science) | LCB (Coding) |
|---|---|---|---|
| Grok-3-Mini | Higher than Gemini-2 Pro, DeepSeek-V3, Claude 3.5 Sonnet, and GPT-4o | Higher than Gemini-2 Pro, DeepSeek-V3, Claude 3.5 Sonnet, and GPT-4o | Higher than Gemini-2 Pro, DeepSeek-V3, Claude 3.5 Sonnet, and GPT-4o |
| GPT-4o | Lower than Grok-3-Mini | Lower than Grok-3-Mini | Lower than Grok-3-Mini |
| DeepSeek-V3 | Lower than Grok-3-Mini | Lower than Grok-3-Mini | Lower than Grok-3-Mini |
These results indicate that Grok-3-Mini is highly competitive, particularly in technical domains. It's worth noting that some experts have questioned the validity of AIME as an AI benchmark. Regardless, the AIME 2025 test and its older versions are frequently used to evaluate a model’s math proficiency.
Strengths and Weaknesses of Grok-3-Mini
Like any AI model, Grok-3-Mini has its strengths and weaknesses. Understanding these can help users leverage its capabilities more effectively.
Strengths:
- Technical Proficiency: Grok-3-Mini excels in technical domains, making it a strong choice for AI-driven research and programming tasks.
- Reasoning Capabilities: The model's refined reasoning allows it to think for extended periods, correct errors, and explore alternatives, leading to more accurate answers.
- Efficiency: Designed to be faster and more efficient than larger models while remaining competitive.
Weaknesses:
-
Potential Benchmark Issues: Some experts have raised concerns about the validity and transparency of the benchmarks used to evaluate Grok-3 models.
-
Inconsistencies: Grok 3 hallucinating citations and even inventing fake URLs, similar to problems seen in other LLMs.
Grok-3-Mini in Action: Use Cases and Applications
Grok-3-Mini's capabilities make it suitable for a wide range of applications, including:
Coding and Development
Grok-3-Mini's coding skills can be leveraged for code generation, debugging, and software development tasks. Its ability to perform well in coding benchmarks suggests it can be a valuable tool for developers.
Research and Analysis
With its proficiency in science and math, Grok-3-Mini can assist in research tasks, data analysis, and generating insights from complex datasets.
Education and Learning
Grok-3-Mini can be used as an educational tool to help students learn and understand complex concepts in math, science, and other technical fields.
Visual Insights: Grok-3-Mini's Performance
Visual aids can provide a clearer understanding of Grok-3-Mini's capabilities. Here's a glimpse into its performance against other models.
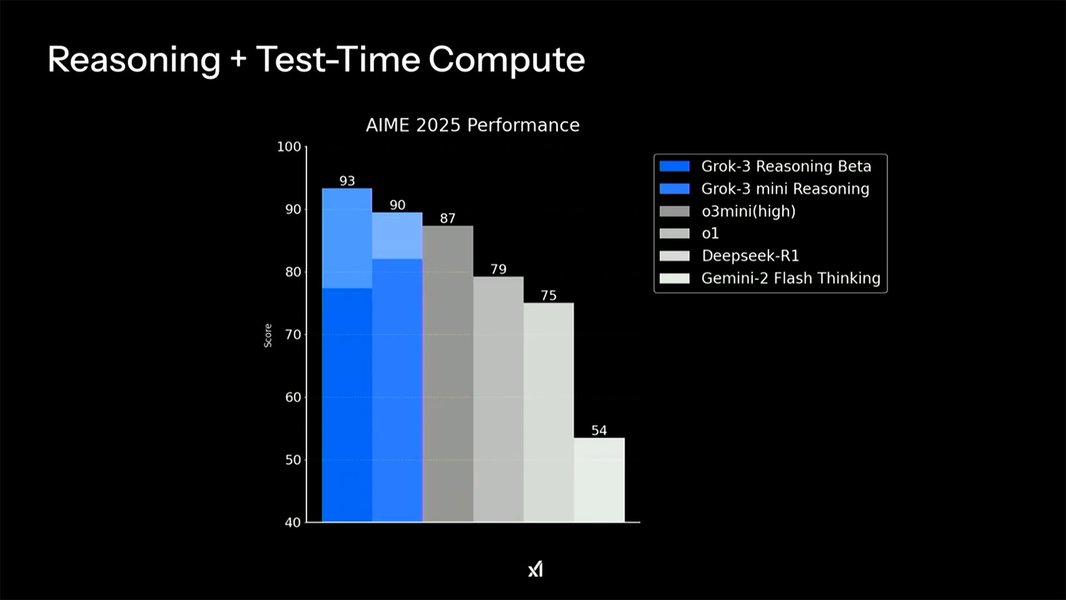
Grok 3 AIME 2025 Benchmark.
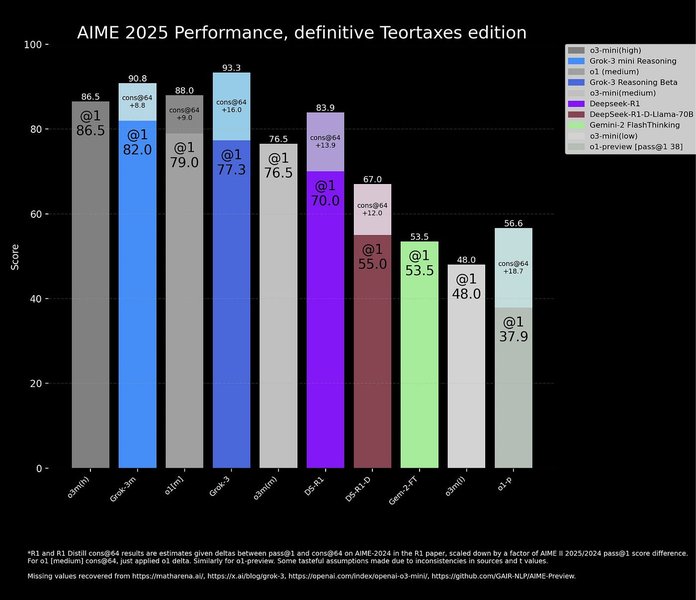
Grok-3 Hype, Benchmarks, and the Hard Truth About AI Claims.
These visualizations provide a comparative overview, highlighting Grok-3-Mini's competitive edge in specific evaluations.
Diving Deeper: Grok-3-Mini vs. o3-mini in Coding
Grok-3-Mini and o3-mini are two prominent language models that are often compared, especially in terms of their coding capabilities. Both models have their strengths and weaknesses, making them suitable for different types of coding tasks.
In a coding comparison between Claude 3.7 Sonnet, Grok 3, and o3-mini-high, Claude 3.7 Sonnet was found to be the superior model for building a simple Minecraft game using Pygame. The output by the o3-mini-high model was described as disappointing, with only a blank screen being produced. Grok 3 and o3-mini-high are somewhat similar, but if I had to compare them against each other, I would say Grok 3 generates slightly better code than the o3-mini-high model.
This video provides a detailed comparison, showcasing their coding abilities in action.
Frequently Asked Questions
References
Last updated April 10, 2025