
Fine-Tuning LLaMA Models: A Comprehensive Guide
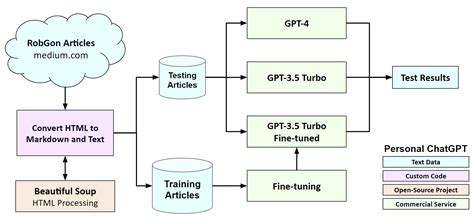
Fine-tuning LLaMA (Large Language Model Meta AI) models, such as LLaMA 2 and LLaMA 3, is the process of adapting a pre-trained model to perform specific tasks or understand particular domains more effectively. This customization allows the model to achieve better performance in specialized areas, such as sentiment analysis, question answering, or domain-specific natural language understanding. This guide provides a detailed, step-by-step approach to fine-tuning LLaMA models, covering essential techniques, methodologies, and tools.
Understanding Fine-Tuning
Fine-tuning involves taking a pre-trained language model and further training it on a new, often smaller, dataset specific to the desired task. The pre-trained model already possesses a broad understanding of language from its initial training on massive datasets. Fine-tuning refines this knowledge for a particular use case, improving the model's accuracy and relevance for that specific task. This process is crucial for tailoring the model to meet specific requirements, reducing the need for extensive prompt engineering, and enhancing usability by generating more contextually accurate responses.
Why Fine-Tune LLaMA Models?
Fine-tuning LLaMA models offers several key benefits:
- Improved Accuracy: Fine-tuning aligns the model's outputs with the specific requirements of your domain or task, leading to more accurate results.
- Cost Efficiency: By adapting the model to a specific task, you reduce the need for complex and lengthy prompts, saving computational resources and time.
- Enhanced Usability: Fine-tuned models generate more relevant and contextually accurate responses, making them more user-friendly.
- Customization: Fine-tuning allows you to tailor the model for specialized applications, such as customer service, medical diagnosis, or code generation.
Techniques for Fine-Tuning LLaMA Models
Several techniques can be used to fine-tune LLaMA models, each with its own advantages:
LoRA (Low-Rank Adaptation)
LoRA is a parameter-efficient fine-tuning technique that reduces the number of trainable parameters. Instead of updating the entire model, LoRA introduces low-rank matrices to approximate weight updates. This makes fine-tuning computationally efficient, allowing for training on less powerful hardware.
QLoRA (Quantized Low-Rank Adaptation)
QLoRA extends LoRA by quantizing the model's parameters to lower precision (e.g., 4-bit), further reducing memory and computational requirements. This technique is particularly useful for training large models like LLaMA 3 on consumer-grade hardware.
Supervised Fine-Tuning (SFT)
SFT involves training the model on labeled datasets to improve its performance on specific tasks. This is often the first step in reinforcement learning from human feedback (RLHF). The model learns to map inputs to desired outputs based on the provided examples.
Step-by-Step Guide to Fine-Tuning LLaMA
1. Choose the Right LLaMA Model
LLaMA models come in various sizes, such as 7B, 8B, 13B, and 70B parameters. The choice of model depends on your task and computational resources:
- LLaMA-2-7B/LLaMA-3-8B: Ideal for smaller tasks or when resources are limited. These models are often sufficient for tasks like classification or sentiment analysis.
- LLaMA-2-13B: A middle ground for tasks requiring more complexity, offering a balance between performance and resource usage.
- LLaMA-2-70B: Best for highly complex tasks but requires significant computational resources.
For conversational AI tasks, it's recommended to start with the chat-optimized variant (e.g., LLaMA-2-7B-Chat). Source
2. Prepare Your Dataset
The quality and diversity of your dataset are critical for successful fine-tuning. Follow these steps:
- Collect Data: Gather a dataset relevant to your task. For example, if you're building a sentiment analysis model, collect text labeled as positive, neutral, or negative.
- Format Data: Ensure your dataset is formatted correctly. For LLaMA models, data should be in a format compatible with the model's tokenizer. Hugging Face datasets often work well.
- Preprocess Data: Clean your dataset by removing noise, normalizing text, and ensuring consistency. If you're using a chat model, structure the data in a conversational format.
Your dataset should have columns like input and output, or question and answer. For example:
| Question | Answer |
| What is AI? | AI stands for Artificial Intelligence. |
| Define LoRA. | LoRA is a technique for parameter-efficient fine-tuning. |
You can use datasets from Hugging Face, such as mlabonne/guanaco-llama2-1k, which is a subset of the timdettmers/openassistant-guanaco dataset. Source
Split the dataset into training, validation, and test sets to properly evaluate the model's performance.
3. Install Required Libraries
To fine-tune LLaMA models, you'll need the following Python libraries:
transformers: For model loading and tokenization.datasets: For dataset handling.peft: For Parameter-Efficient Fine-Tuning (LoRA/QLoRA).bitsandbytes: For 4-bit quantization.accelerate: For distributed training.
Install these libraries using pip:
pip install transformers datasets peft bitsandbytes accelerate
You may also need to log in to Hugging Face to access pre-trained models:
huggingface-cli login
4. Load the Pre-Trained Model and Tokenizer
Use Hugging Face's transformers library to load the pre-trained LLaMA model and tokenizer. If you're using a quantized model, configure it for 4-bit precision.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# Model and tokenizer configuration
base_model = "meta-llama/Llama-2-7b-hf" # Replace with your desired model
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16"
)
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(base_model, quantization_config=quant_config, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(base_model)
For QLoRA, quantize the model to 4-bit precision using bitsandbytes:
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4")
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=bnb_config, device_map="auto")
5. Configure Fine-Tuning Parameters
For efficient fine-tuning, use LoRA or QLoRA. These methods add lightweight adapter layers to the model, reducing memory usage and computational requirements.
Example LoRA configuration:
from peft import LoraConfig
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM"
)
6. Prepare the Dataset for Training
Load and preprocess the dataset using the datasets library:
from datasets import load_dataset
# Load dataset
dataset_name = "mlabonne/guanaco-llama2-1k"
dataset = load_dataset(dataset_name, split="train")
# Tokenize dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
Convert your dataset into a format compatible with Hugging Face:
from datasets import Dataset
train_dataset = Dataset.from_pandas(train_data)
val_dataset = Dataset.from_pandas(val_data)
7. Train the Model
Use a fine-tuning framework like Hugging Face's Trainer or SFTTrainer from the trl library. Specify hyperparameters such as learning rate, batch size, and number of epochs.
Example:
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=8,
num_train_epochs=3,
learning_rate=5e-5,
save_steps=10000,
save_total_limit=2,
logging_dir="./logs"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset
)
trainer.train()
Set up LoRA using the PEFT library:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
Define the training configuration:
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./fine_tuned_llama",
evaluation_strategy="steps",
logging_steps=100,
save_steps=500,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=3,
learning_rate=2e-5,
weight_decay=0.01,
save_total_limit=2,
load_best_model_at_end=True,
fp16=True # Enable mixed precision
)
Use the Hugging Face Trainer for fine-tuning:
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer
)
trainer.train()
8. Evaluate the Fine-Tuned Model
After training, evaluate the model on a validation or test dataset to measure its performance. Use metrics like accuracy, F1 score, or BLEU, depending on your task.
Example:
from datasets import load_metric
metric = load_metric("accuracy")
results = trainer.evaluate()
print("Accuracy:", results["eval_accuracy"])
Evaluate the model's performance using metrics like accuracy, relevance, and perplexity:
from datasets import load_metric
metric = load_metric("accuracy")
predictions = trainer.predict(test_dataset)
metric.compute(predictions=predictions.predictions, references=predictions.label_ids)
9. Save and Deploy the Model
Save the fine-tuned model and tokenizer for future use:
model.save_pretrained("./fine_tuned_model")
tokenizer.save_pretrained("./fine_tuned_model")
You can deploy the model using libraries like transformers for inference or frameworks like llama.cpp for running the model locally on a CPU. Source
Load the fine-tuned model for inference:
from transformers import pipeline
pipe = pipeline("text-generation", model="./fine_tuned_llama", tokenizer="./fine_tuned_llama")
result = pipe("What is AI?")
print(result[0]["generated_text"])
10. Pushing the Model to Hugging Face Hub
To share your fine-tuned model, push it to the Hugging Face Hub:
huggingface-cli login
model.push_to_hub("your-username/fine-tuned-llama")
tokenizer.push_to_hub("your-username/fine-tuned-llama")
Best Practices for Fine-Tuning LLaMA
- Start with a Chat-Optimized Model: If your task involves conversational AI, use a chat-optimized variant like LLaMA-2-7B-Chat. Source
- Use Parameter-Efficient Techniques: Methods like LoRA and QLoRA reduce memory requirements and make fine-tuning feasible on consumer hardware. Source
- Focus on Data Quality: High-quality, diverse datasets yield better results than large but noisy datasets. Source
- Experiment with Hyperparameters: Adjust learning rate, batch size, and LoRA parameters (e.g., rank and alpha) to optimize performance. Source
- Leverage Quantization: Use 4-bit quantization to reduce memory usage without sacrificing much accuracy. Source
- Test on Validation Data: Regularly evaluate the model during training to avoid overfitting.
- Start Small: Begin with a smaller model (e.g., LLaMA 2–7B) to test your setup.
- Monitor Training: Use tools like Weights & Biases for real-time monitoring.
- Optimize Hyperparameters: Experiment with learning rates, batch sizes, and LoRA configurations.
- Regular Updates: Continuously update the model with new data to maintain performance.
Hardware and Software Requirements
Hardware Requirements
- GPU: A high-performance GPU is recommended. For smaller models like LLaMA 2–7B, a consumer GPU with 16 GB VRAM (e.g., NVIDIA T4) may suffice with techniques like LoRA or QLoRA. For larger models like LLaMA 3–70B, you may need multiple GPUs or cloud-based solutions.
- RAM: At least 16 GB of system RAM is recommended.
- Storage: Ensure sufficient storage for the model weights and datasets.
Software Requirements
-
Python: Version 3.8 or higher.
-
Libraries: Install the required libraries as mentioned above.
Conclusion
Fine-tuning LLaMA models like LLaMA 2 and LLaMA 3 allows you to adapt powerful pre-trained language models to specific tasks and domains. By following the steps outlined above—choosing the right model, preparing your dataset, using efficient fine-tuning techniques, and optimizing hyperparameters—you can achieve excellent results even with limited resources. Whether you're building a sentiment classifier, a chatbot, or a domain-specific NLP application, LLaMA models provide the flexibility and power to meet your needs.
Resources and References
Last updated January 6, 2025