
Декодирование кодов Хэмминга: Восстановление сообщений из зашумленных данных и оценка надежности
Подробное руководство по исправлению ошибок в полученных векторах 1001010 и 1101011 с использованием (7,4)-кода Хэмминга и анализ вероятности успеха.
Коды Хэмминга являются фундаментальным инструментом в теории кодирования, предназначенным для обнаружения и исправления ошибок, возникающих при передаче цифровой информации по каналам связи, подверженным помехам. В этом разборе мы детально рассмотрим процесс декодирования двух конкретных векторов, полученных после передачи по зашумленному каналу, используя предоставленную матрицу для (7,4)-кода Хэмминга. Также мы оценим вероятность того, что восстановленные нами сообщения действительно соответствуют исходно отправленным.
Ключевые моменты декодирования
- Идентификация матрицы: Предоставленная матрица H является проверочной матрицей, а не порождающей, что типично для процесса декодирования и вычисления синдрома.
- Процесс декодирования: Оба полученных вектора (1001010 и 1101011) содержали по одной ошибке, которые были успешно идентифицированы и исправлены с помощью синдромного декодирования.
- Вероятность успеха: Вероятность правильного декодирования напрямую зависит от вероятности битовой ошибки (p) в канале и для (7,4)-кода Хэмминга рассчитывается по формуле \( P_{\text{correct}} = (1-p)^7 + 7p(1-p)^6 \).
Понимание (7,4)-кода Хэмминга и предоставленной матрицы
(7,4)-код Хэмминга — это линейный блочный код, который кодирует 4 информационных бита в 7-битное кодовое слово путем добавления 3 проверочных (контрольных) бит. Этот код способен гарантированно исправлять одну битовую ошибку в кодовом слове и обнаруживать до двух битовых ошибок.
Проверочная матрица H
Предоставленная матрица H:
\[ H = \begin{pmatrix} 0 & 0 & 0 & 1 & 1 & 1 & 1 \ 0 & 1 & 1 & 0 & 0 & 1 & 1 \ 1 & 0 & 1 & 0 & 1 & 0 & 1 \end{pmatrix} \]Эта матрица размером 3x7 является проверочной матрицей (parity-check matrix) для (7,4)-кода Хэмминга, а не порождающей матрицей (generator matrix), которая имела бы размерность 4x7. Проверочная матрица используется для декодирования путем вычисления синдрома.
Столбцы матрицы H (обозначим их \(h_1, h_2, \dots, h_7\)) соответствуют позициям битов в кодовом слове. В данном случае:
- \(h_1 = [0,0,1]^T\)
- \(h_2 = [0,1,0]^T\)
- \(h_3 = [0,1,1]^T\)
- \(h_4 = [1,0,0]^T\)
- \(h_5 = [1,0,1]^T\)
- \(h_6 = [1,1,0]^T\)
- \(h_7 = [1,1,1]^T\)
Вычисление синдрома
Для декодирования полученного вектора \(r\) (представленного как вектор-столбец \(r^T\)) вычисляется синдром \(s\) по формуле (все операции выполняются по модулю 2):
\[ s = H \cdot r^T \]Если синдром \(s\) является нулевым вектором (\([0,0,0]^T\)), это означает, что полученный вектор \(r\) является корректным кодовым словом (ошибок нет, или произошла ошибка, которую код не может обнаружить/исправить, что маловероятно для одной ошибки). Если синдром \(s\) ненулевой, он совпадает с одним из столбцов матрицы \(H\), указывая на позицию ошибочного бита в векторе \(r\). Для исправления ошибки бит в этой позиции инвертируется (0 меняется на 1, а 1 на 0).
Декодирование полученного вектора 1: 1001010
Пусть \(r_1 = 1001010\). Представим его в виде вектора-столбца \(r_1^T = [1,0,0,1,0,1,0]^T\).
Вычисление синдрома s1
\[ s_1 = H \cdot r_1^T = \begin{pmatrix} 0 & 0 & 0 & 1 & 1 & 1 & 1 \ 0 & 1 & 1 & 0 & 0 & 1 & 1 \ 1 & 0 & 1 & 0 & 1 & 0 & 1 \end{pmatrix} \cdot \begin{pmatrix} 1 \ 0 \ 0 \ 1 \ 0 \ 1 \ 0 \end{pmatrix} = \begin{pmatrix} (0 \cdot 1) + (0 \cdot 0) + (0 \cdot 0) + (1 \cdot 1) + (1 \cdot 0) + (1 \cdot 1) + (1 \cdot 0) \ (0 \cdot 1) + (1 \cdot 0) + (1 \cdot 0) + (0 \cdot 1) + (0 \cdot 0) + (1 \cdot 1) + (1 \cdot 0) \ (1 \cdot 1) + (0 \cdot 0) + (1 \cdot 0) + (0 \cdot 1) + (1 \cdot 0) + (0 \cdot 1) + (1 \cdot 0) \end{pmatrix} \pmod 2 \] \[ s_1 = \begin{pmatrix} 0+0+0+1+0+1+0 \ 0+0+0+0+0+1+0 \ 1+0+0+0+0+0+0 \end{pmatrix} \pmod 2 = \begin{pmatrix} 2 \ 1 \ 1 \end{pmatrix} \pmod 2 = \begin{pmatrix} 0 \ 1 \ 1 \end{pmatrix} \]Идентификация и исправление ошибки
Синдром \(s_1 = [0,1,1]^T\). Этот вектор совпадает с третьим столбцом \(h_3\) матрицы \(H\). Следовательно, ошибка произошла в 3-м бите вектора \(r_1\).
Исходный вектор \(r_1 = 1001010\). Инвертируем 3-й бит (0 на 1):
Исправленное кодовое слово \(c_1 = 1011010\).
Извлечение исходного сообщения
В стандартном (7,4)-коде Хэмминга информационные биты обычно располагаются на позициях 3, 5, 6 и 7, а проверочные — на позициях 1, 2 и 4. Используя эту конвенцию для \(c_1 = 1011010\):
- Бит 3: 1
- Бит 5: 0
- Бит 6: 1
- Бит 7: 0
Таким образом, декодированное информационное сообщение для первого вектора: 1010.
Декодирование полученного вектора 2: 1101011
Пусть \(r_2 = 1101011\). Представим его в виде вектора-столбца \(r_2^T = [1,1,0,1,0,1,1]^T\).
Вычисление синдрома s2
\[ s_2 = H \cdot r_2^T = \begin{pmatrix} 0 & 0 & 0 & 1 & 1 & 1 & 1 \ 0 & 1 & 1 & 0 & 0 & 1 & 1 \ 1 & 0 & 1 & 0 & 1 & 0 & 1 \end{pmatrix} \cdot \begin{pmatrix} 1 \ 1 \ 0 \ 1 \ 0 \ 1 \ 1 \end{pmatrix} = \begin{pmatrix} (0 \cdot 1) + (0 \cdot 1) + (0 \cdot 0) + (1 \cdot 1) + (1 \cdot 0) + (1 \cdot 1) + (1 \cdot 1) \ (0 \cdot 1) + (1 \cdot 1) + (1 \cdot 0) + (0 \cdot 1) + (0 \cdot 0) + (1 \cdot 1) + (1 \cdot 1) \ (1 \cdot 1) + (0 \cdot 1) + (1 \cdot 0) + (0 \cdot 1) + (1 \cdot 0) + (0 \cdot 1) + (1 \cdot 1) \end{pmatrix} \pmod 2 \] \[ s_2 = \begin{pmatrix} 0+0+0+1+0+1+1 \ 0+1+0+0+0+1+1 \ 1+0+0+0+0+0+1 \end{pmatrix} \pmod 2 = \begin{pmatrix} 3 \ 3 \ 2 \end{pmatrix} \pmod 2 = \begin{pmatrix} 1 \ 1 \ 0 \end{pmatrix} \]Идентификация и исправление ошибки
Синдром \(s_2 = [1,1,0]^T\). Этот вектор совпадает с шестым столбцом \(h_6\) матрицы \(H\). Следовательно, ошибка произошла в 6-м бите вектора \(r_2\).
Исходный вектор \(r_2 = 1101011\). Инвертируем 6-й бит (1 на 0):
Исправленное кодовое слово \(c_2 = 1101001\).
Извлечение исходного сообщения
Используя ту же конвенцию для позиций информационных битов (3, 5, 6, 7) для \(c_2 = 1101001\):
- Бит 3: 0
- Бит 5: 0
- Бит 6: 0
- Бит 7: 1
Таким образом, декодированное информационное сообщение для второго вектора: 0001.
Сводка результатов декодирования
Ниже представлена таблица, суммирующая процесс декодирования для обоих векторов:
| Параметр | Полученный вектор 1 | Полученный вектор 2 |
|---|---|---|
| Исходный полученный вектор (r) | 1001010 | 1101011 |
| Вычисленный синдром (s) | [0,1,1]T | [1,1,0]T |
| Позиция ошибки | 3 | 6 |
| Исправленное кодовое слово (c) | 1011010 | 1101001 |
| Декодированное информационное сообщение (4 бита) | 1010 | 0001 |
Визуализация логики декодирования
Процесс декодирования кода Хэмминга можно представить в виде последовательности шагов. Приведенная ниже ментальная карта иллюстрирует этот процесс, начиная от получения зашумленного вектора и заканчивая извлечением исходного сообщения.
Эта карта показывает, как синдром играет ключевую роль в локализации и последующем исправлении ошибки, позволяя восстановить исходное кодовое слово и, следовательно, первоначальное сообщение.
Оценка вероятности правильного декодирования
Вероятность того, что декодированные слова совпадают с посланными, зависит от характеристик канала передачи, в частности, от вероятности битовой ошибки \(p\). Предполагается, что ошибки для каждого бита независимы и одинаковы (модель бинарного симметричного канала - BSC).
Факторы, влияющие на вероятность
Код Хэмминга (7,4) способен исправлять любую одиночную ошибку в 7-битном кодовом слове. Декодирование будет успешным (т.е. декодированное слово совпадет с посланным), если во время передачи произошло не более одной ошибки. Если ошибок две или более, стандартный декодер Хэмминга либо не сможет их исправить, либо исправит неверно (т.е. преобразует полученный вектор в кодовое слово, отличное от изначально посланного).
Расчет вероятности для одного кодового слова
Вероятность \(P_{\text{correct}}\) того, что одно 7-битное кодовое слово будет декодировано правильно, равна сумме вероятностей двух событий:
- Ни одной ошибки не произошло (все 7 бит переданы верно): \( P(\text{0 ошибок}) = (1-p)^7 \)
- Произошла ровно одна ошибка (которую код Хэмминга исправит): \( P(\text{1 ошибка}) = \binom{7}{1} p^1 (1-p)^{7-1} = 7p(1-p)^6 \)
Таким образом, общая вероятность правильного декодирования одного кодового слова:
\[ P_{\text{correct}} = (1-p)^7 + 7p(1-p)^6 \]Эту формулу можно упростить: \( P_{\text{correct}} = (1-p)^6 ((1-p) + 7p) = (1-p)^6 (1+6p) \).
Расчет вероятности для обоих кодовых слов
Если предположить, что передача двух кодовых слов была независимой, то вероятность того, что оба слова будут декодированы правильно, равна произведению их индивидуальных вероятностей правильного декодирования:
\[ P_{\text{both correct}} = P_{\text{correct}} \times P_{\text{correct}} = \left( (1-p)^6 (1+6p) \right)^2 = (1-p)^{12} (1+6p)^2 \]Влияние вероятности битовой ошибки \(p\)
Значение \(p\) существенно влияет на \(P_{\text{correct}}\). Чем меньше \(p\), тем выше вероятность успешного декодирования. На диаграмме ниже показано, как изменяется вероятность правильного декодирования одного слова (\(P_{\text{correct}}\)) и обоих слов (\(P_{\text{both correct}}\)) в зависимости от \(p\).
Как видно из диаграммы, даже небольшое увеличение вероятности битовой ошибки \(p\) приводит к заметному снижению вероятности правильного декодирования, особенно когда речь идет о корректном восстановлении обоих кодовых слов. Например, при \(p=0.01\):
- \(P_{\text{correct}} = (1-0.01)^6 (1+6 \cdot 0.01) \approx (0.99)^6 \cdot (1.06) \approx 0.94147 \cdot 1.06 \approx 0.99796\) (или 99.80%)
- \(P_{\text{both correct}} \approx (0.99796)^2 \approx 0.99592\) (или 99.59%)
При \(p=0.1\):
- \(P_{\text{correct}} = (1-0.1)^6 (1+6 \cdot 0.1) = (0.9)^6 \cdot (1.6) \approx 0.531441 \cdot 1.6 \approx 0.8503\) (или 85.03%)
- \(P_{\text{both correct}} \approx (0.8503)^2 \approx 0.7230\) (или 72.30%)
Эти расчеты подчеркивают эффективность кода Хэмминга при относительно низких уровнях шума в канале, но также показывают его ограничения при увеличении интенсивности помех.
Визуальное объяснение концепций исправления ошибок
Коды Хэмминга являются одним из первых и наиболее известных примеров кодов, исправляющих ошибки. Понимание их работы открывает дверь в увлекательный мир теории информации и кодирования. Следующее видео от 3Blue1Brown прекрасно иллюстрирует основные идеи, лежащие в основе кодов Хэмминга, и объясняет, как они достигают возможности исправления ошибок.
В видео наглядно демонстрируется, как избыточность, вносимая проверочными битами, позволяет не только обнаруживать, но и точно определять местоположение одиночной ошибки, что является ключевым свойством кодов Хэмминга.
Иллюстрация компонентов цифрового декодирования
Процессы кодирования и декодирования, подобные тем, что используются в кодах Хэмминга, реализуются с помощью цифровых логических схем. Декодеры являются фундаментальными компонентами таких систем. На изображении ниже показан пример бинарного декодера 2-в-4, который преобразует 2-битный входной код в один из четырех уникальных выходов. Хотя это упрощенный пример, он иллюстрирует базовый принцип работы схем, которые могут быть частью более сложных систем декодирования ошибок.
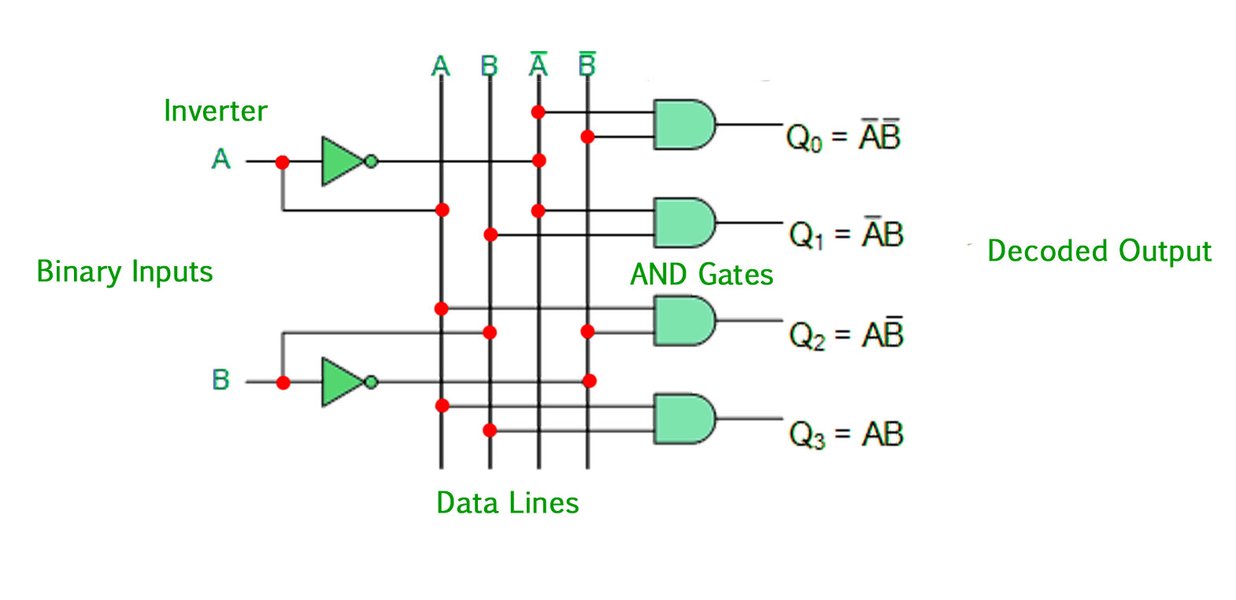
Принципиальная схема бинарного декодера 2-в-4.
В контексте кодов Хэмминга, схемы декодирования анализируют синдром для активации логики, исправляющей ошибочный бит.
Часто Задаваемые Вопросы (FAQ)
Рекомендуемые запросы
- Как построить порождающую и проверочную матрицы для кода Хэмминга (n,k)?
- Примеры применения кодов Хэмминга в реальных системах связи и хранения данных.
- Сравнение эффективности различных кодов коррекции ошибок: код Хэмминга, код Рида-Соломона, LDPC коды.
- Что такое минимальное расстояние Хэмминга и как оно связано со способностью кода исправлять ошибки?
Источники
Last updated May 20, 2025