
Unveiling the Inner Workings of Large Language Models (LLMs)
Demystifying the AI Revolution Behind Human-like Text Generation and Comprehension
Large Language Models (LLMs) have captivated the world with their remarkable ability to understand, generate, and interact with human language in astonishingly human-like ways. From powering conversational AI chatbots like ChatGPT to assisting with complex tasks such as content creation and code generation, LLMs are at the forefront of the artificial intelligence revolution. But how do these sophisticated systems truly work beneath the surface? This comprehensive guide will explore the intricate architecture, training methodologies, and diverse applications that enable LLMs to perform their impressive feats.
Key Insights into LLM Functionality
- Transformer Architecture: The foundational innovation enabling LLMs is the Transformer architecture, which uses self-attention mechanisms to process vast amounts of data and understand complex relationships between words, regardless of their position in a sequence.
- Phased Training Process: LLMs undergo a multi-phase training process, typically involving extensive pre-training on massive datasets for general language understanding, followed by fine-tuning with specific instructions and reinforcement learning from human feedback (RLHF) to align with desired behaviors.
- Diverse Applications: Beyond generating human-like text for conversations, LLMs are transforming various industries through applications in content creation, language translation, code generation, customer support, data summarization, and enhancing search capabilities.
The Core Mechanics of LLMs: A Deep Dive
At their essence, Large Language Models are advanced machine learning models that leverage deep learning techniques to process and understand human language. They are fundamentally neural networks, computing systems inspired by the human brain, composed of interconnected "neurons" or nodes arranged in layers.
The Indispensable Transformer Architecture
The breakthrough that propelled LLMs into their current capabilities is the Transformer architecture, introduced by Google in 2017. Unlike earlier recurrent neural networks (RNNs) and long short-term memory (LSTM) models, Transformers can process entire sequences of text simultaneously, rather than word by word. This parallel processing ability, facilitated by a mechanism known as "self-attention," allows LLMs to efficiently learn long-range dependencies and complex contextual relationships within massive datasets.
A typical Transformer model consists of an encoder and a decoder, though many modern LLMs, especially those focused on generation (like GPT models), primarily use a decoder-only architecture. Key components within the Transformer include:
- Self-Attention Layers: These layers allow the model to weigh the importance of different words in a sequence when processing a specific word. For example, in the sentence "The bank decided to open a new branch," the self-attention mechanism helps the model understand that "bank" refers to a financial institution, not a river bank, by attending to the surrounding words. This mechanism is crucial for capturing contextual nuances and semantic relationships.
- Feed-Forward Layers: These are standard neural network layers applied to each position independently, further processing the information learned by the attention layers.
- Embedding Layers: Before processing, words or sub-word units (tokens) are converted into numerical representations called embeddings. These embeddings capture semantic meaning, allowing words with similar meanings to have similar numerical representations.
- Positional Encodings: Since Transformers process words in parallel, they need a way to account for the order of words in a sentence. Positional encodings are added to the embeddings to provide information about the relative or absolute position of tokens in the sequence.
The ability of Transformer models to handle vast amounts of data and discover intricate patterns is why LLMs are so powerful in language understanding and generation.
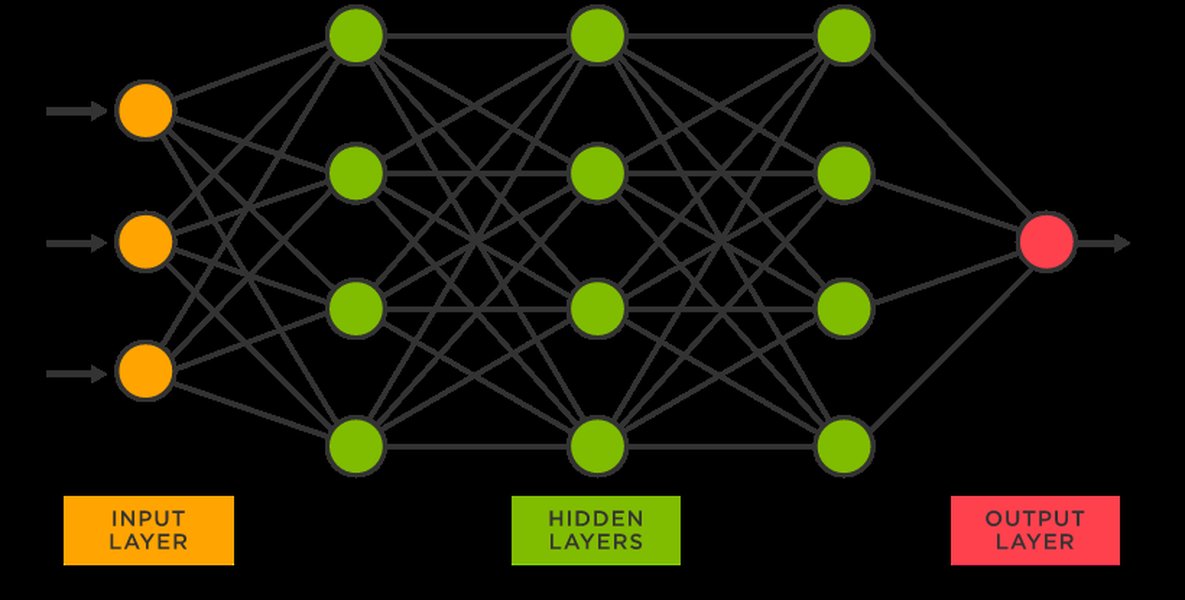
A simplified illustration of a neural network, highlighting the interconnected layers that enable LLMs to process information.
The Training Regimen: From Pre-training to Fine-tuning
The "large" in LLM refers to two main aspects: the massive amount of data they are trained on and the enormous number of parameters they possess (often billions or even trillions). The training of an LLM is a computationally intensive, multi-phase process:
Phase 1: Pre-training
This initial phase involves training the model on colossal datasets of text and code gathered from the internet, including books, articles, websites, and more. The primary objective during pre-training is to enable the LLM to learn the statistical relationships, grammar, syntax, and semantics of language. The model is typically trained on tasks like predicting the next word in a sentence (autoregressive models, like GPT) or filling in masked words within a sentence (autoencoder models, like BERT). This self-supervised learning allows the model to absorb a vast general understanding of language without explicit human labeling of data.
An evolutionary timeline of LLMs, depicting their increasing scale and sophistication.
Phase 2: Fine-tuning and Instruction Tuning
After pre-training, the general-purpose LLM is further refined for specific applications. This involves training the model on smaller, more curated datasets that are tailored to particular tasks or desired behaviors. Instruction tuning, a crucial part of this phase, involves training the model on datasets of instructions and desired responses. This helps the LLM understand how to follow directions, answer questions, and generate text in a helpful and coherent manner.
Phase 3: Reinforcement Learning from Human Feedback (RLHF)
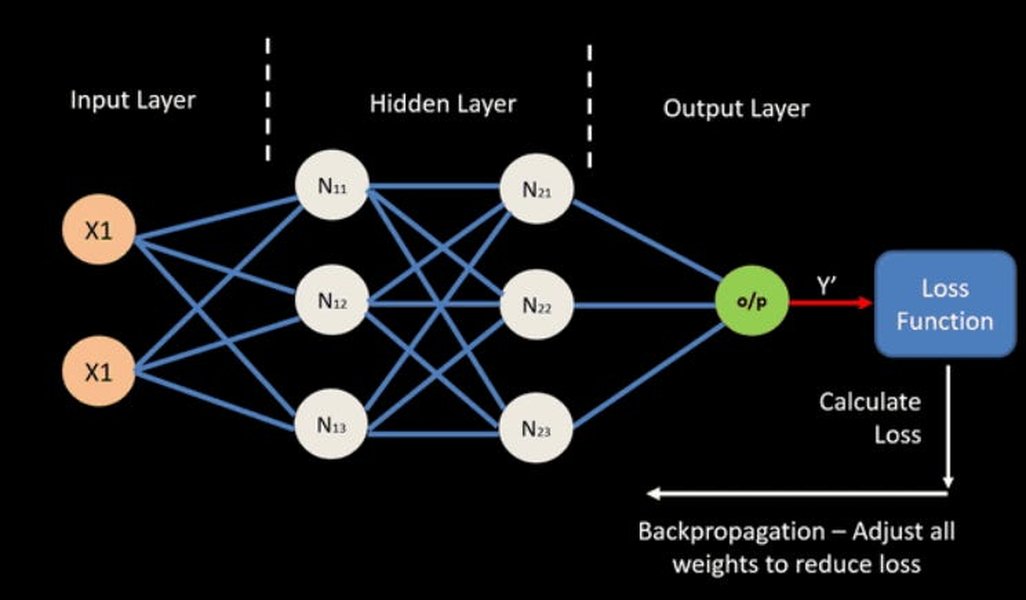
RLHF is a sophisticated technique that aligns the LLM's outputs more closely with human preferences and values. In this phase, human reviewers rate the quality of different responses generated by the LLM. These ratings are then used to train a reward model, which in turn provides feedback to the LLM. The LLM learns to generate responses that are preferred by humans, leading to more natural, helpful, and less biased outputs. This iterative process of human feedback and model adjustment is vital for creating models that are not only capable but also safe and user-friendly.
Probabilistic Prediction and Token Generation
Fundamentally, LLMs work by predicting the most probable next "token" in a sequence. A token can be a word, part of a word, or even a punctuation mark. When you give an LLM a prompt, it processes the input by converting it into numerical embeddings and passes it through its many layers of the Transformer architecture. Based on the patterns it learned during training, the model calculates the probability distribution of possible next tokens. It then selects the most probable token (or samples from the distribution to introduce creativity) and adds it to the sequence. This process repeats, generating one token at a time, until a complete and coherent response is formed.
Here's a simplified conceptual view of how tokens are processed:
def generate_text(prompt, llm_model, max_length):
tokens = tokenize(prompt)
for _ in range(max_length):
# Model predicts probabilities for the next token
next_token_probabilities = llm_model.predict_next_token(tokens)
# Select the most probable token (or sample based on temperature)
next_token = select_token(next_token_probabilities)
# Add the selected token to the sequence
tokens.append(next_token)
if next_token == <END_OF_SEQUENCE_TOKEN>:
break
return detokenize(tokens)
Diving Deeper into LLM Architectures
While the Transformer is the dominant architecture, there are variations that suit different purposes:
- Encoder-Decoder Models: These models, like the original Transformer, have distinct encoder and decoder components. The encoder processes the input sequence to create a rich representation, and the decoder then uses this representation to generate the output sequence. They are well-suited for tasks like machine translation or summarization where both understanding input and generating output are critical. BERT is an example of an encoder-only model, proficient in understanding context.
- Decoder-Only Models (Autoregressive): Models like OpenAI's GPT series (Generative Pre-trained Transformer) primarily use a decoder-only architecture. These models are highly effective at generating text sequentially, predicting the next token based on all previous tokens. They are excellent for tasks like content generation, conversational AI, and creative writing.
- Mixture-of-Experts (MoE) Architectures: This emerging architecture breaks down large language models into smaller "expert" models, each specializing in different aspects of the data. When an input is given, a "router" mechanism determines which experts are most relevant to process that specific input. This approach allows for scaling the number of parameters without a proportional increase in computational expense, leading to more efficient computation and diverse capabilities.
Applications of Large Language Models: A Transformative Impact
The capabilities of LLMs extend far beyond simple text generation, impacting various industries and creating new possibilities:
The radar chart above illustrates the current impact and future potential of LLMs across various application domains. It highlights their significant role in transforming how we interact with technology and process information, with areas like content creation and data summarization already showing high impact and continued growth potential.
Key Application Areas
| Application Area | Description and Examples |
|---|---|
| Content Generation | LLMs excel at producing human-like text for a variety of purposes, including articles, blog posts, social media captions, marketing copy, and even creative writing like poetry and scripts. They can adapt to specific styles and tones, significantly streamlining content workflows. |
| Conversational AI & Chatbots | Powering intelligent chatbots and virtual assistants (e.g., ChatGPT, customer support bots) that can engage in natural, dynamic conversations, answer questions, provide information, and assist users with various tasks. |
| Language Translation & Localization | Facilitating accurate and contextually relevant translation between multiple languages, as well as adapting content for specific cultural nuances. Models like BLOOM can generate text in 46 natural languages and 13 programming languages. |
| Code Generation & Development Assistance | Assisting software developers by generating code snippets, completing code, debugging, and explaining complex programming concepts. GitHub's Copilot is a prime example. |
| Search and Recommendation Systems | Enhancing search engine capabilities by understanding natural language queries more deeply, providing more relevant results, and generating concise answers. They also improve recommendation engines by understanding user preferences and content characteristics. |
| Data Summarization & Analysis | Condensing lengthy documents, articles, or reports into concise summaries, extracting key information, and performing sentiment analysis on large volumes of text data. |
| Customer Support & Service Automation | Automating responses to common customer inquiries, routing complex issues to human agents, and providing personalized support experiences, leading to faster response times and reduced operational costs. |
Challenges and Considerations
Despite their impressive capabilities, LLMs are not without challenges and considerations:
- Computational Resources: Training and deploying LLMs require significant computational power, large datasets, and technical expertise, making them expensive and energy-intensive.
- "Hallucinations": LLMs can sometimes generate information that sounds plausible but is factually incorrect or nonsensical. This is a common challenge, and techniques like Retrieval-Augmented Generation (RAG) are being developed to mitigate it by integrating external, real-time knowledge sources.
- Bias and Fairness: Since LLMs learn from the data they are trained on, they can inadvertently perpetuate biases present in that data, leading to unfair or discriminatory outputs. Mitigating bias is a continuous area of research and development.
- Security Vulnerabilities: As highlighted by the OWASP Top 10 for LLM Applications, LLMs are susceptible to security risks like prompt injections, data leakage, and unauthorized code execution. Secure development practices are crucial for LLM applications.
- Interpretability: The complex nature of deep learning models means that understanding exactly "why" an LLM produces a particular output can be challenging. This "black box" problem is an ongoing area of research in Explainable AI (XAI).
The Future of LLMs
The field of LLMs is rapidly evolving. We can anticipate further advancements in:
- Multimodality: Models that can process and generate information across various modalities—text, images, audio, and video—will become more sophisticated, enabling richer interactions and applications (e.g., Google's Gemini models).
- Efficiency and Accessibility: Efforts to make LLMs more computationally efficient will lead to more accessible models that can run on a wider range of devices, potentially reducing costs and environmental impact.
- Hybrid Systems: The integration of LLMs with symbolic AI or reasoning modules could lead to hybrid systems that combine the strengths of large-scale pattern recognition with logical inference, enabling more robust and reliable AI.
- Enhanced Control and Safety: Continued research into fine-tuning techniques, safety mechanisms, and explainability will improve the trustworthiness and alignment of LLMs with human intentions.
Explaining the Power of LLMs: A Visual Deep Dive
This video, "Transformers (how LLMs work) explained visually | DL5," provides an excellent visual explanation of the Transformer architecture, which is the backbone of most modern Large Language Models. It breaks down complex concepts like self-attention and positional encodings into easily digestible visual components, demonstrating how LLMs process information and learn contextual relationships within language. Understanding the Transformer is key to grasping the impressive capabilities of LLMs in natural language processing.
Frequently Asked Questions (FAQ)
Conclusion
Large Language Models represent a monumental leap in artificial intelligence, transforming how we interact with information and automate complex tasks. Their foundational Transformer architecture, combined with meticulous multi-phase training processes, enables them to grasp the nuances of human language and generate coherent, contextually relevant responses. While challenges like computational demands and the potential for bias exist, ongoing research and development are continually refining their capabilities and addressing limitations. As LLMs continue to evolve, they promise to unlock even greater innovation across industries, making AI more accessible and impactful than ever before.
Recommended Further Exploration
- Explore how deep learning techniques power advancements in natural language processing.
- Understand the intricate details of the Transformer neural network architecture.
- Learn about the crucial role of human feedback in refining LLM behavior.
- Discover the emerging trends and potential future directions of LLM technology.
Referenced Search Results
 aws.amazon.com
aws.amazon.com