
Industrial Practices for Building RAG Applications
Comprehensive Strategies and Architectures for Retrieval-Augmented Generation
Key Takeaways
- Modular Architecture Enhances Flexibility: Separating retrieval and generation components allows for easier updates and scalability.
- Advanced Retrieval Techniques Improve Accuracy: Utilizing vector search and multi-hop retrieval enhances the relevance of generated responses.
- Continuous Evaluation and Feedback Loops are Crucial: Regular monitoring and user feedback ensure the system remains accurate and efficient.
1. Overview of Industrial Practices in Building RAG Applications
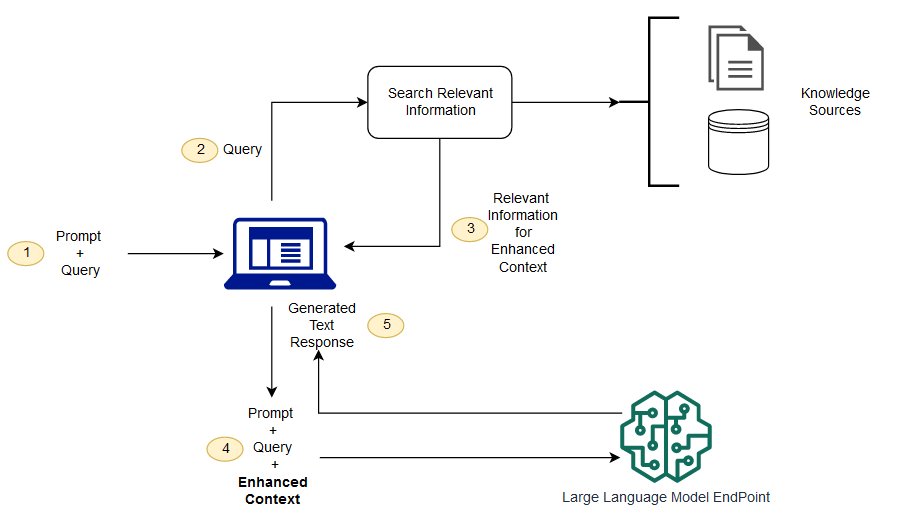
Retrieval-Augmented Generation (RAG) has emerged as a pivotal technique in enhancing the capabilities of Large Language Models (LLMs) by integrating external data sources. In industrial settings, the adoption of RAG frameworks has surged, with approximately 36.2% of enterprise use cases leveraging this approach. Key industries benefiting from RAG include finance, healthcare, and customer service, where accurate and contextual responses are paramount.
2. Architectural Patterns for RAG Applications
2.1 Pipelines with Explicit Retriever and Generator
This architecture distinctly separates the retrieval component from the generation module. The retriever typically employs vector search mechanisms, such as FAISS or Pinecone, to fetch relevant context from large corpora. The retrieved information is then fed into the generative model to produce the final output.
2.2 Integrated Architectures
Integrated architectures embed retrieval capabilities directly within the LLM’s prompting mechanism. This can involve using in-context examples or iterative querying, allowing for a more seamless flow of information. While this integration can enhance context handling, it poses challenges in debugging and updating the retrieval component independently.
2.3 Chained or Multi-Hop Designs
Chained architectures involve multiple rounds of retrieval, enabling the system to handle complex queries that require synthesizing information from various sources. This multi-hop approach improves the robustness of responses but increases the system’s complexity and potential latency.
2.4 End-to-End Differentiable Architectures
End-to-end architectures aim to train the entire RAG pipeline jointly, optimizing both retrieval and generation components simultaneously. While this can lead to performance gains, such architectures are often experimental and face scalability challenges.
3. Constraints and Challenges
Building industrial RAG systems entails navigating several constraints:
-
Latency: Retrieval processes can introduce delays, making it essential to optimize for low-latency responses.
-
Scalability: Efficient indexing and management of massive data corpora require advanced optimization techniques.
-
Accuracy & Robustness: Ensuring the precision of retrieved information is critical to prevent the generation of misleading or incorrect responses.
-
Context Length: LLMs have limited context windows, necessitating strategies to effectively manage and rank retrieved content.
-
Cost Management: Both retrieval and generation processes incur computational costs, necessitating efficient resource utilization.
-
Maintainability: Balancing modularity with integration affects the ease of system updates and scalability.
4. Solutions and Best Practices by Jerry Liu from LlamaIndex
4.1 Modular Pipeline Design
Jerry Liu emphasizes the importance of a modular pipeline where retrieval and generation components are decoupled. Utilizing frameworks like LlamaIndex allows developers to experiment with different retrieval strategies without altering the generative model. This separation enhances flexibility and scalability, enabling the system to adapt to varying data sources and retrieval methods.
4.2 Advanced Retrieval Techniques
LlamaIndex supports sophisticated retrieval mechanisms, including vector-based searches and multi-hop retrieval. By leveraging vector databases such as FAISS, Pinecone, or Weaviate, the system can efficiently handle large-scale data and improve the relevance of retrieved information. Additionally, implementing multi-hop retrieval allows the system to deconstruct complex queries into simpler sub-queries, enhancing the depth and accuracy of responses.
4.3 Agentic RAG
Agentic RAG represents an advanced architectural approach where the system acts as a stateful agent capable of using tools, maintaining conversation history, and reasoning over multiple steps. This architecture enables the agent to navigate, summarize, and compare information across multiple documents, making it particularly effective for research tasks and complex query handling.
4.4 Query Decomposition and Context Reconstruction
Deconstructing complex queries into simpler sub-queries allows the system to retrieve more granular and relevant information. This "chain-of-thought in retrieval" strategy ensures that each component of the query is addressed comprehensively, leading to more accurate and contextually appropriate responses.
4.5 Prompt Engineering and Retrieval Augmentation
Carefully designed prompts are essential for guiding the generative model on how to utilize the retrieved context. By defining explicit instructions within the prompts, such as focusing on factual consistency or ignoring irrelevant information, the system can produce more reliable and accurate outputs.
4.6 Continuous Evaluation and Feedback Loops
Implementing feedback loops that capture user interactions and corrections is crucial for the continuous improvement of RAG systems. By refining retrieval rankers and adjusting prompt templates based on user feedback, the system can evolve to meet changing requirements and enhance overall performance.
4.7 Integration with Existing Tools and Services
LlamaIndex facilitates seamless integration with various LLM backends, such as OpenAI’s GPT models and Amazon Bedrock. This interoperability allows developers to leverage existing tools and services, enhancing the adaptability and production-readiness of RAG applications.
5. Implementation Considerations
When implementing RAG systems based on Jerry Liu’s methodologies, several practical considerations must be addressed:
5.1 Document Ingestion and Indexing
Robust ingestion of diverse documents, including PDFs, presentations, and financial reports, is fundamental. Techniques such as document segmentation and metadata handling ensure that the data is structured and indexed efficiently, facilitating effective retrieval.
5.2 Retrieval Hyperparameter Tuning
Experimenting with hyperparameters like the number of passages to retrieve, ranking algorithms, and retrieval depth is essential for optimizing the balance between precision and recall. Fine-tuning these parameters can significantly impact the relevance and accuracy of generated responses.
5.3 Monitoring and Logging
Implementing comprehensive monitoring and logging mechanisms for each component of the RAG pipeline ensures that issues can be quickly identified and addressed. This includes tracking retriever logs, prompt inputs, and generative model outputs to maintain system reliability.
5.4 Modular Deployment and Scalability
Deploying retrieval and generation components as independent microservices or containerized applications allows for scalable and flexible system architecture. This modular approach facilitates independent scaling, updates, and maintenance of each component.
5.5 Knowledge Base Integration
Utilizing comprehensive knowledge bases, such as Amazon Bedrock Knowledge Base, enhances the system’s ability to store, retrieve, and manage processed documents. This integration supports efficient information retrieval and management across various data sources.
5.6 Feedback-Driven Improvement
Incorporating mechanisms to capture and utilize user feedback is crucial for the iterative improvement of RAG systems. By continuously refining retrieval strategies and prompt designs based on real-world usage, the system can better meet user needs and improve over time.
6. Comparative Analysis of Architectural Patterns
| Architecture | Pros | Cons |
|---|---|---|
| Pipelines with Explicit Retriever and Generator | Modular, easy to update components | Increased latency, potential error propagation |
| Integrated Architectures | Smoother context handling | Harder to debug or update retrieval independently |
| Chained or Multi-Hop Designs | Better for complex queries | Increased complexity and performance hits |
| End-to-End Differentiable Architectures | Potential performance gains | Difficult to scale, more experimental |
| Agentic RAG | Advanced reasoning, tool use | Requires sophisticated implementation |
7. Conclusion
The development of Retrieval-Augmented Generation applications in industrial settings demands a careful balance between architectural design, retrieval accuracy, and system scalability. Jerry Liu of LlamaIndex has provided valuable insights and solutions that address common challenges in building robust RAG systems. By advocating for modular pipelines, advanced retrieval techniques, and continuous feedback mechanisms, his approach ensures that RAG applications are both flexible and effective. Integrating these best practices with a focus on efficiency and user-centric improvement can significantly enhance the performance and reliability of RAG systems in various enterprise environments.
References

Last updated February 10, 2025