
Ready to Master Big Data? Your Journey to Learning Databricks Starts Here!
Unlock the power of data engineering, analytics, and AI with this comprehensive guide to learning Databricks from scratch.
Databricks is a powerful, unified analytics platform built by the creators of Apache Spark. It simplifies big data processing and enables data engineering, data science, machine learning, and business analytics in a collaborative environment. If you're looking to enhance your data skills, learning Databricks is a valuable investment. This guide will walk you through the essential steps and resources to get started.
Key Highlights for Your Learning Journey
- Start with the Basics: Understand core Databricks concepts like workspaces, clusters, and notebooks. Sign up for the free Databricks Community Edition to get hands-on experience without any cost.
- Master Essential Tools & Languages: Focus on learning PySpark (Python API for Spark) and Spark SQL, as these are fundamental for data manipulation and analysis within Databricks.
- Practice with Real-World Projects: Apply your knowledge by working on projects, such as building ETL (Extract, Transform, Load) pipelines or experimenting with machine learning models using MLflow.
Understanding the Databricks Ecosystem
Before diving into hands-on learning, it's crucial to grasp what Databricks is and its core components. Databricks offers a comprehensive solution for the entire data lifecycle, from ingestion to insight.
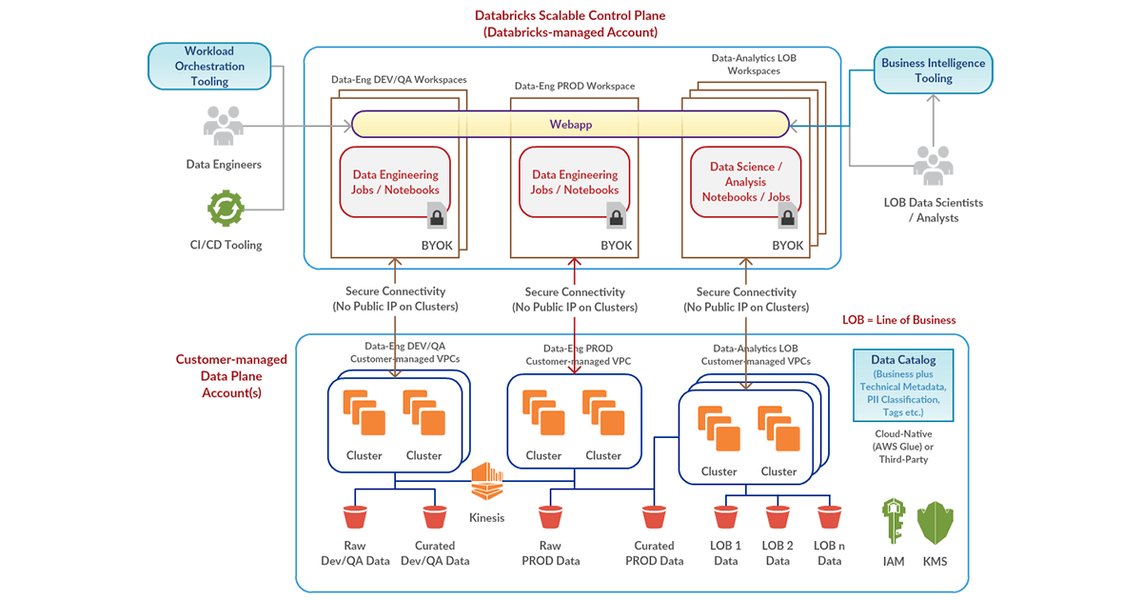
A high-level overview of Databricks architecture, illustrating its integration with cloud services like AWS.
What is Databricks?
Databricks is a cloud-based platform that provides a unified environment for data engineering, data science, machine learning, and business analytics. It was developed by the original creators of Apache Spark, a powerful open-source processing engine for big data.
Key Characteristics:
- Unified Analytics Platform: It consolidates tools for the entire data lifecycle, enabling seamless collaboration between data engineers, data scientists, and business analysts.
- Apache Spark Foundation: Leverages the speed and scalability of Apache Spark for processing massive datasets efficiently.
- Cloud Integration: Natively integrates with major cloud providers like Amazon Web Services (AWS), Microsoft Azure (as Azure Databricks), and Google Cloud Platform (GCP). Databricks deploys and manages cloud infrastructure on your behalf, within your cloud account.
- Multi-Language Support: Allows users to work with popular programming languages such as Python, Scala, R, and SQL, often within the same notebook.
Core Components of Databricks
Understanding these components is fundamental to navigating and utilizing the platform effectively:
- Workspaces: The primary environment where you organize your Databricks assets like notebooks, libraries, and experiments. It facilitates collaboration among team members.
- Clusters: These are the compute resources (groups of virtual machines) that run your data processing tasks, notebooks, and jobs. You can configure clusters based on workload requirements, specifying runtime versions, node types, and sizes.
- Notebooks: Interactive web-based documents that allow you to write and execute code, visualize results, and add narrative text. They support multiple languages and are central to exploratory analysis and development.
- Jobs: Used to run non-interactive code, such as production ETL pipelines or scheduled machine learning model training. Jobs can be scheduled to run automatically.
- Metastore (Hive Metastore): Stores metadata about your tables, databases, and partitions. This allows you to manage structured data within Databricks.
- Delta Lake: An open-source storage layer that brings ACID transactions, data versioning, and reliability to data lakes. It's deeply integrated with Databricks and enhances data quality and performance.
- DBFS (Databricks File System): A distributed file system mounted into a Databricks workspace, allowing you to interact with cloud storage (like S3, Azure Blob Storage, GCS) using familiar file system paths.
Key Capabilities
Databricks supports a wide range of data-driven tasks:
- Data Processing and ETL: Efficiently transform and prepare large datasets for analysis or machine learning.
- Exploratory Data Analysis (EDA): Analyze and visualize data to uncover patterns, anomalies, and insights.
- Machine Learning (ML): Build, train, tune, and deploy machine learning models at scale using tools like MLflow for experiment tracking and model management.
- Business Intelligence (BI): Connect with BI tools such as Tableau, Power BI, and Looker to create interactive dashboards and reports using Databricks SQL.
- Generative AI and LLMs: Provides functionalities to access and integrate Large Language Models (LLMs), including those from OpenAI, directly within data pipelines and workflows.
Setting Up Your Learning Environment
The best way to learn Databricks is by doing. Fortunately, there are accessible ways to get started:
- Databricks Community Edition: This is a free, limited-resource version of Databricks perfect for beginners. It provides a micro-cluster, a cluster manager, and a notebook environment to learn Spark and core Databricks features. You can sign up at community.cloud.databricks.com.
- Cloud Provider Free Trials: Major cloud providers (AWS, Azure, GCP) offer free trials that often include credits you can use to explore their managed Databricks services (e.g., Azure Databricks). This allows you to experience the full platform capabilities in a production-like environment.
Once you have access, familiarize yourself with the Databricks UI: navigate the workspace, create a simple cluster, and open a new notebook.
Your Structured Learning Path for Databricks
A structured approach will help you build a solid foundation and progressively tackle more complex topics. Here’s a recommended step-by-step guide:
Step 1: Define Your Learning Goals
Before you begin, clarify what you want to achieve with Databricks. Are you interested in:
- Data Engineering (building robust data pipelines)?
- Data Science and Machine Learning (developing and deploying models)?
- Data Analysis and Business Intelligence (querying data and creating visualizations)?
Your goals will help you focus your learning efforts. For instance, if you're new to big data, start with foundational concepts. Set realistic milestones for yourself.
Step 2: Master the Basics of the Databricks Interface
Get comfortable with the Databricks environment:
- Navigating the Workspace: Understand how to create folders, notebooks, and manage assets.
- Creating and Managing Clusters: Learn how to configure and launch a cluster, understand cluster settings (runtime, node types), and terminate clusters to manage costs.
- Using Notebooks: Practice creating notebooks, writing code cells (e.g., Python, SQL), running cells, and understanding notebook outputs. Explore features like markdown cells for documentation and visualization capabilities.
- Importing Data: Learn how to upload small datasets (e.g., CSV files) or connect to cloud storage to access larger datasets.
Step 3: Learn Core Programming Languages for Databricks
Databricks leverages Apache Spark, so understanding its APIs is crucial:
- PySpark (Python API for Spark): This is the most popular language for Databricks. Focus on Spark DataFrames for structured data manipulation. Learn common transformations (
select,filter,groupBy,join) and actions (show,count,collect). - Spark SQL: If you're familiar with SQL, you can leverage Spark SQL to query data stored in tables or directly on files. Learn how to create tables, run SQL queries within notebooks, and use SQL functions.
- Scala: While Python is more common for data science, Scala is Spark's native language and offers performance benefits for complex data engineering tasks. It's good to be aware of its availability.
Step 4: Explore Data Engineering Concepts
Data engineering is a core use case for Databricks:
- ETL Pipelines: Learn to build pipelines to extract data from various sources, transform it (clean, aggregate, enrich), and load it into a target system or data lake.
- Delta Lake: Understand how Delta Lake provides reliability (ACID transactions), performance (indexing, caching), and time travel (data versioning) for your data lake. Practice creating Delta tables and performing operations like
MERGE. - Workflows and Jobs: Learn how to automate your data pipelines by creating and scheduling jobs. Understand job parameters, monitoring, and alerting.
Step 5: Dive into Data Science and Machine Learning
Databricks provides a robust environment for ML:
- Databricks Runtime for Machine Learning: This specialized runtime comes pre-installed with popular ML libraries (e.g., scikit-learn, TensorFlow, PyTorch) and Conda for managing Python environments.
- MLflow: A critical tool for managing the end-to-end machine learning lifecycle. Learn to use MLflow for:
- Tracking: Logging experiments, parameters, metrics, and artifacts.
- Projects: Packaging code for reproducibility.
- Models: Managing and deploying models.
- Registry: A centralized model store for versioning, staging, and annotating models.
- Feature Engineering: Learn techniques to create and select relevant features for your ML models within Databricks.
- Model Training and Tuning: Practice training various types of models and using hyperparameter tuning techniques.
- Accessing LLMs: Explore how Databricks allows you to connect to and utilize Large Language Models (e.g., from OpenAI) within your analytical workflows.
Step 6: Understand Data Warehousing and Business Intelligence
- Databricks SQL: Explore this service for running SQL queries on your data lake, creating visualizations, and building dashboards. Learn about SQL Warehouses (formerly SQL Endpoints) which provide optimized compute for SQL queries.
- Connecting to BI Tools: Understand how to connect Databricks to popular BI tools like Tableau, Microsoft Power BI, or Looker to enable self-service analytics for business users.
Visualizing Your Learning Path and Skill Development
To help you conceptualize your journey and the skills you'll acquire, consider the following:
Roadmap to Mastering Databricks
This mindmap outlines a structured learning path, from fundamental concepts to advanced applications. It serves as a visual guide to navigate the various domains within Databricks and plan your study progression effectively.
Essential Skills for Databricks Proficiency
The radar chart below illustrates key skill areas crucial for becoming proficient with Databricks. The different lines represent aspirational skill levels for a beginner, an intermediate user, and an advanced practitioner. Aim to develop these skills progressively. Your focus might vary depending on whether your primary interest is data engineering, data science, or data analytics.
Focus Areas in Databricks Learning
Databricks caters to various data roles. Understanding these focus areas can help you tailor your learning path. The table below outlines common roles, the skills they require, typical tasks performed, and relevant Databricks features to concentrate on.
| Focus Area | Key Skills/Concepts | Typical Tasks | Recommended Databricks Features |
|---|---|---|---|
| Data Engineering | PySpark, Scala, SQL, ETL/ELT design, Data modeling, Delta Lake, Workflow orchestration, Performance tuning | Building and maintaining data pipelines, Data cleaning and transformation, Data quality management, Optimizing data storage and processing | Notebooks, Jobs, Delta Lake, Structured Streaming, DBFS, Clusters, Autoloader |
| Data Science / Machine Learning | Python (Pandas, NumPy, Scikit-learn), R, Statistical analysis, ML algorithms, MLflow, Feature engineering, Model deployment | Exploratory data analysis, Building and training ML models, Experiment tracking, Model validation and tuning, Deploying models to production | Notebooks, MLflow (Tracking, Projects, Models, Registry), Databricks Runtime for ML, Feature Store, Clusters |
| Data Analysis / Business Intelligence | SQL, Data visualization, Dashboard creation, Understanding business requirements, Connecting to BI tools | Querying data lakes/warehouses, Generating reports and dashboards, Ad-hoc analysis, Presenting insights to stakeholders | Databricks SQL, SQL Warehouses, Notebooks (SQL, Python for viz), Visualization tools, Connectors for BI tools (Power BI, Tableau) |
Leveraging Learning Resources
A wealth of resources is available to support your Databricks learning journey:
- Official Databricks Documentation & Tutorials: The Databricks website (docs.databricks.com) is the most comprehensive and up-to-date resource. It offers "Getting Started" guides, tutorials for various tasks (EDA, ETL), and deep dives into specific features.
- Databricks Training & Certification: Databricks offers free on-demand courses and paid training programs, along with certifications to validate your skills for roles like Data Engineer, Data Scientist, and Machine Learning Engineer. Check out their offerings at databricks.com/learn/training.
- Online Learning Platforms: Websites like DataCamp, Udemy, Coursera, and edX host numerous courses on Databricks, Apache Spark, PySpark, and related technologies. These often include hands-on labs and projects.
- Community Forums and Blogs:
- The official Databricks Community (community.databricks.com) is a great place to ask questions, share knowledge, and find solutions.
- Platforms like Medium, Analytics Vidhya, and Reddit (e.g., r/dataengineering, r/datascience) have many articles, guides, and discussions about Databricks.
- Hands-on Projects: The most effective way to solidify your understanding is by working on projects. Start with simple tasks using sample datasets (often provided by Databricks tutorials) and gradually move to more complex, real-world scenarios.
- Databricks Command-Line Interface (CLI): For users who prefer working from the terminal or need to automate tasks, the Databricks CLI allows you to interact with the Databricks platform.
This video provides a beginner's guide to Databricks, explaining its core concepts and how it works, perfect for those new to the platform.
Frequently Asked Questions (FAQ)
What programming language should I learn first for Databricks?
Is Databricks free to learn?
Do I need to know Apache Spark before learning Databricks?
How long does it take to learn Databricks?
What are some real-world applications of Databricks?
Recommended Next Steps
Continue your learning journey by exploring these related topics:
- How to build an ETL pipeline in Databricks using PySpark.
- What are the best practices for managing ML models with MLflow on Databricks.
- Explore advanced features of Delta Lake for data reliability and performance.
- How to connect Power BI to Databricks for data visualization.
References
Last updated May 8, 2025