
揭秘大模型代码生成能力:全方位测评方案深度解析
探索如何科学评估AI编程助手,从基准测试到未来趋势,洞悉智能代码生成的真实水平。
核心看点速览
- 多维度评估框架: 理解评估大模型代码生成不仅关注代码的正确性,还需考量其可读性、效率、安全性及处理复杂任务的能力。
- 标准化基准测试的重要性: 掌握如 HumanEval、BigCodeBench 等行业公认的基准测试集,它们为模型性能比较提供了统一标尺。
- 关键评价指标解读: 熟悉 Pass@k、单元测试通过率、代码复杂度及人工评审等核心指标,量化分析模型生成的代码质量。
引言:为何要测评大模型生成的代码?
随着大型语言模型(LLM)在软件开发领域的飞速发展,其代码生成能力日益受到关注。从自动编写函数、补全代码片段到辅助调试和重构,LLM展现出巨大的潜力。然而,要确保这些AI生成的代码不仅能够运行,而且高效、安全、易于维护,一套全面而科学的测评方案至关重要。本指南将深入探讨评估LLM代码生成能力的各个方面,帮助开发者和研究人员理解如何衡量这些先进工具的真实表现。
测评方案的核心目标与内容
评估大模型代码生成能力的目标是全面衡量模型在各种编程场景下的表现。这不仅仅是看代码能否通过编译,更涉及到多个深层次的维度。
主要评估维度
代码正确性与功能性
这是最基础也是最重要的评估维度。生成的代码是否能够准确实现需求描述的功能?是否能够通过预设的单元测试和集成测试?评估需要覆盖逻辑正确性、边界条件处理以及异常处理能力。
代码质量与可维护性
高质量的代码应具备良好的可读性、清晰的结构和恰当的注释。评估会关注代码是否遵循常见的编码规范(如PEP8对Python而言),模块化程度如何,以及是否易于理解和后续修改。可维护性直接影响软件的长期生命周期成本。

代码审查是保证代码质量的重要环节,AI生成的代码同样需要此类评估。
代码效率与性能
生成的代码在执行效率(时间复杂度、空间复杂度)和资源消耗方面表现如何?虽然LLM可能优先保证功能实现,但对于性能敏感的应用,评估代码的运行效率是必不可少的。
安全性与合规性
生成的代码是否存在已知的安全漏洞(如SQL注入、跨站脚本等)?是否符合相关的行业标准和数据隐私法规?随着AI在关键系统中的应用增加,代码安全性评估愈发重要。
上下文理解与复杂任务处理能力
模型能否理解复杂的上下文信息,包括跨文件依赖、现有代码库的风格和结构?能否处理涉及多步骤推理、API调用或特定算法实现的复杂编程任务?这体现了模型解决实际工程问题的能力。
服务能力与用户体验
对于作为工具或服务提供的大模型,其响应速度、稳定性、API的易用性以及与开发环境的集成程度也会纳入考量。这直接影响开发者的使用体验和效率。
关键测评基准 (Benchmarks)
标准化的基准测试为不同LLM的代码生成能力提供了一个公平比较的平台。它们通常包含一系列预定义的编程问题、任务描述和评估标准。
HumanEval
HumanEval 由 OpenAI 开发,是目前应用最广泛的代码生成基准之一。它包含164个手写的Python编程问题,旨在评估模型生成函数级代码的能力。这些问题覆盖了语言理解、算法、基础数学等多个方面。每个问题都附带一个函数签名、文档字符串描述和若干单元测试用例。其核心评估指标是 Pass@k。
BigCodeBench
BigCodeBench 旨在评估大型语言模型在更真实、更具挑战性的代码生成任务上的表现。它包含了比HumanEval更复杂的指令和更多样化的函数调用场景,更贴近真实开发中遇到的问题,能够测试模型处理复杂上下文和需求的能力。
MetaTool
MetaTool 专注于评估LLM在工具使用方面的能力。在现代软件开发中,有效地调用API和使用第三方库至关重要。MetaTool通过包含触发单工具和多工具使用场景的提示,来检验模型是否能正确理解任务需求并选择、运用合适的工具(如库函数、API)。
其他重要基准
- APPS (Automated Programming Progress Standard): 包含从入门级到竞赛级的Python编程问题,根据自然语言规范生成代码,测试用例更为严格。
- SWE-Lancer Benchmark: 由OpenAI发布,包含约1400个真实的自由职业编程任务,聚焦于评估模型在真实世界复杂场景中的代码生成表现。
- LMC-Eval: 侧重于逻辑推理与代码生成的结合,评估模型在需要复杂逻辑推断的编码任务上的准确性。
- FullStack Bench 和 Sandbox Fusion: 由字节跳动开源,是针对全栈编程领域的代码大模型基准测试数据集和工具,旨在全面评估模型在真实开发场景中的表现。
核心评估指标与方法
为了量化LLM的代码生成能力,测评方案会采用一系列客观和主观的评估指标和方法。
客观评估与自动化指标
这类评估依赖于可量化的标准,通常通过自动化脚本执行。
Pass@k
这是衡量代码生成模型性能最常用的指标之一,尤其在HumanEval等基准中。它表示模型针对一个问题生成 \(k\) 个代码候选方案,其中至少有一个方案能够成功通过所有预定义单元测试的概率。例如,Pass@1衡量的是模型一次生成即正确的概率,而Pass@100则表示在生成100个候选方案后能找到正确解的概率。
单元测试通过率
直接衡量生成的代码在多大程度上满足了功能需求。通过运行一系列针对代码功能的单元测试,统计通过测试用例的比例。这是评估代码正确性的直接方法。
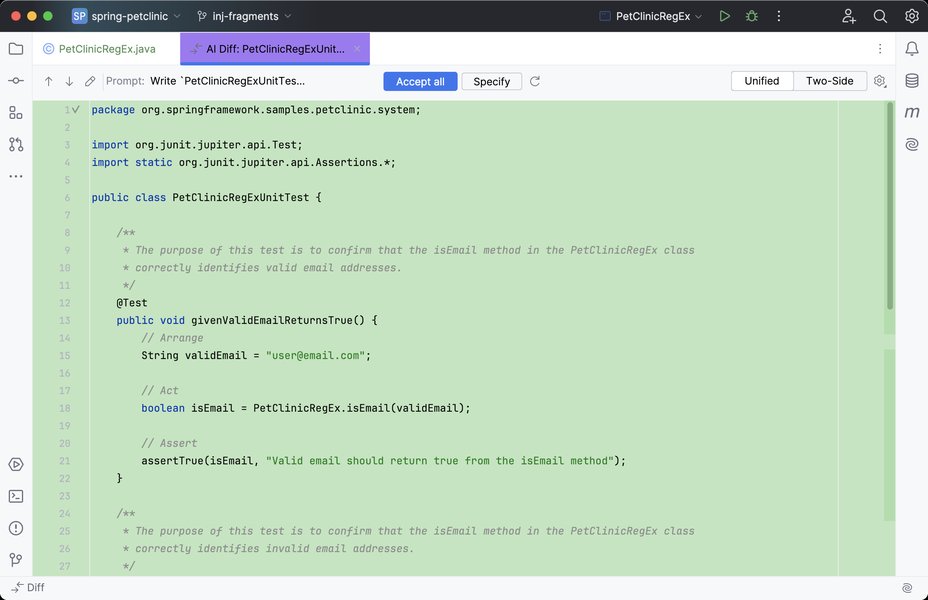
AI不仅能生成代码,也能辅助生成单元测试,这是评估的重要环节。
代码复杂度指标
例如圈复杂度(Cyclomatic Complexity)、代码行数(Lines of Code)、模块耦合度等。这些指标有助于评估代码的结构复杂性和潜在的可维护性问题。
语义相似度/代码等价性
虽然直接的文本匹配(如BLEU分数,源于机器翻译)在代码评估中有局限性,但可以用于比较生成代码与参考代码之间的表面相似性。更高级的方法会尝试评估语义等价性,即判断两段不同代码是否实现相同功能,例如通过CodeBERT等模型进行嵌入表示比较,或利用CodeJudge这类框架进行语义正确性评估。
静态分析
使用静态分析工具检测代码中的潜在错误、风格问题、未使用的变量、安全漏洞等。这可以在不实际运行代码的情况下发现问题。
主观评估与人工/模型辅助评审
某些代码质量属性难以完全通过自动化指标捕捉,需要人工或借助其他LLM进行评估。
代码可读性与可维护性
由经验丰富的程序员对生成代码的清晰度、逻辑结构、命名规范、注释质量等进行主观评分。
实现思路的合理性与优雅性
评估代码解决问题的思路是否简洁、高效、易于理解,是否存在更优的实现方式。
LLM-as-a-judge
利用另一个(通常是更强大或经过特定微调的)LLM作为“裁判”,对生成代码的质量、风格、正确性等方面进行评估。例如,TruthfulQA基准测试使用名为 "GPT-Judge" 的评估器。这种方法试图在一定程度上自动化主观评估过程。
多维度能力对比:LLM代码生成模型雷达图
为了更直观地比较不同大型语言模型在代码生成方面的综合能力,我们可以使用雷达图。下图展示了三个假设的LLM(SyntaxMaster, LogicWeaver, DevHelper X)在六个关键维度上的表现评估。这些维度包括代码正确性、HumanEval得分、代码可读性、生成效率、安全性以及复杂任务处理能力。得分越高表示在该维度上表现越好。请注意,这些数据是示例性的,仅为说明雷达图的应用。
通过这样的雷达图,我们可以清晰地看到不同模型之间的优势和劣势。例如,LogicWeaver Pro 可能在代码正确性和复杂任务处理方面表现突出,而 DevHelper X 可能在代码可读性方面更具优势。这种多维度的比较有助于根据具体需求选择最合适的模型。
测评流程与实施步骤
一个系统化的LLM代码生成测评流程通常包括以下关键步骤:
- 任务定义与数据集准备:明确评估目标(例如,特定编程语言、任务类型)。准备高质量的测试数据集,包含清晰的问题描述、输入示例、预期的输出或行为,以及参考代码(如果适用)和单元测试用例。数据集应具有代表性,覆盖不同难度和类型的编程任务。
- 模型推理与代码生成:使用待评估的LLM,根据测试数据集中的问题描述生成代码。可以根据需要生成单个或多个候选代码样本(用于计算Pass@k等指标)。
- 自动化测试执行:将生成的代码在安全的环境(沙箱)中执行,运行预定义的单元测试用例。记录测试结果,如通过/失败状态、运行时间、资源消耗等。
- 指标计算与性能评估:根据测试结果计算各项自动化指标,如Pass@k、测试用例通过率、代码复杂度等。
- 人工/模型辅助评审(可选但推荐):对于通过自动化测试的代码,可以进一步进行人工评审或使用LLM-as-a-judge进行评估,关注代码质量、可读性、可维护性、安全性等方面。
- 结果分析与报告生成:汇总所有评估结果,进行综合分析。识别模型的优势和不足,比较不同模型或不同版本模型的性能差异。生成详细的评估报告。
- 迭代改进:根据评估结果,对模型进行微调、改进提示工程策略或调整训练数据,以提升其代码生成能力。测评应是一个持续的过程,伴随模型的迭代更新。
自动化测试是验证AI生成代码正确性的关键步骤。
常用工具和框架如 DeepEval、Evidently AI 等可以辅助完成评估流程中的部分任务,例如指标计算、结果可视化等。
LLM代码生成测评体系概览:思维导图
为了系统地理解大模型代码生成测评的各个组成部分,下面的思维导图清晰地展示了其核心要素,包括测评维度、关键基准、主要评估指标、测评流程以及面临的挑战与未来趋势。这个导图可以帮助我们构建一个全面的测评框架。
(可读性、可维护性、风格)"] id1_3["执行效率与资源消耗"] id1_4["安全性与合规性"] id1_5["复杂任务解决能力"] id1_6["上下文理解能力"] id2["关键测评基准 (Benchmarks)"] id2_1["HumanEval"] id2_2["BigCodeBench"] id2_3["MetaTool"] id2_4["APPS (Automated Programming
Progress Standard)"] id2_5["SWE-Lancer"] id2_6["FullStack Bench"] id3["主要评估指标 (Metrics)"] id3_1["自动化指标"] id3_1_1["Pass@k"] id3_1_2["单元测试通过率"] id3_1_3["代码复杂度 (如圈复杂度)"] id3_1_4["语义相似度/等价性 (如BLEU, CodeBERT)"] id3_1_5["静态分析结果"] id3_2["人工/模型辅助指标"] id3_2_1["代码可读性评分"] id3_2_2["逻辑合理性评估"] id3_2_3["LLM-as-a-judge"] id3_2_4["安全漏洞评审"] id4["测评流程与方法"] id4_1["任务定义与数据集准备"] id4_2["模型推理与代码生成"] id4_3["自动化测试 (沙箱执行)"] id4_4["人工/模型辅助评审"] id4_5["结果分析与报告"] id4_6["持续监控与迭代"] id5["挑战与未来趋势"] id5_1["挑战"] id5_1_1["评测标准的多样性与主观性"] id5_1_2["真实世界项目复杂性的模拟"] id5_1_3["测试用例覆盖全面性"] id5_1_4["评估成本与效率"] id5_1_5["基准老化与模型能力快速发展"] id5_2["未来趋势"] id5_2_1["更全面的自动化评估框架"] id5_2_2["强化安全与合规性测试"] id5_2_3["LLM辅助评测的广泛应用"] id5_2_4["动态分析与运行时行为评估"] id5_2_5["跨语言、跨平台统一测评"] id5_2_6["针对特定领域优化的基准"]
此思维导图将评估过程分解为若干关键领域,从宏观的测评维度到具体的基准和指标,再到实施流程和未来展望,为构建或理解LLM代码生成测评方案提供了清晰的指引。
关键代码生成基准测试概览表
为了方便比较和选择,下表总结了几个主流的代码生成基准测试,包括它们的关注点、常用指标和典型任务示例。理解这些基准的特点有助于针对性地评估LLM在不同代码生成场景下的能力。
| 基准名称 (Benchmark Name) | 主要关注点 (Primary Focus) | 常用指标 (Common Metrics) | 示例任务 (Example Task) |
|---|---|---|---|
| HumanEval | 函数级代码生成、算法、基础数学 (主要针对Python) | Pass@k, 单元测试通过率 | 根据自然语言描述编写一个Python函数来解决特定问题,如列表排序、字符串处理。 |
| BigCodeBench | 更复杂、更真实的编程任务,涉及多样函数调用和复杂指令。 | Pass@k, 代码正确性, 任务完成度 | 解决需要多步骤逻辑或调用外部API才能完成的编程问题,更贴近实际开发。 |
| MetaTool | LLM的工具使用意识与能力,如API调用、库函数选择。 | 工具选择准确率, 生成代码的有效性 | 根据任务描述,模型需判断应使用哪个库/API,并生成正确的调用代码。 |
| APPS (Automated Programming Progress Standard) | 从入门到竞赛级别的Python编程问题,基于自然语言规范生成完整代码。 | 测试用例通过率, 代码正确性 | 解决编程竞赛网站上常见的算法题目,要求输入输出完全匹配。 |
| SWE-Lancer | 基于真实的自由职业编程任务,评估LLM在复杂、实际项目场景中的表现。 | 任务完成度, 代码质量, 解决方案的实用性 | 完成一个小型模块或功能,可能涉及理解现有代码库、处理模糊需求等。 |
| FullStack Bench | 全栈编程领域的代码生成,覆盖前端、后端、数据库等多种技术栈。 | 功能完整性, 代码集成性, 安全性 | 根据需求生成一个简单的全栈应用组件,如用户注册登录模块。 |
选择合适的基准测试取决于具体的评估目标。例如,如果关注基础算法能力,HumanEval和APPS是好选择;如果关注实际项目中的复杂任务,BigCodeBench和SWE-Lancer可能更合适;而MetaTool则专注于工具使用能力的评估。
深入了解:AI代码生成基准测试探讨
大型语言模型在代码生成方面的进展令人瞩目。为了客观评估这些模型的能力,学术界和工业界开发了多种基准测试。下面的视频深入探讨了AI代码生成模型的基准测试方法,分析了不同模型的表现,并对未来发展进行了展望。通过观看此视频,您可以更深入地了解当前AI代码生成评估的现状和挑战。
视频中,专家们讨论了现有基准测试(如HumanEval)的优点和局限性,强调了评估代码生成不仅仅是看功能正确性,还应包括代码质量、可维护性和安全性等方面。此外,视频还可能涉及如何设计更有效的基准来反映真实世界的编程挑战,以及如何解读不同模型在这些基准上的得分,为我们选择和应用AI代码生成工具提供了有价值的参考。
挑战与未来趋势
尽管LLM代码生成的测评方案不断完善,但仍面临一些挑战,同时也展现出清晰的发展趋势。
当前面临的挑战
- 缺乏统一的完美评估标准: 对于复杂的代码生成任务,往往没有唯一的“正确”答案。代码功能相同但实现方式多样,这给基于精确匹配的评估带来困难。
- 测试用例的覆盖度与质量: 构建能全面覆盖各种边缘情况和复杂逻辑的测试用例成本高昂且具挑战性。低质量或覆盖不足的测试用例可能导致评估结果失真。
- 评估成本与效率: 依赖大量人工评审或复杂LLM作为裁判的评估方法,成本较高,难以大规模、高频率进行。
- 模型能力的快速发展与基准老化: LLM技术迭代迅速,现有基准可能很快变得过于简单,无法有效区分更先进模型的性能。
- 真实世界复杂性的模拟: 当前多数基准仍侧重于函数级或小片段代码生成,难以完全模拟真实项目中涉及多文件、多模块交互、大型代码库理解等复杂场景。
- 数据污染问题: 如果模型在训练数据中接触过测评基准中的题目或类似内容,其在基准上的表现可能会虚高,不能真实反映其泛化能力。
未来发展趋势
- 更先进、更综合的评估框架: 结合静态分析、动态分析(实际运行并观察行为)、符号执行和语义理解的综合评估方法将更受重视。
- 强化安全性与合规性测试: 自动检测生成代码中的安全漏洞、隐私泄露风险以及是否符合开源许可证等合规性要求,将成为测评的重要组成部分。
- 更强大的LLM作为评判者: 利用经过专门训练和校准的LLM辅助或替代人工进行代码质量、可读性、逻辑性等方面的评估,提高效率和一致性。
- 更大规模、更多样化的基准: 开发能够反映真实世界编程任务多样性和复杂性的大型基准,例如包含整个项目或大型模块的生成与修复任务。
- 工具调用与交互式编程能力评估: 测评模型不仅生成静态代码,还需评估其与开发环境、版本控制系统、调试器等工具交互的能力。
- 跨语言、跨平台测评体系: 建立能够公平评估不同编程语言(Python, Java, C++, JavaScript等)和不同平台(Web, 移动, 后端)代码生成能力的统一框架。
- 持续学习与自适应评估: 开发能够根据模型演进和新出现的编程范式动态调整和更新的评估基准和方法。
常见问题解答 (FAQ)
推荐探索
参考文献
Last updated May 13, 2025