
Innovative Methods for Comparing LLM Performance
Exploring the Diverse Approaches Websites Use to Benchmark Top Large Language Models
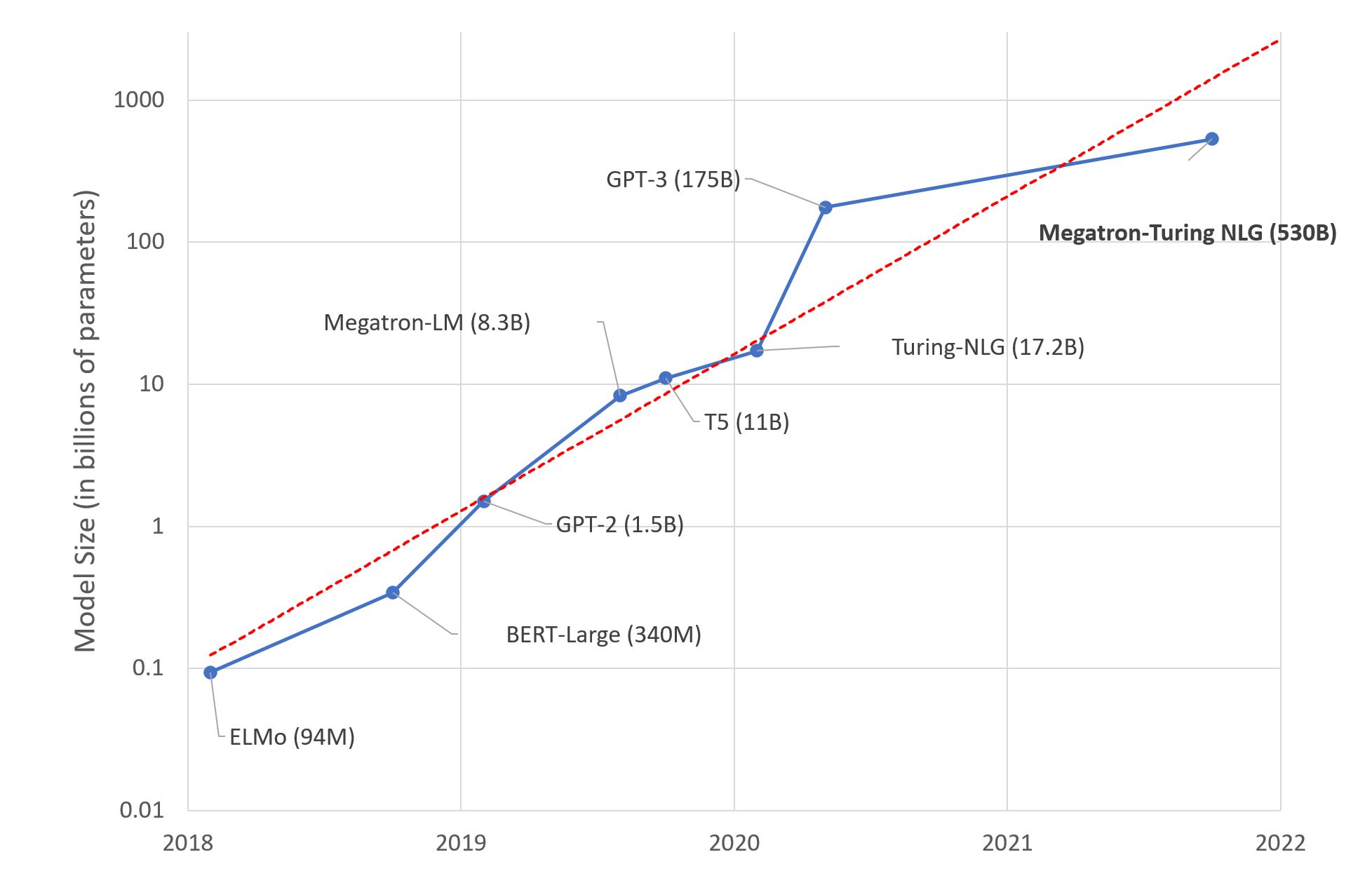
Key Takeaways
- Comprehensive Benchmarking: Utilizing standardized tests and specialized tasks to evaluate various aspects of LLM performance.
- User-Centric Evaluations: Incorporating human feedback and real-world usage scenarios to assess model effectiveness and reliability.
- Technical and Multimodal Metrics: Measuring efficiency, scalability, and the ability to handle multiple data types beyond text.
1. Standardized Benchmark Testing
Standardized benchmarks are foundational in assessing the capabilities of Large Language Models (LLMs). These benchmarks provide a consistent set of tasks and metrics, enabling fair comparisons across different models.
a. Established Benchmarks
Benchmarks such as GLUE (General Language Understanding Evaluation) and SuperGLUE are widely used to evaluate models on a variety of language understanding tasks, including sentiment analysis, question answering, and textual entailment.
The MMLU (Massive Multitask Language Understanding) test extends this by assessing models across 57 diverse subjects, ranging from humanities to STEM fields. Another notable benchmark is Big-bench, which encompasses over 200 tasks spanning linguistics, mathematics, biology, and physics, providing a broad evaluation spectrum.
b. Task-Specific Benchmarks
In addition to general benchmarks, task-specific evaluations focus on particular capabilities of LLMs. For instance, GSM8K assesses mathematical reasoning and problem-solving skills, while TruthfulQA measures the ability of models to generate accurate and truthful responses.
2. Leaderboards with Task-Specific Benchmarks
Leaderboards are dynamic tools that rank LLMs based on their performance across various benchmarks and tasks. They provide a clear, visual representation of where different models stand relative to each other.
a. Comprehensive Leaderboards
Platforms like the Big Code Models Leaderboard and the CanAiCode Leaderboard focus on code generation and multilingual programming tasks. These leaderboards assess models on diverse programming-related tasks, evaluating multitask accuracy to reflect real-world use cases.
The 2024 LLM Leaderboard compares over 30 cutting-edge models based on real-world use cases, considering factors such as context size, processing speed, cost-effectiveness, and quality. This comprehensive approach allows researchers and developers to make informed trade-offs based on specific needs.
b. Interactive Dashboards and Visualization Tools
Interactive dashboards and visualization tools, such as Interactive Dashboards and Performance Heatmaps, offer users an at-a-glance understanding of model strengths and weaknesses. These tools enable users to explore detailed comparisons and identify areas where specific models excel or require improvement.
3. Human-Centric Evaluations
Human-centric evaluations focus on gathering and analyzing human feedback to assess the performance of LLMs. These evaluations provide insights into the models' ability to generate coherent, relevant, and engaging responses.
a. Human Judging Panels and User Surveys
Deploying panels of human judges to rate the quality, relevance, and coherence of model-generated responses is a common method. Additionally, user surveys and real-world feedback help gauge user satisfaction and perceived intelligence of the models.
b. Crowdsourced Testing
Platforms like Chatbot Arena utilize crowdsourced human evaluations, where users interact with multiple models simultaneously and vote on their preferences. This method provides dynamic, user-driven assessments that reflect a variety of real-world interactions.
4. Technical Performance Metrics
Technical metrics evaluate the efficiency and scalability of LLMs, ensuring that they meet operational requirements for various applications.
a. Inference Speed and Latency
Measuring the speed at which models can generate responses (inference speed) and the delay between input and output (latency) is crucial for applications requiring real-time interactions, such as chatbots and virtual assistants.
b. Memory Usage and Computational Efficiency
Evaluating the memory consumption (VRAM requirements) and overall computational efficiency ensures that models can be deployed in resource-constrained environments. Metrics like memory usage and processing throughput are essential for optimizing model performance.
c. Cost Analysis
Assessing the operational costs, such as the cost per 1000 tokens, helps organizations determine the cost-effectiveness of deploying specific models, especially at scale.
5. Task-Specific Assessments
Task-specific assessments focus on evaluating LLMs' performance in particular applications, allowing for targeted comparisons based on user needs.
a. Code Generation and Debugging
Assessing models' ability to generate and debug code is vital for applications in software development. Benchmarks focus on the accuracy, efficiency, and creativity of code produced by different models.
b. Creative Writing and Content Generation
Evaluating the capability to generate creative content, such as poetry, stories, or articles, highlights models' proficiency in producing engaging and coherent narratives.
c. Summarization and Translation
Comparing models' effectiveness in condensing information and translating text between languages provides insights into their versatility and adaptability across different linguistic tasks.
6. Multimodal Capabilities Assessment
Multimodal evaluations assess models' ability to handle and integrate multiple data types, such as text, images, audio, and video, enhancing their applicability in diverse applications.
a. Integration with Other Data Types
Models that can process not only text but also images or audio inputs offer greater versatility. Assessing their performance across these modalities ensures they meet the demands of applications requiring comprehensive data understanding.
b. Cross-Modal Tasks
Testing models on tasks that require understanding and generating multiple data types simultaneously, such as generating image descriptions or combining text and visual data, highlights their integrated processing capabilities.
7. Real-Time Benchmarking and Continuous Evaluation
Real-time benchmarking involves continuously assessing models as they evolve, incorporating ongoing user feedback and updating rankings to reflect current performance.
a. Continuous Performance Monitoring
Platforms like lmarena.ai perform ongoing assessments of LLMs, ensuring that performance metrics remain up-to-date with the latest model iterations and improvements.
b. Adaptive Leaderboards
Leaderboards that update in real-time based on recent evaluations and user interactions provide a dynamic view of model performance, capturing the latest advancements and refinements.
8. Error Analysis and Hallucination Detection
Error analysis focuses on identifying and quantifying instances where LLMs produce incorrect or fabricated information, while hallucination detection aims to assess the reliability and factual accuracy of model outputs.
a. Fact-Checking Mechanisms
Implementing automated fact-checking systems to verify the accuracy of generated responses helps in quantifying the rate of factual errors and ensuring the reliability of the models.
b. Bias and Fairness Audits
Analyzing model outputs for potential biases or unfair representations across different demographics or topics ensures that models adhere to ethical standards and promote fairness.
9. Cost and Efficiency Analysis
Evaluating the cost-effectiveness and computational requirements of LLMs is essential for organizations considering large-scale deployments.
a. Operational Cost Evaluation
Assessing metrics like cost per 1000 tokens and overall operational expenses helps organizations determine the financial viability of using specific models in their applications.
b. Energy Efficiency and Sustainability
Measuring the energy consumption and environmental impact of deploying LLMs promotes sustainability and helps in selecting models that align with eco-friendly practices.
10. Multilingual and Cultural Adaptability
Assessing models' proficiency in multiple languages and their ability to operate within various cultural contexts ensures global applicability and inclusivity.
a. Multilingual Support Evaluation
Testing models on a wide range of languages, including low-resource languages, evaluates their ability to serve diverse user bases and handle linguistic nuances effectively.
b. Cultural Context Understanding
Evaluating models' understanding of different cultural contexts ensures that they generate appropriate and contextually relevant responses, enhancing user experience across diverse demographics.
11. Domain-Specific Evaluations
Domain-specific evaluations focus on assessing LLMs' expertise and accuracy within specialized fields, allowing for targeted improvements and applications.
a. Specialized Knowledge Areas
Testing models in niche domains such as medical diagnosis, legal analysis, or technical support evaluates their ability to handle complex, specialized tasks with precision and reliability.
b. Industry-Specific Benchmarks
Developing benchmarks tailored to specific industries ensures that models meet the unique requirements and standards of those fields, promoting their effective adoption.
12. Longitudinal Studies and Development Tracking
Longitudinal studies track the performance and improvements of LLMs over time, providing insights into their developmental trajectories and sustained capabilities.
a. Tracking Model Iterations
Monitoring how models evolve with updates and iterations showcases progress in their capabilities, highlighting areas of significant improvement and ongoing challenges.
b. Sustainability and Maintainability Metrics
Evaluating long-term viability and maintainability ensures that models remain effective and reliable in diverse applications, promoting sustained usage and trust.
13. Real-World Use Case Simulations
Simulating real-world applications provides practical insights into how LLMs perform in environments that closely mirror their intended use cases.
a. Integration into Live Applications
Deploying models into live chat interfaces or virtual assistants allows for the observation of their performance in dynamic, real-time interactions, reflecting their practical effectiveness.
b. User Interaction Analysis
Analyzing how models handle complex user queries and multi-turn interactions provides insights into their conversational abilities and adaptability in real-world scenarios.
14. Meta-Resources and Aggregated Evaluations
Meta-resources aggregate multiple evaluations and leaderboards, offering a comprehensive view of LLM performance across various criteria and benchmarks.
a. Aggregated Leaderboards
Platforms that combine results from multiple leaderboards provide users with a holistic understanding of model performance, facilitating more informed decision-making based on diverse metrics.
b. Comprehensive Performance Overviews
Aggregated evaluations present detailed overviews of model strengths and weaknesses, highlighting performance trends and areas requiring improvement across different tasks and benchmarks.
Conclusion
Comparing the performance of top Large Language Models involves a multifaceted approach that integrates standardized benchmarks, human-centric evaluations, technical metrics, and specialized assessments. By leveraging a combination of these methods, websites provide comprehensive insights into the capabilities, strengths, and limitations of various LLMs. This holistic evaluation enables users to select models that best align with their specific needs, whether they require robust multilingual support, efficient code generation, or reliable real-time interactions. As the field of artificial intelligence continues to evolve, these innovative benchmarking techniques will play a crucial role in advancing the development and application of increasingly sophisticated language models.
References
Nebuly.com Blog on LLM Leaderboards
Acorn.io - LLM Leaderboards Overview
Klu.ai Comparison of Frontier Models 2024
Evidently AI Benchmarking Guide
Upsilon IT Blog on LLM Comparison
Last updated January 30, 2025