
Unlocking Superintelligence? Building an App to Fuse the Minds of Top AI Models
A comprehensive project overview for creating a powerful application that aggregates and synthesizes responses from multiple leading foundation models.
Project Highlights
- Unified Intelligence: Access the combined power of leading LLMs like GPT, Claude, Llama, and Gemini through a single interface, eliminating the need to juggle multiple platforms.
- Enhanced Response Quality: Leverage diverse AI strengths via sophisticated aggregation techniques to generate more accurate, nuanced, comprehensive, and less biased outputs than any single model can achieve.
- Streamlined Workflow: Integrate advanced AI capabilities seamlessly into various tasks, optimizing efficiency for research, content creation, data analysis, and more, while managing costs and performance.
Introducing the Multi-LLM Aggregator Concept
Imagine an application that doesn't rely on just one AI brain, but intelligently combines the insights from several of the world's most advanced Large Language Models (LLMs), often referred to as foundation models. This is the core idea behind an LLM Aggregator app. Instead of users switching between different AI tools, this application acts as a central hub, sending a user's query to multiple top-tier models simultaneously (e.g., models from OpenAI, Anthropic, Google, Meta). It then collects their individual responses and employs sophisticated techniques to synthesize them into a single, superior output.
The value proposition is significant: by leveraging the unique strengths and perspectives of diverse models, the aggregator can produce results that are more accurate, comprehensive, creative, and robust. It can mitigate the inherent limitations of any single model, such as specific knowledge gaps, potential biases, or tendencies towards "hallucinations." This approach represents the next step in AI-as-a-Service (AIaaS), offering unparalleled flexibility and problem-solving potential.
Key Project Objectives
The development of an LLM aggregator app centers around several crucial goals:
- Unified Access: Provide a seamless, single point of interaction for querying multiple LLMs, removing the complexity of managing separate accounts and interfaces.
- Superior Response Generation: Combine the diverse capabilities of selected LLMs to generate outputs that surpass single-model results in accuracy, depth, nuance, and completeness.
- Workflow Efficiency: Offer a centralized platform for various AI-powered tasks (e.g., Q&A, summarization, content creation), streamlining user workflows.
- Intelligent Routing & Customization: Implement mechanisms to route prompts effectively (based on query type, user preference, or cost considerations) and potentially allow users to select or weight preferred models.
- Scalability & Performance: Build a robust architecture capable of handling growing user demand while optimizing for latency and cost-efficiency.
- Comprehensive Monitoring: Integrate tools for tracking usage metrics, API costs, token consumption, and response quality across all integrated models.
Core Architectural Components
A successful LLM aggregator requires several interconnected modules working in concert:
1. User Interface (UI)
A clean, intuitive interface (web app, desktop app, or mobile app) allowing users to input prompts, configure settings (like model selection), view the synthesized response, and potentially inspect individual model outputs for comparison.
2. Prompt Routing Engine
The "traffic controller" of the system. This component receives the user's prompt and intelligently decides which LLMs to query based on predefined rules, dynamic analysis of the prompt, user settings, or cost/performance goals. It may involve parallel processing to query multiple models simultaneously.
3. LLM Integration Layer (API Connectors)
This layer contains specific adapters or wrappers for each integrated LLM's API. It handles the technical details of connecting to different providers, including authentication (API keys), request formatting, handling rate limits, managing potential errors, and parsing the responses into a standardized format.
4. Response Aggregation & Synthesis Module
The "brain" of the aggregator. This crucial component implements the logic for combining the multiple responses received from the LLMs. It's where the magic of synthesis happens.

Conceptual diagram showing how multiple models (like LLMs) can be combined in an ensemble approach.
Ensemble Techniques Explained
Various strategies can be employed here, ranging in complexity:
- Best Response Selection: Choosing the single best response based on predefined criteria (e.g., highest confidence score if provided by the model, matching a specific format).
- Majority Voting: Useful for classification or multiple-choice tasks; the most common answer among the models is selected.
- Answer Merging/Concatenation: Combining different parts of responses that address different aspects of the query.
- Averaging/Weighted Averaging: Applicable if models provide numerical outputs or confidence scores; responses can be averaged, potentially weighting models known to perform better on certain tasks.
- Rank Aggregation: Combining ranked lists of results from different models.
- Synthesis using another LLM: Feeding the individual responses into a separate LLM instance tasked with summarizing, reconciling conflicts, and generating a cohesive final output.
- Weak Supervision Techniques: Methods inspired by frameworks like Snorkel AI, treating each LLM's output as a potentially noisy label or signal and intelligently combining them to infer a more accurate result.
- Reasoning Chain Aggregation: Evaluating and combining step-by-step reasoning processes (like Chain-of-Thought) from different models.
5. Context Manager
Maintains conversational history or relevant background information, feeding appropriate context to the LLMs with each new query to ensure coherent and relevant interactions, especially in chat-based applications.
6. Data Handling & Privacy Module
Ensures secure management of user data, prompts, and responses. Implements necessary security measures (encryption, access controls) and adheres to privacy regulations, especially critical when interacting with multiple third-party APIs.
7. Monitoring & Analytics Dashboard
Provides insights into the application's performance, tracks API usage per model (crucial for cost management), monitors token consumption, measures latency, and potentially collects data on response quality (e.g., via user feedback).
Visualizing the Project Structure
This mindmap outlines the key areas and components involved in building the LLM Aggregator Application.
(API Connectors)"] id2d["Aggregation & Synthesis
(Ensemble Engine)"] id2d1["Voting / Averaging"] id2d2["Synthesis LLM"] id2d3["Weak Supervision"] id2e["Context Manager"] id2f["Data Handling & Privacy"] id2g["Monitoring & Analytics"] id3["Technical Stack (Examples)"] id3a["Backend (Python/Node.js)"] id3b["Frontend (React/Vue)"] id3c["Databases (NoSQL/SQL)"] id3d["Cloud (AWS/Azure/GCP)"] id3e["Orchestration (LangChain)"] id4["Key Challenges"] id4a["Latency Management"] id4b["Cost Control"] id4c["Response Consistency"] id4d["API Variability"] id4e["Security & Privacy"] id5["Advanced Features"] id5a["RAG Integration"] id5b["Fine-Tuning Support"] id5c["Explainability"] id5d["User Feedback Loop"] id5e["Multimodality"]
Why Aggregate? Comparing Hypothetical LLM Strengths
Different foundation models excel in different areas. An aggregator leverages this diversity. This radar chart illustrates hypothetical relative strengths across various dimensions for several major LLM families. Note that these are illustrative scores (on a scale of roughly 3 to 10) meant to show *variance* and are not precise, real-time benchmarks. The goal is to demonstrate *why* combining models can be beneficial – one might be better at creative writing, another at logical reasoning or code generation.
By understanding these relative strengths (through ongoing benchmarking), the aggregator can intelligently weight or combine outputs. For instance, it might rely more heavily on a model strong in coding for programming queries, while favoring a highly creative model for generating marketing copy.
Suggested Technical Stack & Workflow
While flexible, a common technical stack could include:
- Backend: Python (with frameworks like FastAPI, Flask, or Django) or Node.js are popular choices due to robust libraries for API interaction and data processing. Libraries like LangChain or LlamaIndex can significantly simplify orchestration.
- Frontend: Modern JavaScript frameworks like React, Vue, or Svelte for building dynamic and interactive user interfaces.
- Databases: Depending on needs, NoSQL databases (like MongoDB) for flexible data storage or relational databases (like PostgreSQL) for structured data and user management. Vector databases (e.g., Pinecone, Chroma) might be needed for advanced features like RAG.
- Caching: Redis or Memcached to store recent responses and reduce redundant API calls, improving latency and lowering costs.
- Deployment: Containerization using Docker, potentially orchestrated with Kubernetes for scalability, or deployed on serverless platforms (like AWS Lambda, Google Cloud Functions) or Platform-as-a-Service (PaaS) options.
- Cloud Provider: AWS, Google Cloud, or Azure, often chosen based on existing infrastructure, specific service offerings (like managed AI/ML services, e.g., Amazon Bedrock), or cost considerations.
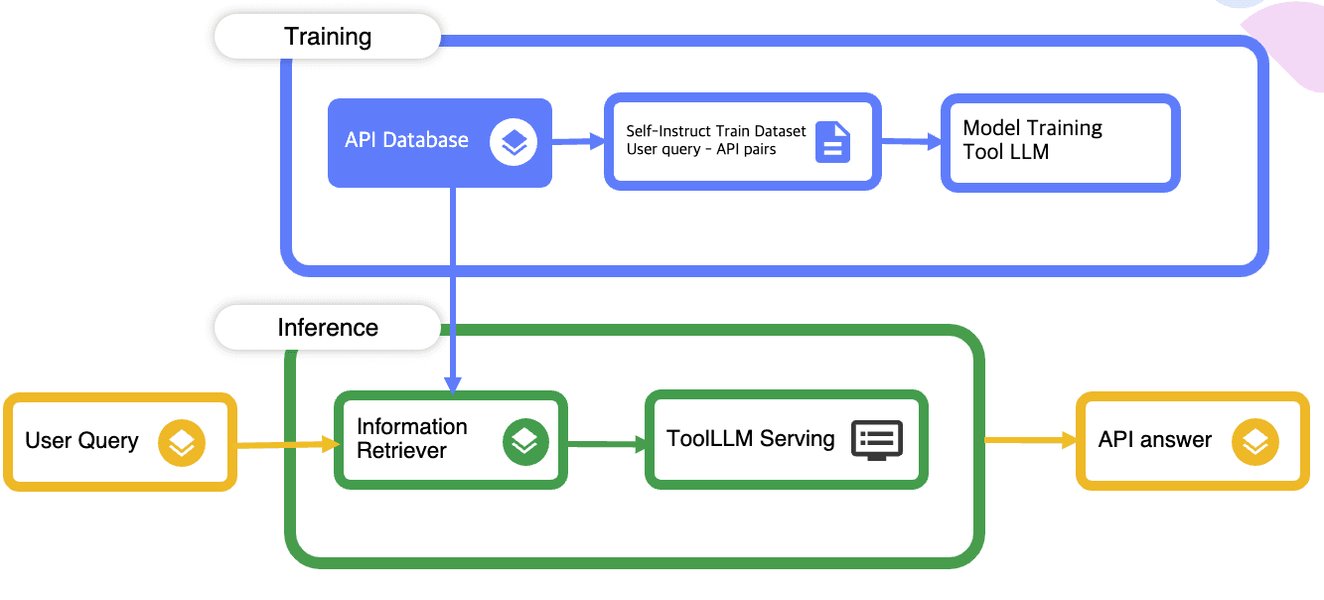
Illustrative diagram showing a potential workflow involving user input, LLM interaction, and tool usage.
Example Workflow:
- User submits a query via the UI.
- The Prompt Routing Engine analyzes the query and selects appropriate LLMs.
- The LLM Integration Layer sends formatted requests (including relevant context from the Context Manager) to the chosen model APIs in parallel.
- Responses are received and standardized.
- The Aggregation & Synthesis Module processes the responses using its configured strategy (e.g., synthesis via another LLM).
- The final, synthesized response is generated.
- The UI displays the result, potentially offering options to view individual model outputs or provide feedback.
- Monitoring logs the transaction details (models used, tokens, latency, cost).
Indicative Development Roadmap
Building such an application is typically an iterative process. Here’s a possible phased approach:
| Phase | Focus | Estimated Timeline | Key Deliverables |
|---|---|---|---|
| 1: Planning & Research | Define scope, target audience, core features, select initial LLMs, research APIs & aggregation techniques. | 1-2 Weeks | Project plan, requirements document, initial model list, architecture overview. |
| 2: Architecture & Setup | Design detailed technical architecture, set up development environment, establish basic API connections. | 1-2 Weeks | Architecture diagrams, environment setup, proof-of-concept API connectivity. |
| 3: Core Integration | Develop robust API connectors for initial LLMs, build the prompt routing logic. | 2-4 Weeks | Functional API integration layer, basic prompt router. |
| 4: Aggregation Engine V1 | Implement initial response aggregation/synthesis logic (e.g., simple selection or basic synthesis). | 2-4 Weeks | Working aggregation module combining responses from integrated models. |
| 5: UI/UX Development | Build the user interface for input, output display, and basic controls. | 2-3 Weeks | Functional front-end application connected to the backend. |
| 6: Testing & Evaluation | Conduct thorough testing (functional, performance, quality), refine aggregation based on results. | 2-3 Weeks | Test reports, refined aggregation algorithms, initial performance benchmarks. |
| 7: Deployment & Monitoring Setup | Deploy the application to a staging/production environment, implement monitoring and logging. | 1-2 Weeks | Deployed application, monitoring dashboards (usage, cost, performance). |
| 8: Iteration & Improvement | Gather user feedback, add more LLMs, enhance aggregation techniques, add advanced features (RAG, etc.). | Ongoing | Regular updates, new features, performance optimizations. |
Anticipating the Challenges
Developing an LLM aggregator involves navigating several potential hurdles:
- Latency: Querying multiple LLMs, especially large ones, inherently takes time. Parallel processing helps, but the overall response time will be constrained by the slowest model in the chain. Caching and smart routing are essential.
- Cost Management: API calls to premium LLMs can be expensive, especially at scale. Careful monitoring, implementing usage quotas, selecting cost-effective models where appropriate (e.g., via providers like Together AI or Fireworks), and optimizing token usage are crucial.
- Response Inconsistency & Conflict: Different models may provide contradictory or factually incorrect information. The aggregation engine needs robust methods for identifying and resolving conflicts or, at minimum, highlighting discrepancies to the user.
- Bias Amplification/Mitigation: While aggregation can potentially dilute the bias of a single model, it could also inadvertently combine or amplify biases if not carefully managed. Diverse model selection and bias detection mechanisms are important.
- API Variability & Maintenance: LLM providers frequently update their models and APIs. The integration layer must be adaptable and regularly maintained to ensure continued compatibility. Models also have different input requirements and output formats that need normalization.
- Security & Data Privacy: Handling user prompts (which may contain sensitive information) and managing multiple sets of API keys requires stringent security practices. Compliance with data privacy regulations (like GDPR) is paramount.
Potential Advanced Features
Beyond the core functionality, several advanced features can significantly enhance the app's value:
- Retrieval-Augmented Generation (RAG) Integration: Connecting the aggregator to private databases or external knowledge sources allows LLMs to generate responses grounded in specific, up-to-date, or proprietary information before aggregation.
- Parameter-Efficient Fine-Tuning (PEFT): Offering capabilities to lightly fine-tune selected models on domain-specific data to improve performance on specialized tasks.
- Explainability Features: Providing users with insights into *how* the final synthesized response was generated, showing the contribution or influence of each individual model.
- User Feedback Loop: Incorporating mechanisms for users to rate the quality of responses, allowing the system to adaptively learn and potentially adjust model weightings or aggregation strategies over time.
- Multimodal Support: Extending the aggregator to handle not just text, but also inputs and outputs involving images, audio, or video, by integrating multimodal foundation models.
- Agentic Capabilities: Enabling the system to perform multi-step tasks, potentially using different LLMs for different sub-tasks within a larger workflow.
Building Effective LLM Applications
Developing robust applications that leverage Large Language Models goes beyond simple API calls. It involves careful consideration of prompt engineering, context management, output parsing, and handling the inherent probabilistic nature of these models. Understanding how to integrate them into reliable workflows is key.
The following video discusses some secrets to building LLM applications that actually work in real-world scenarios, touching upon challenges and strategies relevant to creating effective AI-powered tools, including aggregators.
Frequently Asked Questions (FAQ)
Recommended Further Exploration
- How do different LLM response aggregation techniques compare in practice?
- What are the best strategies for minimizing costs when using multiple LLM APIs?
- How can Retrieval Augmented Generation (RAG) be effectively integrated into an LLM aggregator architecture?
- What are some successful real-world examples and use cases for LLM aggregation platforms?
References
 aws.amazon.com
aws.amazon.com
 docs.aws.amazon.com
aws.amazon.com
docs.aws.amazon.com
aws.amazon.com
Last updated May 4, 2025