
Unlocking Local AI: A Deep Dive into LM Studio Configuration for LLMs
Seamlessly running and managing Large Language Models on your personal computer.
Key Highlights of LM Studio for Local LLMs
- Effortless Local Deployment: LM Studio simplifies the process of downloading, configuring, and running various open-source Large Language Models (LLMs) directly on your personal computer, offering a user-friendly graphical interface across Windows, macOS, and Linux.
- Privacy and Control: By operating LLMs locally and often offline, LM Studio ensures enhanced data privacy and security, as your sensitive information remains on your machine without being sent to third-party cloud services.
- Developer-Friendly API: LM Studio includes a local inference server that mimics the OpenAI API, allowing developers to easily integrate local LLMs into their applications, scripts, and development workflows.
In the rapidly evolving landscape of artificial intelligence, Large Language Models (LLMs) have emerged as incredibly powerful tools capable of understanding, generating, and processing human-like text. While cloud-based services offer convenient access to these models, there's a growing demand for local, hands-on experimentation. This is where LM Studio shines, providing a comprehensive and user-friendly desktop application that brings the power of LLMs directly to your computer. It offers a unique blend of accessibility and control for AI enthusiasts, researchers, and developers alike.
LM Studio stands out as a robust solution for those looking to explore the capabilities of LLMs without the constraints of cloud-based services. This guide will delve deep into LM Studio's functionalities, focusing on its configuration for running local LLMs, and providing practical insights into optimizing your local AI environment.
Understanding LM Studio: Your Gateway to Local LLMs
What is LM Studio and Why is it Important?
LM Studio is a cross-platform desktop application designed to streamline the process of discovering, downloading, and running various LLMs on your local machine. It acts as a bridge, making it easier for users to leverage open-source libraries like llama.cpp and Apple's MLX framework without needing to compile or integrate them manually. This simplifies what can often be a complex setup, democratizing access to cutting-edge AI for individuals and developers.
The primary appeal of running LLMs locally through LM Studio includes:
- Enhanced Data Privacy: Your data remains on your machine, eliminating concerns about sensitive information being transmitted to external servers.
- Reduced Costs: Eliminates the need for expensive cloud computing resources, especially for experimentation and development.
- Offline Accessibility: Once models are downloaded, they can be run without an internet connection, providing flexibility for various environments.
- Customization and Experimentation: Offers greater control over model parameters, allowing for fine-tuning and in-depth experimentation.
- User-Friendly Interface: Provides a ChatGPT-like chat interface for easy interaction and a graphical user interface (GUI) for managing models and settings.
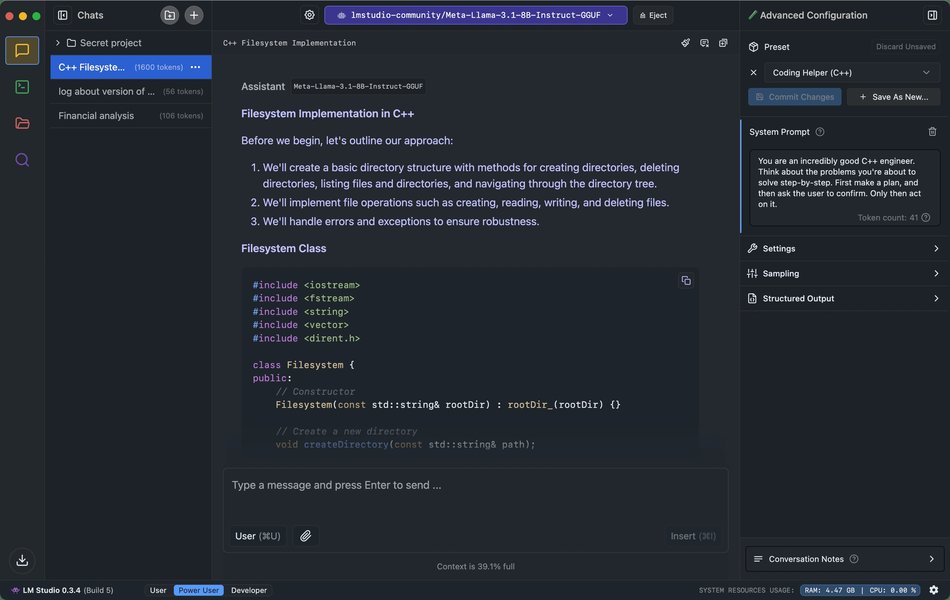
LM Studio provides an intuitive interface for interacting with local LLMs, similar to popular cloud-based chat applications.
Getting Started: Installation and Initial Setup
System Requirements and Installation Steps
Before diving into configuration, ensure your system meets the necessary requirements. LM Studio supports Windows (x86 or ARM), macOS (M1/M2/M3/M4 Macs), and Linux PCs (x86) with a processor that supports AVX2. A minimum of 16GB RAM is recommended, with 6GB+ of VRAM recommended for PCs to leverage GPU acceleration effectively.
The installation process is straightforward:
- Download LM Studio: Visit the official LM Studio website (lmstudio.ai) and download the appropriate installer for your operating system. For Linux, an AppImage file is typically provided, which needs to be made executable.
- Install the Application: Run the downloaded installer. On Linux, after making the AppImage executable (
chmod u+x LM_Studio-*.AppImage), you can run it directly (./LM_Studio-*.AppImage). - Launch LM Studio: Once installed, open the application.
Discovering and Downloading Your First LLM
Upon launching, LM Studio's intuitive interface guides you to the "Discover" tab, where you can browse and search for various open-source LLMs from the Hugging Face repository. Models compatible with the GGUF (llama.cpp) format and MLX format (for Mac) are supported. Popular choices include Llama 3.1, Phi-3, Gemma 2, Mistral, and DeepSeek.
When selecting a model:
- Check Model Sizes: LLMs can be very large (several gigabytes), so ensure you have sufficient storage space.
- Consider Quantization: For better performance on consumer hardware, consider downloading quantized versions (e.g., 4-bit or 5-bit quantization), which offer a good balance of speed and quality while reducing memory footprint.
- Compatibility Check: LM Studio can report on compatible models based on your machine's specifications, preventing downloads that might not work efficiently.
After selecting your desired model, simply click the "Download" button. Once downloaded, navigate to the "AI Chat" or "Local LLM Server" section to load and interact with the model.
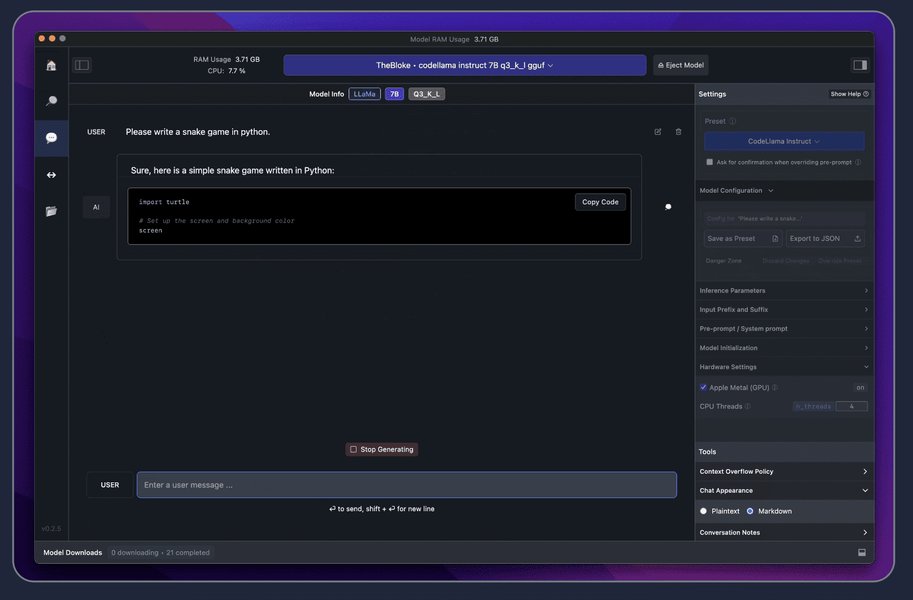
The "Discover" section in LM Studio allows users to easily find and download open-source LLMs.
Optimizing LM Studio Configuration for Performance
Leveraging GPU Acceleration and Model Parameters
Running LLMs locally can be resource-intensive, but LM Studio offers several configuration options to optimize performance:
- GPU Offload: Enabling GPU acceleration significantly speeds up response times by offloading parts of the model computation to your graphics card. This can be adjusted in the settings when loading a model. For Apple Silicon Macs, LM Studio leverages MLX for efficient GPU and unified memory utilization.
- Batch Size and Context Length: These parameters can be adjusted to balance performance and memory usage. A larger batch size might increase throughput but requires more VRAM. Context length determines how much text the model can consider for its responses.
- Quantized Models: As mentioned, using quantized models (e.g., Q4_K_M or Q5_K_M) reduces the model's size and memory footprint, making them faster and more manageable on consumer-grade hardware.
- Automatic Prompt Formatting: LM Studio simplifies prompt construction by automatically formatting inputs to match the model's expected format, reducing the need for manual prompt engineering.
Comparative Performance Metrics for Local LLM Tools
While LM Studio excels in user-friendliness and comprehensive features, understanding its performance relative to other local LLM tools can be insightful. The exact performance depends heavily on the specific model, hardware, and configuration.
| Feature/Tool | LM Studio | Ollama | GPT4All | Jan |
|---|---|---|---|---|
| Ease of Installation | Very Easy (GUI installer) | Easy (CLI focus) | Easy (GUI installer) | Easy (GUI installer) |
| Supported OS | Windows, macOS, Linux | Windows, macOS, Linux | Windows, macOS, Linux | Windows, macOS, Linux |
| Model Format Support | GGUF, MLX (Mac) | Custom Ollama format (built on GGUF) | GGML, GGUF | GGML, GGUF |
| Local Server (OpenAI API Compatible) | Yes | Yes | Yes | Yes |
| GPU Offloading | Excellent (configurable) | Good (configurable) | Good (configurable) | Good (configurable) |
| Multi-Model Session | Yes (via API server) | Yes (run multiple instances) | No | No |
| Privacy Features | High (local data) | High (local data) | High (local data) | High (local data) |
| User Interface | Excellent (GUI Chat, Model Browser) | CLI-centric, web UIs available | Good (GUI Chat) | Good (GUI Chat) |
This table highlights LM Studio's strong position regarding ease of use and its feature-rich environment for managing local LLMs, particularly its support for multi-model sessions via its API server, a unique advantage over some alternatives.
Advanced Features and Developer Integration
The Local Inference Server and API Compatibility
One of LM Studio's most powerful features for developers is its built-in Local LLM Server. This server can be activated with a single click from the "Local LLM Server" tab and exposes an API endpoint on localhost:PORT (defaulting to 1234) that mimics the OpenAI API format. This means any code or application designed to interact with OpenAI's API can be easily reconfigured to communicate with your local LLM running in LM Studio.
Supported API endpoints include:
GET /v1/modelsPOST /v1/chat/completionsPOST /v1/embeddings(new in LM Studio 0.2.19)POST /v1/completions
This compatibility greatly simplifies the integration of local LLMs into various projects, such as RAG (Retrieval Augmented Generation) systems, custom chat interfaces, or even agentic workflows using developer SDKs for Python and TypeScript provided by LM Studio.
Example Python Integration with LM Studio's Local Server
Developers can use familiar libraries like OpenAI's Python library and point the base_url to their local LM Studio server.
import openai
import os
# Set the base URL to your LM Studio local server
# The default port is 1234, but you might configure a different one
os.environ['OPENAI_API_BASE'] = "http://localhost:1234/v1"
os.environ['OPENAI_API_KEY'] = "lm-studio" # API key is not strictly required but can be set to anything
client = openai.OpenAI(
base_url=os.environ.get("OPENAI_API_BASE"),
api_key=os.environ.get("OPENAI_API_KEY")
)
try:
response = client.chat.completions.create(
model="local-model", # The model name can be arbitrary when using a local server
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement in simple terms."}
],
temperature=0.7,
max_tokens=150
)
print(response.choices[0].message.content)
except openai.APIConnectionError as e:
print(f"Could not connect to LM Studio server: {e}")
print("Please ensure LM Studio is running and the local server is started.")
except Exception as e:
print(f"An error occurred: {e}")
This code snippet demonstrates how to send a chat completion request to an LLM running locally via LM Studio's server. This setup is invaluable for building and testing AI applications offline, ensuring privacy, and reducing operational costs.
Headless Mode and Service Deployment
For advanced users and developers, LM Studio offers the ability to run as a service in "headless" mode, meaning without the graphical user interface. This is particularly useful for deploying LM Studio on servers or for automated workflows where continuous uptime of the LLM server is required. Features include:
- Running LM Studio without the GUI.
- Starting the LM Studio LLM server automatically on machine login.
- On-demand model loading.
This capability makes LM Studio a versatile tool for both interactive experimentation and robust backend deployments.
Benefits and Challenges of Local LLMs with LM Studio
The Advantages of Running LLMs Locally
The shift towards local LLM deployment, facilitated by tools like LM Studio, offers significant benefits:
- Privacy and Security: Data processing occurs entirely on your device, ensuring sensitive information never leaves your local environment. This is crucial for applications dealing with confidential data.
- Cost Savings: Avoids recurring API usage fees associated with cloud-based LLMs.
- Offline Capability: Models can be run without an internet connection, ideal for remote work or environments with limited connectivity.
- Full Control: Users have complete control over the model, its parameters, and the local environment, enabling deeper customization and experimentation.
- Reduced Latency: Interactions can be faster as there's no network latency to a remote server.
Navigating Potential Challenges
Despite the many advantages, running LLMs locally, especially larger models, comes with its own set of challenges:
- Hardware Requirements: LLMs are computationally intensive. Sufficient RAM and a powerful GPU (with ample VRAM) are often necessary for acceptable performance, especially for larger models. Older or less powerful machines might struggle.
- Storage Space: Model files can be several gigabytes in size, requiring significant disk space.
- Performance Limitations: While impressive for local setups, performance might not always match the scalability and speed of highly optimized cloud-based solutions, especially for real-time, high-throughput applications.
- Setup Complexity (though mitigated by LM Studio): While LM Studio simplifies the process, initial setup and troubleshooting (e.g., firewall settings, port conflicts) can still pose challenges for users with limited technical expertise.
LM Studio is optimized to leverage GPU acceleration, particularly with NVIDIA RTX GPUs, for improved performance.
Comparative Features of LLM Platforms
A Radar Chart Analysis
To provide a deeper insight into LM Studio's capabilities relative to other platforms for running local LLMs, the following radar chart illustrates key feature strengths. This chart is based on an opinionated analysis of user experience, developer support, performance, and flexibility.
The radar chart visually represents LM Studio's strong standing in user-friendliness and comprehensive model management. While tools like llama.cpp might offer slightly more granular control for advanced users, LM Studio bridges the gap between raw power and accessibility. Ollama, another popular choice, also provides excellent ease of use and API support, often favored for its CLI-centric approach.
Practical Applications and Use Cases
Beyond Chat: Building with Local LLMs
LM Studio isn't just for casual chatting with LLMs; its robust features enable a variety of practical applications:
- Local Development Environments: Create a self-contained AI development environment for prototyping and testing without external API dependencies.
- RAG Systems: Integrate local LLMs with private data sources to build custom Retrieval Augmented Generation (RAG) applications, ensuring data privacy. Tools like AnythingLLM can connect to LM Studio for local RAG.
- Custom Agent Development: Build and test AI agents that interact with local LLMs, ensuring secure and private execution of tasks.
- Content Generation: Generate text, code, or creative content offline, beneficial for writers, programmers, and artists.
- Educational Purposes: Learn about LLMs, experiment with different models, and understand their behaviors in a controlled, local environment.
Video Tutorial: Running LLMs Locally with LM Studio
To provide a more hands-on understanding of LM Studio's capabilities, here is a relevant video tutorial that walks you through the process of setting up and running LLMs locally. This video highlights the straightforward nature of LM Studio, making it accessible even for those new to local AI deployments. It covers the initial download, model selection, and the basics of interaction, showcasing how quickly one can get an LLM up and running on their machine.
A comprehensive guide to running Large Language Models locally using the user-friendly LM Studio.
Frequently Asked Questions (FAQ) about LM Studio and Local LLMs
Conclusion: Empowering Local AI Experimentation
LM Studio has revolutionized the accessibility of Large Language Models, making it feasible for individuals and developers to run powerful AI on their local machines. By simplifying the complex process of model download, configuration, and execution, it empowers users to explore the vast potential of LLMs with enhanced privacy, reduced costs, and greater control. Its user-friendly interface, coupled with an OpenAI-compatible local inference server, positions LM Studio as an invaluable tool for anyone looking to delve into the world of local AI, whether for casual interaction, advanced development, or secure data processing. The ability to harness these models offline opens up new frontiers for innovation, driving the democratization of artificial intelligence.
Recommended Further Exploration
- How to optimize GPU settings for local LLMs?
- What are the best practices for integrating LM Studio with RAG systems?
- A detailed comparison of local LLM frameworks like Ollama and LM Studio.
- How to develop AI agents using local LLMs and LM Studio's API?
References
Last updated May 21, 2025