
Unveiling Efficiency in LLM Fine-Tuning: A Deep Dive into LoRA and Adapters
Exploring Parameter-Efficient Fine-Tuning Techniques for Large Language Models
The landscape of Large Language Models (LLMs) is rapidly evolving, with pre-trained models demonstrating remarkable capabilities across a wide array of tasks. However, adapting these massive models to specific downstream applications or domain-specific data often necessitates fine-tuning. Traditional fine-tuning, which involves updating all of the model's parameters, can be computationally intensive and require significant hardware resources. This has led to the development of Parameter-Efficient Fine-Tuning (PEFT) methods, among which LoRA (Low-Rank Adaptation) and Adapters stand out as prominent and effective techniques. These methods aim to achieve performance comparable to full fine-tuning while significantly reducing the number of trainable parameters, thus lowering computational and storage costs.
Key Highlights of LoRA and Adapters
- Parameter Efficiency: Both LoRA and Adapters drastically reduce the number of parameters that need to be trained during fine-tuning compared to updating the entire pre-trained model. This translates to faster training times and lower memory requirements.
- Modularity and Flexibility: These techniques allow for the creation of task-specific modules (LoRA adapters or Adapter layers) that can be easily swapped or combined, enabling efficient adaptation to multiple downstream tasks without modifying the original large model weights.
- Performance: In many cases, models fine-tuned with LoRA or Adapters achieve performance comparable to, or even exceeding, that of models fine-tuned using traditional full-parameter methods, especially on specific tasks and datasets.
Understanding the Need for Parameter-Efficient Fine-Tuning
Large Language Models possess billions or even trillions of parameters. Fine-tuning such models on new tasks by updating all these parameters presents several challenges:
Computational Demands
Training all parameters requires substantial computational power, including high-end GPUs and significant energy consumption. This can be a barrier for individuals and organizations with limited resources.
Memory Requirements
Storing multiple fine-tuned versions of a large LLM, each for a different task, demands considerable storage space. This can become impractical as the number of downstream applications grows.
Risk of Catastrophic Forgetting
When fine-tuning on a new dataset, there's a risk that the model might "forget" some of the general knowledge it acquired during pre-training. PEFT methods help mitigate this by preserving the original weights.
Delving into Adapters
Adapter-based fine-tuning involves inserting small, trainable neural network modules (adapters) into specific layers of the pre-trained LLM architecture, typically within the Transformer blocks. The original weights of the pre-trained model remain frozen, and only the parameters within the newly added adapter layers are updated during fine-tuning.
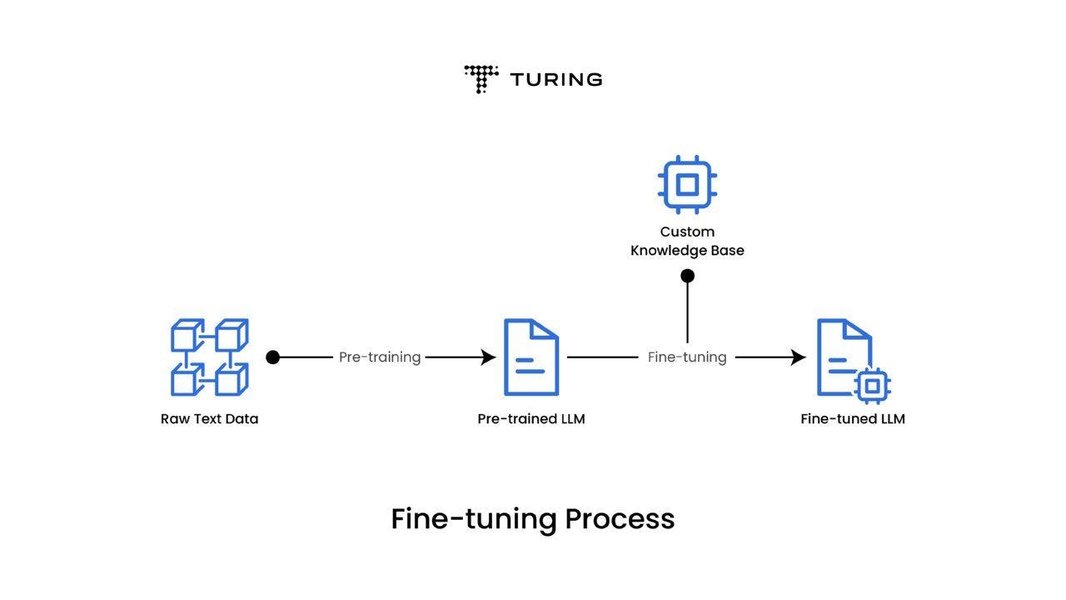
The diagram illustrates the general process of fine-tuning an LLM.
How Adapter Layers Work
Adapter layers are typically designed as bottleneck structures, meaning they project the input to a lower-dimensional space before projecting it back to the original dimension. This bottleneck design helps keep the number of added parameters small. These layers are inserted, for example, after the self-attention and feed-forward network layers in each Transformer block.
When fine-tuning for a specific task, the data is passed through the pre-trained model layers. The adapter layers then learn to adjust the activations based on the task-specific data, effectively guiding the model's behavior towards the new task. Since only the adapter parameters are updated, the vast majority of the original model's knowledge is preserved.
Benefits of Using Adapters
- Computational Efficiency: Adapters add a minimal number of parameters, leading to significantly faster training and lower computational costs compared to full fine-tuning.
- Modularity: Different tasks can have their own set of adapter layers, allowing for easy switching between tasks without loading a completely new model.
- Preservation of Pre-Trained Knowledge: By keeping the original model weights frozen, adapters help prevent catastrophic forgetting.
- Flexibility: Adapters can be inserted at various points in the model architecture, allowing for exploration of different adaptation strategies.
Frameworks and Implementations
Frameworks like LLM-Adapters and Hugging Face's PEFT library provide easy-to-use implementations for integrating various types of adapters into LLMs and applying adapter-based PEFT methods for different tasks.
# Example conceptual code snippet (using a hypothetical PEFT library)
from peft import get_peft_model, AdapterConfig
# Load a pre-trained model
model = ...
# Define adapter configuration
adapter_config = AdapterConfig(
adapter_type="seq_bn", # Example adapter type
task_type="SEQ_CLS", # Example task type
# other configuration parameters
)
# Get the PEFT model with adapters
peft_model = get_peft_model(model, adapter_config)
# Print trainable parameters
peft_model.print_trainable_parameters()
# Fine-tune the model
# peft_model.train(...)
Exploring LoRA (Low-Rank Adaptation)
LoRA is another highly effective PEFT technique that focuses on fine-tuning LLMs by injecting trainable low-rank decomposition matrices into specific layers, primarily the attention layers, of the pre-trained model. Similar to adapters, LoRA freezes the original pre-trained model weights and only trains these newly introduced low-rank matrices.
How LoRA Works
The core idea behind LoRA stems from the observation that the change in weights during fine-tuning often has a low intrinsic rank. Instead of directly learning the full matrix of weight updates \(\Delta W\), LoRA approximates this update by decomposing it into two smaller matrices, \(A\) and \(B\), such that \(\Delta W = BA\). Here, \(B\) is a \(d \times r\) matrix and \(A\) is an \(r \times k\) matrix, where \(r\) is the rank (a small number) and \(d \times k\) is the dimension of the original weight matrix \(W\). The number of parameters to train is drastically reduced from \(d \times k\) to \(d \times r + r \times k\).
\[ \Delta W \approx BA \]During fine-tuning, the input is passed through the original frozen weight matrix \(W\), and simultaneously through the low-rank matrices \(A\) and \(B\). The outputs are then added together: \(Wx + BAx\). Only the parameters in matrices \(A\) and \(B\) are trained.
Visual representation of the LoRA matrix decomposition where a weight matrix is approximated by two smaller matrices.
Benefits of Using LoRA
-
Significant Parameter Reduction: LoRA dramatically reduces the number of trainable parameters, leading to faster training and lower memory usage.
-
Faster Fine-Tuning: With fewer parameters to update, the fine-tuning process is significantly accelerated.
-
Reduced Storage: Storing only the small low-rank matrices for each task is much more efficient than storing full fine-tuned models.
-
No Inference Latency (after merging): Once trained, the low-rank matrices can be merged back into the original weight matrix (\(W_{finetuned} = W + BA\)) for inference, adding no additional latency.
-
Compatibility: LoRA is compatible with many other PEFT methods and can be applied to various model architectures, including diffusion models.
Variations of LoRA
Several variations of LoRA have been proposed to further enhance efficiency and performance, such as QLoRA, which quantizes the pre-trained model weights to 4-bit for even greater memory savings, and AdaLoRA, which adaptively allocates parameter budgets based on the importance of weight matrices.
LoRA vs. Adapters: A Comparative Look
While both LoRA and Adapters fall under the umbrella of PEFT techniques and share the goal of efficient fine-tuning, they differ in their approach and characteristics. The choice between the two often depends on the specific task, model architecture, and available resources.
| Feature | Adapters | LoRA |
|---|---|---|
| Approach | Inserts small, trainable neural network modules into existing layers. | Injects trainable low-rank decomposition matrices into existing weight matrices. |
| Placement | Typically inserted after attention and feed-forward layers. | Primarily applied to weight matrices in attention layers (e.g., query, key, value, output projections). |
| Trainable Parameters | Adds a small number of new parameters in the form of adapter layers. | Adds a small number of new parameters in the form of low-rank matrices (A and B). |
| Inference Latency | May introduce slight inference latency depending on the implementation. | No additional inference latency after merging the low-rank matrices into the base model. |
| Modularity | Highly modular; different adapter modules for different tasks can be easily swapped. | Modular in the sense that different sets of low-rank matrices are trained for each task. |
| Integration | Requires modifying the model architecture to insert adapter layers. | Modifies the forward pass computation but can often be implemented without significant architectural changes. |
| Theoretical Basis | Based on adding small trainable modules. | Based on the low-rank nature of weight updates during fine-tuning. |
Performance and Use Cases
Both methods have demonstrated comparable performance to full fine-tuning on various tasks. LoRA is often favored for its ability to be merged with the base model for inference, eliminating potential latency. Adapters, with their more explicit modular structure, can be particularly useful when managing a large number of tasks with distinct fine-tuned modules.
The effectiveness of each method can also depend on the specific LLM and the downstream task. Research and practical applications continue to explore the optimal configurations and use cases for both LoRA and Adapters.
The Role of PEFT Libraries
Libraries like Hugging Face's PEFT (Parameter-Efficient Fine-Tuning) and frameworks such as LLM-Adapters have been instrumental in making these techniques accessible to the wider community. These libraries provide standardized implementations and tools for applying various PEFT methods, including LoRA and different types of adapters, to a wide range of pre-trained LLMs.
Using these libraries simplifies the process of integrating and experimenting with PEFT techniques, allowing researchers and developers to efficiently fine-tune large models on custom datasets without needing to implement the methods from scratch.
Implementing PEFT with Libraries
PEFT libraries typically allow users to load a pre-trained model, define a PEFT configuration (specifying the method like LoRA or an adapter type and its parameters), get a PEFT-wrapped model, and then proceed with the standard training loop, updating only the trainable PEFT parameters.
# Conceptual steps using a PEFT library
1. Load the base pre-trained LLM.
2. Define the PEFT configuration (e.g., LoRA parameters, adapter type).
3. Wrap the base model with the PEFT configuration to create a PEFT model.
4. Prepare the task-specific dataset.
5. Train the PEFT model on the dataset.
6. Save the trained PEFT adapter/matrices.
7. For inference, load the base model and the trained adapter, or merge the adapter into the base model.
Beyond LoRA and Adapters: The Broader PEFT Landscape
While LoRA and Adapters are prominent PEFT techniques, the field is actively researching and developing other methods. These include Prompt Tuning, Prefix Tuning, and various forms of quantization techniques like QLoRA, which combine LoRA with quantization for further memory efficiency.
Prompt tuning and prefix tuning involve learning a small set of continuous "prompts" or prefixes that are prepended to the input embeddings or hidden states of the model. These learned prompts guide the pre-trained model's behavior without modifying its core parameters. The choice of PEFT method often depends on factors like the task, model size, available resources, and desired trade-offs between performance and efficiency.
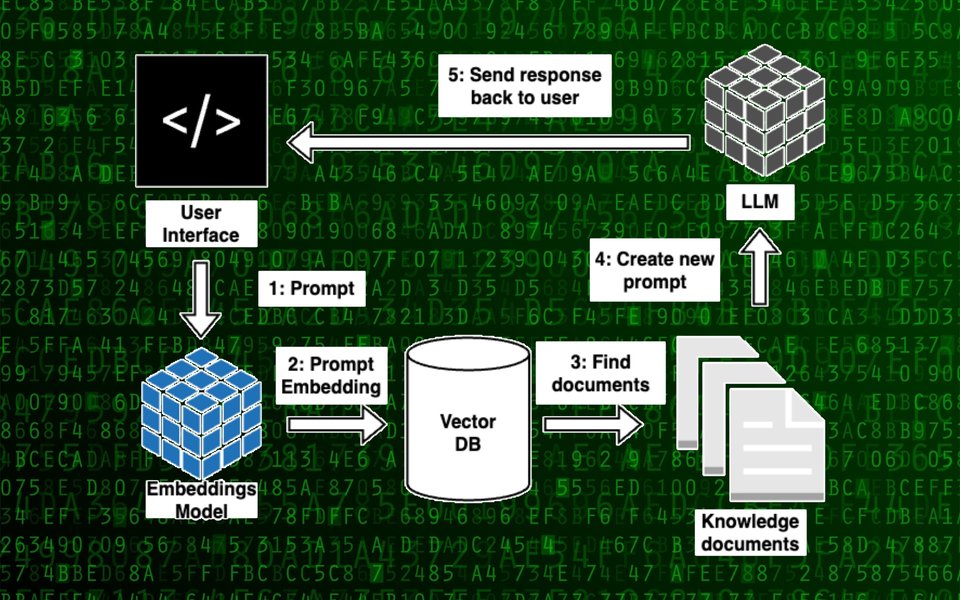
A visual representation of a workflow that might involve fine-tuned LLMs for specific tasks.
The continuous innovation in PEFT methods is making it increasingly feasible to leverage the power of large language models for a wide range of specialized applications, even with limited computational resources.
Frequently Asked Questions
What is the main difference between LoRA and Adapters?
The main difference lies in where and how the new trainable parameters are introduced. Adapters insert small, dedicated neural network layers within the existing model architecture, while LoRA injects low-rank decomposition matrices into the weight matrices of existing layers, primarily attention layers.
Which method is generally better, LoRA or Adapters?
There is no single "better" method; the optimal choice depends on the specific use case. LoRA is often preferred when inference latency is a critical concern due to its ability to be merged with the base model. Adapters offer explicit modularity, which can be advantageous for managing numerous task-specific adaptations. Both have shown comparable performance to full fine-tuning in many scenarios.
Can LoRA and Adapters be used together?
Yes, some research explores combining different PEFT techniques, although the specific combinations and their effectiveness can vary.
Do LoRA and Adapters achieve the same performance as full fine-tuning?
In many cases, LoRA and Adapters can achieve performance comparable to or very close to full fine-tuning, especially on specific downstream tasks. They excel at adapting the pre-trained model's existing knowledge to a new domain or task with high efficiency.
References
Last updated April 21, 2025