
Desmitificando el Aprendizaje Automático: Datos, Modelos y Monitoreo
Una guía completa sobre preparación de datos, entrenamiento de modelos, validación cruzada y la importancia del monitoreo continuo.
Aspectos Destacados
- La calidad de los datos es primordial: Un proceso riguroso de limpieza y preparación es la base para construir modelos de aprendizaje automático precisos y confiables.
- Entrenamiento a medida vs. eficiencia preentrenada: Elegir entre entrenar un modelo desde cero o usar uno preentrenado implica un balance entre personalización, tiempo, recursos y rendimiento esperado.
- Monitoreo constante para un rendimiento óptimo: La vigilancia continua de los modelos en producción es esencial para detectar desviaciones y asegurar su eficacia a lo largo del tiempo.
La Clave del Éxito: Preparación y Limpieza de Datos
¿Por Qué Son Cruciales Estos Pasos?
La preparación y limpieza de datos son etapas críticas y a menudo las más laboriosas en el ciclo de vida del aprendizaje automático (Machine Learning, ML). La calidad de los datos de entrada impacta directamente en el rendimiento, la precisión y la fiabilidad del modelo final. Datos de baja calidad, con errores, inconsistencias o sesgos, pueden llevar a modelos que toman decisiones incorrectas, generalizan mal a nuevos datos o perpetúan sesgos existentes. Un proceso meticuloso de limpieza asegura que el modelo aprenda patrones reales y no ruido, sentando las bases para predicciones confiables y decisiones informadas.
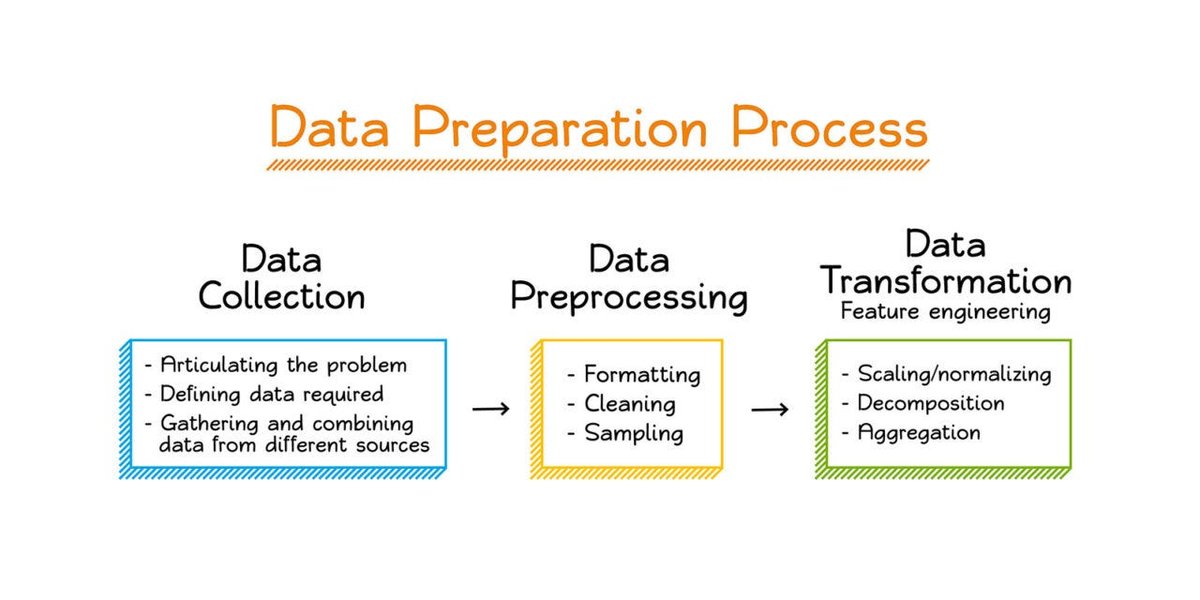
Visualización del flujo de preprocesamiento de datos en machine learning.
Pasos Esenciales en el Proceso
El proceso de limpieza y preparación de datos es iterativo y requiere un entendimiento profundo del conjunto de datos y del problema a resolver. Los pasos clave incluyen:
1. Inspección y Exploración de Datos
El primer paso es comprender a fondo el conjunto de datos. Esto implica revisar la estructura, los tipos de datos, las estadísticas descriptivas (media, mediana, desviación estándar) y utilizar visualizaciones (histogramas, diagramas de dispersión) para obtener una visión general e identificar posibles problemas iniciales como valores atípicos evidentes o distribuciones inesperadas.
2. Manejo de Valores Faltantes
Los datos faltantes son comunes y deben tratarse adecuadamente. Las estrategias incluyen:
- Eliminación: Se pueden eliminar las filas (observaciones) o columnas (características) con demasiados valores faltantes, aunque esto puede llevar a pérdida de información.
- Imputación: Rellenar los valores faltantes utilizando técnicas como la media, mediana o moda de la columna, o métodos más sofisticados como la imputación basada en regresión o algoritmos como k-NN. La elección depende del tipo de dato y la cantidad de valores faltantes.
3. Eliminación de Datos Duplicados e Irrelevantes
Las observaciones duplicadas pueden sesgar el análisis y el entrenamiento del modelo, dándole más peso a ciertas instancias. Es crucial identificarlas y eliminarlas. También se deben eliminar datos irrelevantes que no aportan información útil para el problema.
4. Corrección de Errores Estructurales y de Formato
Esto implica corregir errores tipográficos, inconsistencias en categorías (p. ej., "México", "mexico", "MX"), estandarizar formatos de fechas, unidades de medida y asegurar que los tipos de datos sean correctos (numérico, categórico, texto).
5. Identificación y Manejo de Valores Atípicos (Outliers)
Los outliers son valores extremos que difieren significativamente del resto de los datos. Pueden ser errores de medición o representar variaciones genuinas. Se detectan con métodos estadísticos (Z-score, rango intercuartílico) o visualizaciones (box plots). Dependiendo del contexto, pueden eliminarse, ajustarse (capping/flooring) o tratarse con algoritmos robustos a outliers.
6. Transformación y Estandarización de Datos
Muchos algoritmos de ML son sensibles a la escala de las características. Las técnicas comunes incluyen:
- Normalización (Min-Max Scaling): Escala los datos a un rango fijo, generalmente [0, 1].
- Estandarización (Z-score Normalization): Transforma los datos para que tengan una media de 0 y una desviación estándar de 1.
- Otras transformaciones como la logarítmica pueden ser útiles para manejar distribuciones sesgadas.

Ilustración de los diferentes pasos involucrados en el preprocesamiento de datos para machine learning.
7. Selección de Características (Feature Selection)
No todas las características (variables) son igualmente importantes. La selección de características busca identificar y mantener solo las más relevantes para el modelo, eliminando las redundantes o irrelevantes. Esto puede mejorar el rendimiento del modelo, reducir el tiempo de entrenamiento y disminuir el riesgo de sobreajuste.
8. Validación de la Limpieza
Finalmente, es importante validar que los datos limpios son consistentes y están listos para ser utilizados en el entrenamiento del modelo. Se pueden realizar comprobaciones finales y revisiones de calidad.
Visualizando el Proceso de Limpieza
El siguiente diagrama mental ilustra la interconexión de los pasos clave en la preparación y limpieza de datos:
Aprendizaje Práctico: Limpieza de Datos con Python
El siguiente video ofrece un tutorial paso a paso sobre cómo realizar la limpieza de datos utilizando bibliotecas populares de Python como Pandas, aplicado a un conjunto de datos del mundo real. Es una excelente manera de ver estos conceptos en acción:
Este video demuestra técnicas prácticas para abordar problemas comunes de datos, como valores faltantes, formatos inconsistentes y outliers, preparando eficazmente los datos para el análisis y el entrenamiento de modelos de machine learning.
¿Construir o Adaptar? Modelos Desde Cero vs. Preentrenados
Una decisión fundamental en el desarrollo de modelos de ML es si entrenar un modelo completamente desde cero o aprovechar un modelo preentrenado. Ambas estrategias tienen implicaciones significativas en términos de tiempo, recursos computacionales y los resultados que se pueden esperar.
Entrenamiento Desde Cero (From Scratch)
Implica inicializar los parámetros (pesos) del modelo de forma aleatoria y entrenarlo utilizando únicamente el conjunto de datos disponible para la tarea específica.
- Tiempo y Recursos: Requiere una inversión considerable de tiempo y recursos computacionales (CPU/GPU), especialmente para modelos complejos (como redes neuronales profundas) y grandes volúmenes de datos. El proceso de entrenamiento puede llevar días, semanas o incluso meses.
- Datos Necesarios: Generalmente necesita una gran cantidad de datos etiquetados específicos para la tarea para que el modelo aprenda patrones robustos y generalice bien.
- Resultados Esperados: Puede lograr un rendimiento óptimo y una alta personalización si se dispone de suficientes datos de alta calidad y los recursos necesarios. Es ideal cuando la tarea es muy específica y difiere significativamente de las tareas para las que existen modelos preentrenados.
Uso de Modelos Preentrenados (Pre-trained Models)
Consiste en utilizar un modelo que ya ha sido entrenado, generalmente en un conjunto de datos masivo (como ImageNet para imágenes o grandes corpus de texto para NLP), y adaptarlo a la tarea específica. Esto a menudo se hace mediante el "ajuste fino" (fine-tuning), donde se reentrenan algunas capas del modelo con los datos específicos de la nueva tarea.
- Tiempo y Recursos: Ahorra significativamente tiempo y recursos computacionales, ya que el modelo ya ha aprendido características generales útiles de los datos masivos originales. El fine-tuning requiere menos datos y tiempo de entrenamiento.
- Datos Necesarios: Puede funcionar bien incluso con conjuntos de datos más pequeños para la tarea específica, ya que aprovecha el conocimiento previo ("transfer learning").
- Resultados Esperados: A menudo proporciona un rendimiento muy competitivo o incluso superior al entrenamiento desde cero, especialmente cuando los datos específicos son limitados. Es el enfoque preferido para muchas tareas estándar de visión por computadora y procesamiento del lenguaje natural. Sin embargo, si la tarea es muy diferente del dominio original del modelo preentrenado, su rendimiento podría no ser óptimo.
Comparativa: Desde Cero vs. Preentrenado
La siguiente tabla resume las diferencias clave:
| Aspecto | Entrenamiento Desde Cero | Modelo Preentrenado (con Fine-Tuning) |
|---|---|---|
| Tiempo de Desarrollo | Alto | Bajo/Medio |
| Recursos Computacionales | Altos | Bajos/Medios |
| Necesidad de Datos Específicos | Alta | Baja/Media |
| Potencial de Personalización | Muy Alto | Medio/Alto (depende del fine-tuning) |
| Rendimiento con Pocos Datos | Bajo | Alto |
| Velocidad de Puesta en Marcha | Lenta | Rápida |
Visualización Comparativa de Enfoques
Este gráfico radar ilustra las fortalezas y debilidades relativas de entrenar un modelo desde cero frente a utilizar uno preentrenado, basado en criterios clave. Las puntuaciones más altas indican una mayor ventaja en ese aspecto.
Como se observa, los modelos preentrenados generalmente ofrecen ventajas en velocidad, eficiencia de recursos y rendimiento con datos limitados, mientras que entrenar desde cero ofrece mayor potencial de personalización pero a un costo mayor.
Midiendo la Robustez: El Papel de la Validación Cruzada
¿Qué es la Validación Cruzada?
La validación cruzada (Cross-Validation, CV) es una técnica fundamental para evaluar cómo un modelo de aprendizaje automático generalizará a datos nuevos e independientes. En lugar de simplemente dividir los datos una vez en conjuntos de entrenamiento y prueba, la validación cruzada utiliza los datos de manera más eficiente y proporciona una estimación más robusta del rendimiento del modelo.
La técnica más común es la validación cruzada de k-folds (k-fold Cross-Validation):
- El conjunto de datos original se divide aleatoriamente en 'k' subconjuntos (folds) de tamaño aproximadamente igual.
- El modelo se entrena 'k' veces. En cada iteración (i = 1 a k):
- Se utiliza el fold 'i' como conjunto de prueba (validación).
- Se utilizan los 'k-1' folds restantes como conjunto de entrenamiento.
- Se calcula una métrica de rendimiento (p. ej., precisión, error cuadrático medio) para cada iteración utilizando el conjunto de prueba correspondiente.
- La estimación final del rendimiento del modelo es el promedio (y a menudo también la desviación estándar) de las métricas obtenidas en las 'k' iteraciones.
¿Cómo Evalúa la Estabilidad?
La validación cruzada es crucial para evaluar la estabilidad del modelo por varias razones:
- Reduce la dependencia de una única partición: Al entrenar y evaluar el modelo en 'k' combinaciones diferentes de datos de entrenamiento/prueba, se obtiene una visión más completa de su rendimiento. Si el modelo funciona bien consistentemente en todos los folds, indica que es estable y no depende excesivamente de una partición particular de los datos.
- Detecta la sensibilidad a los datos: Si el rendimiento del modelo varía significativamente entre los diferentes folds (alta desviación estándar de las métricas), sugiere que el modelo es inestable y sensible a las pequeñas variaciones en los datos de entrenamiento. Esto podría ser un signo de sobreajuste (overfitting) o de que el modelo no está capturando bien los patrones subyacentes.
- Mejor estimación de la generalización: Al promediar los resultados de múltiples pruebas, la validación cruzada proporciona una estimación menos sesgada y más fiable de cómo se comportará el modelo con datos completamente nuevos, lo cual es esencial para confiar en sus predicciones en un entorno real.
- Ayuda en la selección de modelos e hiperparámetros: Permite comparar diferentes modelos o diferentes configuraciones de hiperparámetros de manera más justa, seleccionando aquel que muestre no solo el mejor rendimiento promedio, sino también una menor variabilidad (mayor estabilidad) a través de los folds.
En resumen, la validación cruzada va más allá de una simple métrica de rendimiento; ofrece información sobre la consistencia y fiabilidad del modelo frente a la variabilidad inherente de los datos.
Selección Inteligente: Criterios para Modelos Preentrenados
Elegir el modelo preentrenado adecuado es clave para el éxito de aplicaciones específicas como la clasificación de imágenes o el procesamiento de texto. No todos los modelos preentrenados son iguales, y una selección cuidadosa puede ahorrar tiempo y mejorar significativamente los resultados.
Factores Clave a Considerar
1. Relevancia de la Tarea y el Dominio
El factor más importante es si el modelo fue preentrenado en una tarea y un dominio de datos similares a los de tu aplicación. Por ejemplo, un modelo preentrenado en ImageNet (imágenes generales) puede ser un buen punto de partida para muchas tareas de visión por computadora, pero si tu tarea es clasificar imágenes médicas muy específicas, un modelo preentrenado en datos médicos (si existe) podría ser más adecuado. Para NLP, considera si el modelo fue entrenado en el idioma y el tipo de texto relevante (p. ej., noticias, redes sociales, documentos legales).
2. Precisión y Métricas de Rendimiento Originales
Investiga el rendimiento del modelo preentrenado en benchmarks estándar para la tarea original (p. ej., precisión Top-1/Top-5 en ImageNet, puntuación F1 en SQuAD para preguntas y respuestas). Un buen rendimiento en la tarea original es un indicador positivo de que ha aprendido características útiles.
3. Arquitectura del Modelo y Complejidad
Considera la arquitectura subyacente (p. ej., ResNet, BERT, GPT). Algunas arquitecturas son más adecuadas para ciertas tareas. Además, evalúa la complejidad (número de parámetros, profundidad). Modelos más grandes pueden ser más potentes pero requieren más recursos computacionales para el fine-tuning y la inferencia.
4. Facilidad de Ajuste Fino (Fine-Tuning)
¿Qué tan fácil es adaptar el modelo a tu conjunto de datos específico? Algunos modelos y frameworks (como TensorFlow Hub, Hugging Face Transformers) facilitan mucho este proceso. Verifica si hay tutoriales o ejemplos disponibles.
5. Recursos Computacionales Requeridos
Evalúa los requisitos de memoria (RAM y VRAM) y potencia de procesamiento (CPU/GPU) tanto para el fine-tuning como para desplegar el modelo en producción. Asegúrate de que se ajusten a tus capacidades.
6. Compatibilidad con el Framework
Verifica que el modelo preentrenado esté disponible y sea compatible con tu framework de ML preferido (p. ej., TensorFlow, PyTorch, scikit-learn).
7. Licencia y Disponibilidad
Comprueba la licencia bajo la cual se distribuye el modelo. Algunas licencias pueden tener restricciones de uso comercial. Asegúrate también de que los pesos del modelo sean fácilmente descargables.
Vigilancia Continua: Monitoreo de Modelos en Producción
Desplegar un modelo de aprendizaje automático no es el final del camino. Los modelos en producción operan en un entorno dinámico donde los datos y las condiciones pueden cambiar, afectando potencialmente su rendimiento y fiabilidad. El monitoreo continuo es esencial.
Ejemplo de un dashboard utilizado para monitorear sistemas y aplicaciones, similar a los usados para modelos de ML.
La Importancia del Monitoreo Constante
- Detección de Degradación del Rendimiento: Los modelos pueden volverse menos precisos con el tiempo debido a fenómenos como el "data drift" (cambios en la distribución estadística de los datos de entrada) o el "concept drift" (cambios en la relación entre las entradas y la salida deseada). El monitoreo detecta estas caídas de rendimiento.
- Aseguramiento de la Fiabilidad: Permite identificar y corregir problemas como predicciones erróneas, sesgos inesperados o fallos técnicos antes de que causen un impacto negativo significativo.
- Mantenimiento de la Relevancia: Asegura que el modelo sigue siendo adecuado para el problema que intenta resolver a medida que el mundo cambia.
- Optimización de Recursos: Ayuda a entender cuándo es necesario invertir recursos en reentrenamiento o ajustes, evitando esfuerzos innecesarios.
Indicadores de Alerta: ¿Cuándo Reentrenar?
Varios indicadores clave pueden señalar que un modelo necesita ajustes, reentrenamiento o incluso ser reemplazado:
- Caída en las Métricas de Rendimiento Clave: Un descenso sostenido en la precisión, recall, F1-score, AUC, error cuadrático medio, o cualquier otra métrica relevante para la tarea.
- Aumento del Error de Predicción: Un incremento en la tasa de errores o en la magnitud de los errores.
- Data Drift Significativo: Detección de cambios estadísticos importantes en las características de los datos de entrada (p. ej., cambios en la media, varianza, distribución) en comparación con los datos de entrenamiento. Herramientas específicas de monitoreo pueden detectar este drift.
- Concept Drift Detectado: Evidencia de que la relación fundamental que el modelo aprendió ha cambiado (p. ej., cambios en el comportamiento del cliente, nuevas categorías emergentes).
- Aumento del Sesgo (Bias): Si el monitoreo revela que el modelo está funcionando peor para ciertos subgrupos demográficos o categorías, indicando un sesgo injusto.
- Latencia o Errores del Sistema: Problemas operativos como aumento del tiempo de inferencia o fallos en el sistema que aloja el modelo.
- Disponibilidad de Nuevos Datos Significativos: La acumulación de una cantidad sustancial de datos nuevos y etiquetados puede justificar un reentrenamiento para mejorar el modelo.
- Cambios en los Requisitos del Negocio: Nuevos objetivos o restricciones pueden requerir un modelo diferente o ajustado.
Establecer umbrales para estos indicadores y sistemas de alerta automatizados es una práctica recomendada para una gestión proactiva de los modelos en producción.
Preguntas Frecuentes (FAQ)
¿Cuál es la diferencia entre limpieza y preprocesamiento de datos?
Aunque los términos a menudo se usan indistintamente, la limpieza de datos se enfoca específicamente en identificar y corregir errores, inconsistencias y valores faltantes en el conjunto de datos. El preprocesamiento de datos es un término más amplio que incluye la limpieza, pero también abarca otras transformaciones necesarias para preparar los datos para el modelo, como la normalización/estandarización, la codificación de variables categóricas y la ingeniería/selección de características. La limpieza es un subconjunto crucial del preprocesamiento.
¿Siempre es mejor usar un modelo preentrenado?
No necesariamente. Los modelos preentrenados son muy eficientes y efectivos para muchas tareas estándar, especialmente cuando los datos específicos son limitados. Sin embargo, si tu tarea es muy novedosa o el dominio de tus datos es muy diferente al de los datos de preentrenamiento, un modelo entrenado desde cero (si tienes suficientes datos y recursos) podría ofrecer un mejor rendimiento y mayor personalización. La elección depende del contexto específico, los recursos disponibles y los objetivos del proyecto.
¿Con qué frecuencia debo reentrenar mi modelo en producción?
No hay una respuesta única. La frecuencia de reentrenamiento depende de varios factores, incluyendo:
- La velocidad con la que cambian los datos (data drift).
- La estabilidad del entorno y del concepto que modela.
- Los resultados del monitoreo continuo (si las métricas caen por debajo de un umbral).
- La disponibilidad de nuevos datos etiquetados.
- El costo y el esfuerzo del reentrenamiento.
Algunos modelos pueden requerir reentrenamiento diario o semanal, mientras que otros pueden funcionar bien durante meses o años. El monitoreo activo es clave para determinar la cadencia óptima.
¿Qué es el sobreajuste (overfitting) y cómo ayuda la validación cruzada?
El sobreajuste ocurre cuando un modelo aprende los datos de entrenamiento demasiado bien, incluyendo el ruido y las particularidades específicas de ese conjunto de datos, en lugar de los patrones generales. Como resultado, el modelo funciona muy bien en los datos de entrenamiento pero mal en datos nuevos (generaliza pobremente). La validación cruzada ayuda a detectar el sobreajuste al evaluar el modelo en múltiples conjuntos de datos de validación (los folds de prueba) que no se usaron directamente para el entrenamiento en esa iteración. Si el rendimiento en los folds de validación es significativamente peor que en los datos de entrenamiento correspondientes, es un fuerte indicio de sobreajuste.
Referencias
- Data Cleaning in Machine Learning - Scaler Blog
- Data Cleaning: Step-by-step Guide - Elite Data Science
- Making the Right Choice: Pre-Trained Models vs Custom Models - Medium
- Pre-Trained Machine Learning Models vs Models Trained from Scratch - Fritz AI
- Cross-validation (statistics) - Wikipedia
- 3.1. Cross-validation: evaluating estimator performance - Scikit-learn
- 5 Data Cleaning Techniques for Better ML Models - DataHeroes AI
Lecturas Recomendadas
 docs.aws.amazon.com
docs.aws.amazon.com
Last updated April 15, 2025