
Mamba模型深度剖析:它如何挑战Transformer的AI霸权?
一探究竟Mamba的革新原理、高效计算、独特架构及其撼动AI格局的潜力。
近年来,一个名为Mamba的新型序列建模架构在人工智能领域引起了广泛关注。它凭借其独特的设计理念和在处理长序列数据时展现出的卓越性能,被许多研究者和开发者视为传统Transformer模型强有力的竞争者。本文将深入探讨Mamba模型的基石原理、计算机制、架构特点,并分析其为何具备挑战Transformer统治地位的潜力。
Mamba模型核心亮点
- 选择性状态空间模型 (Selective SSM): Mamba的核心创新在于引入了选择性机制,允许模型根据输入数据动态地调整其状态空间参数,从而有效地筛选和记忆信息。
- 线性时间复杂度: 与Transformer的二次方复杂度不同,Mamba在处理序列数据时实现了线性或近线性时间复杂度,使其在处理超长序列时具有显著的计算效率优势。
- 高效的并行计算: Mamba的架构设计支持高效的并行化训练和推理,特别是在现代GPU等硬件上,能够充分发挥计算潜力,提升整体速度。
Mamba模型的核心原理:状态空间模型 (SSM) 与选择性机制
Mamba模型的基础构建于状态空间模型 (State Space Model, SSM)之上。SSM是一种经典的数学工具,最初应用于控制理论和时间序列分析,用于描述动态系统的状态如何随时间演变。一个标准的连续时间SSM可以通过以下微分方程组来表示:
\[ h'(t) = A h(t) + B x(t) \] \[ y(t) = C h(t) + D x(t) \]其中:
- \(h(t)\) 是系统的状态向量,在 \(t\) 时刻捕捉了系统的内部“记忆”。
- \(x(t)\) 是在 \(t\) 时刻的输入。
- \(y(t)\) 是在 \(t\) 时刻的输出。
- \(A, B, C, D\) 是决定系统动态行为的参数矩阵。
为了应用于深度学习中的离散序列数据(如文本或音频样本),SSM需要被离散化。这个过程通常引入一个步长参数 \(\Delta\),将连续时间动态转换为离散时间更新规则:
\[ \bar{A} = \exp(\Delta A) \] \[ \bar{B} = (\Delta A)^{-1}(\exp(\Delta A) - I)\Delta B \quad (\text{或者其他离散化方法}) \] \[ h_k = \bar{A} h_{k-1} + \bar{B} x_k \] \[ y_k = C h_k + D x_k \]选择性状态空间模型 (Selective SSM / S6)
Mamba的关键创新在于引入了“选择性”机制,形成了选择性状态空间模型 (Selective State Space Model, S6)。与传统SSM中固定的参数 \(A, B, C, \Delta\) 不同,Mamba让这些参数(尤其是 \(\Delta, B, C\))依赖于当前的输入数据。这意味着模型可以根据输入上下文动态地调整其行为,选择性地关注序列中的重要信息,并过滤掉无关或冗余的部分。这种输入依赖性赋予了Mamba强大的上下文感知能力,使其能够有效地捕捉长距离依赖关系,同时避免了不必要的计算负担。
这种选择性机制类似于循环神经网络 (RNN) 中的门控单元(如LSTM或GRU中的门),但它是在SSM框架内以一种更高效的方式实现的,特别是在并行计算方面。
Mamba、RNN和Transformer架构的可视化对比,突出了它们在序列处理上的不同机制。
Mamba模型的计算方式
Mamba模型的设计允许其通过两种主要模式进行计算,这两种模式各有优势,并分别适用于训练和推理的不同阶段:
1. 线性递归计算 (RNN模式)
在这种模式下,Mamba的行为类似于传统的循环神经网络。它按顺序逐个处理序列中的元素(token),在每个时间步更新其内部状态 \(h_k\) 并产生输出 \(y_k\)。
\[ h_k = \text{selective_update}(\bar{A}_k, \bar{B}_k, h_{k-1}, x_k) \] \[ y_k = C_k h_k \]由于参数 \(\bar{A}_k, \bar{B}_k, C_k\) 是输入 \(x_k\) 的函数,这使得状态更新具有选择性。这种递归方式非常适合在线推理或处理单个序列样本,因为它具有较低的内存占用(仅需存储当前状态)。然而,对于训练大规模模型而言,其固有的顺序性限制了并行计算的效率。
2. 全局卷积计算 (CNN模式)
为了克服递归模式在训练时的并行化瓶颈,Mamba巧妙地利用了SSM的线性时不变(LTI)特性(在参数固定时)。当SSM参数不依赖于时间步时,其递归计算可以等效地表示为一个大型的全局卷积操作。Mamba通过特定的数学变换和硬件友好的并行扫描算法(如scan-then-convolve),即使在参数是输入依赖的情况下,也能有效地将其计算转换为一种并行化的卷积形式。
具体来说,输出序列 \(y\) 可以被看作是输入序列 \(x\) 与一个动态生成的卷积核的卷积。这种卷积模式允许在训练期间对整个序列进行并行处理,极大地提高了计算效率,充分利用了现代GPU的并行计算能力。通常,在训练阶段会采用卷积模式,而在推理阶段,如果需要逐个生成token(例如在自回归语言模型中),则会切换回递归模式。
这种双模式计算能力是Mamba高效性的关键之一,使其能够在保持强大序列建模能力的同时,实现快速的训练和推理。
Mamba模型的架构设计
Mamba模型的整体架构是通过堆叠多个相同的**Mamba块 (Mamba Block)** 构建而成的。这种设计思想类似于Transformer模型堆叠多个Transformer层的做法,旨在通过增加网络深度来提升模型的表达能力。
Mamba块的内部结构
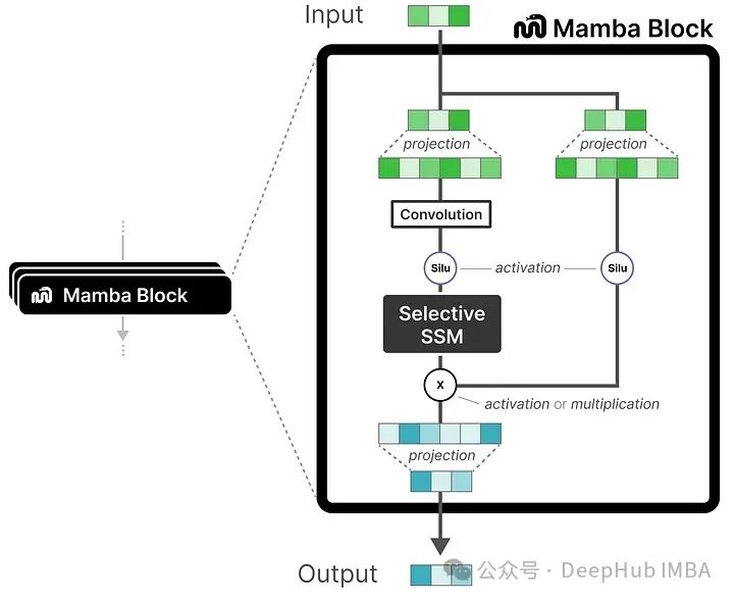
每个Mamba块通常包含以下几个关键组件:
- 输入线性投影 (Input Linear Projection): 输入数据首先会经过一个线性层进行维度变换,以适应后续SSM模块的处理需求。
- 选择性状态空间模块 (Selective SSM / S6): 这是Mamba块的核心,负责实现选择性的状态更新和信息传播。如前所述,该模块的参数(如 \(\Delta, B, C\))是根据当前输入动态生成的。
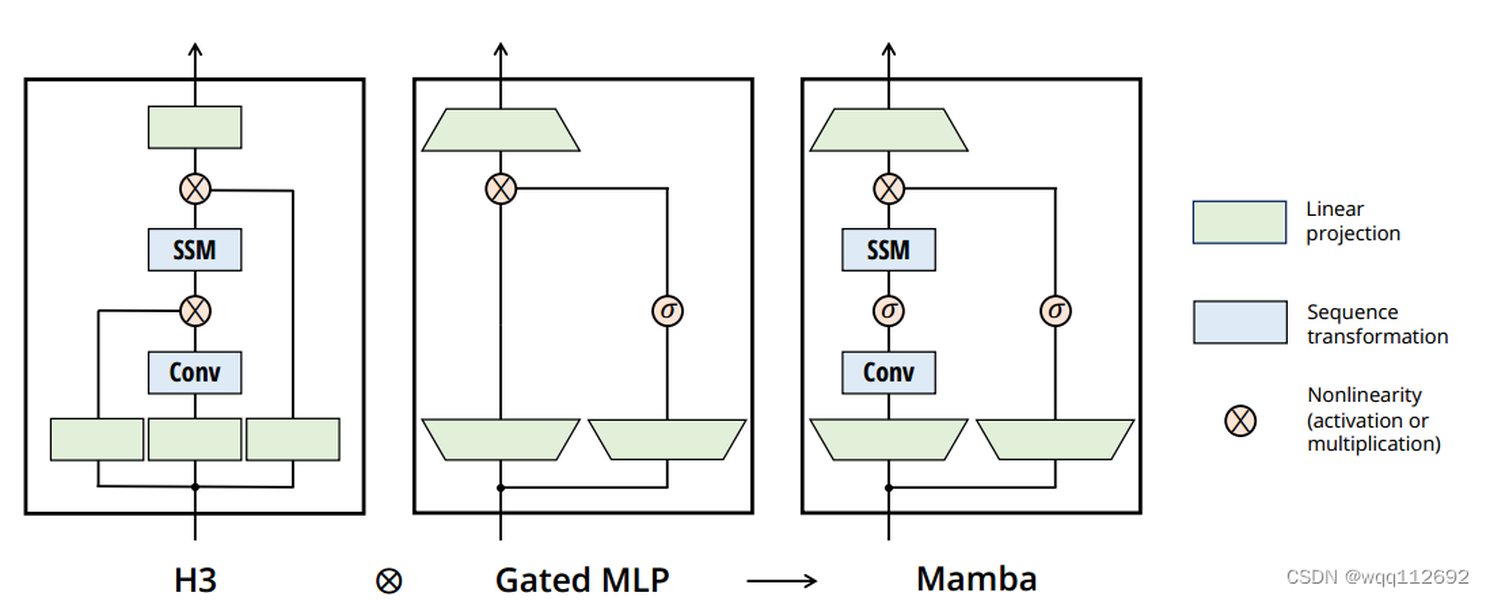
- 门控机制 (Gating Mechanism): 类似于门控MLP (Gated MLP) 或H3 (Hungry Hungry Hippos) 块中的设计,Mamba块内部也可能集成门控机制。这些门控单元(通常是Sigmoid或SiLU激活函数)可以进一步调制信息流,增强模型的非线性表达能力和选择性。
- 输出线性投影 (Output Linear Projection): SSM模块的输出会再经过一个线性层,将其转换回适合下一层或最终输出的维度。
- 残差连接 (Residual Connection) 和归一化 (Normalization): 与现代深度学习架构一样,Mamba块通常也会采用残差连接和层归一化(Layer Normalization)等技术,以帮助梯度传播,加速模型收敛,并提高训练稳定性。
Mamba通过简化设计,重复使用Mamba块,而不是像某些混合模型那样交替使用不同类型的模块,从而实现了一种高效且一致的架构。
Mamba模型块的基本结构,展示了选择性SSM和门控机制的结合。
通过堆叠这些Mamba块,模型能够学习到数据中越来越复杂的层次化特征和长距离依赖关系。整个Mamba模型的输入和输出端通常也会有嵌入层(Embedding Layer)用于将离散的token转换为连续向量,以及一个最终的输出层(如Softmax层用于分类或语言建模)。
Mamba与Transformer:AI霸权之争
Transformer自2017年问世以来,凭借其强大的自注意力机制 (Self-Attention) 在自然语言处理乃至更广泛的AI领域取得了统治性地位。然而,其核心的自注意力机制也带来了固有的挑战,尤其是在处理长序列时。Mamba的出现,正是针对这些痛点提供了有力的解决方案。
计算效率的巨大飞跃
线性时间复杂度 vs. 二次方复杂度
Transformer的自注意力机制需要计算序列中每对token之间的注意力得分,这导致其计算复杂度和内存消耗与序列长度 \(N\) 的平方 (\(O(N^2)\)) 成正比。当序列长度增加时,计算量会急剧膨胀,使得Transformer在处理非常长的文档、高分辨率图像或长时间音频时变得非常昂贵甚至不可行。
相比之下,Mamba通过其选择性SSM和高效的并行计算算法,实现了对序列长度的线性 (\(O(N)\)) 或近线性 (\(O(N \log N)\) 取决于具体实现) 复杂度。这意味着随着序列长度的增加,Mamba的计算成本和内存占用增长得更为平缓。这使得Mamba能够高效处理数万甚至数百万长度的序列,这在Transformer架构下是难以想象的。据报道,Mamba在推理速度上可以比传统Transformer快5倍以上,尤其在长序列场景下优势更为明显。
性能与长距离依赖捕捉
尽管Transformer的全局注意力机制理论上可以捕捉任意距离的依赖关系,但在实践中,对于极长的序列,其效果可能会因为计算限制或梯度问题而打折扣。Mamba通过其状态向量 \(h(t)\) 来压缩和传递历史信息,并通过选择性机制动态关注相关上下文。多项基准测试表明,Mamba不仅在计算效率上胜出,在各种任务(包括语言建模、语音识别、时间序列预测等)的性能表现上也与Transformer相当,甚至在某些长序列依赖任务上超越了Transformer。
架构简洁性与硬件友好性
Mamba的架构相对更为简洁,因为它摒弃了复杂的自注意力层和多头注意力机制。其核心的SSM操作可以通过针对现代GPU优化的并行扫描算法高效实现,从而更好地利用硬件的并行计算能力。这不仅提升了训练和推理速度,也可能使得模型更容易扩展到更大规模。
Mamba与Transformer特性对比雷达图
下图展示了Mamba与Transformer在几个关键特性上的对比。数值越高代表在该方面表现越优或消耗越低(例如,计算成本低则得分高)。这些评估是基于普遍的认知和公开的研究结果,旨在提供一个直观的比较。
从雷达图可以看出,Mamba在处理长序列时的计算成本、内存占用和推理速度方面具有显著优势,同时在长距离依赖捕捉和并行训练效率方面也表现出色。Transformer则在短序列性能上依然保有竞争力,并且其全局注意力机制在理论上能捕捉任何依赖关系。
Mamba模型核心概念概览
下面的思维导图总结了Mamba模型的关键组成部分和核心优势,帮助您更清晰地理解其整体架构和设计理念。
Mamba与Transformer详细对比
为了更清晰地展示Mamba相对于Transformer的改进之处,下表总结了两者在关键特性上的对比:
| 特性 | Mamba | Transformer |
|---|---|---|
| 核心机制 | 选择性状态空间模型 (Selective SSM) | 自注意力机制 (Self-Attention) |
| 计算复杂度 (序列长度N) | \(O(N)\) 或 \(O(N \log N)\) | \(O(N^2)\) |
| 内存复杂度 (序列长度N) | \(O(N)\) 或 \(O(N \log N)\) (取决于具体实现和是否缓存状态) | \(O(N^2)\) (存储注意力矩阵) |
| 长序列处理能力 | 非常强,能高效处理百万级token序列 | 受限,长序列计算成本高昂 |
| 并行计算 | 训练时通过卷积模式高度并行化;推理时递归模式为顺序 | 自注意力层内高度并行化 |
| 长距离依赖捕捉 | 通过状态压缩和选择性更新有效捕捉 | 理论上全局捕捉,实践中可能受限于计算和梯度 |
| 信息选择性 | 通过输入依赖的参数动态选择信息 | 通过注意力权重动态分配信息重要性 |
| 典型应用场景 | 长文本建模、基因组学、高分辨率视觉、长时间序列预测 | NLP各类任务、短到中等长度序列的各类模态 |
深入了解Mamba:视频解析
以下视频提供了对Mamba模型的详细讲解,包括其背后的动机、与Transformer的比较以及其潜在影响。观看此视频可以帮助您更直观地理解Mamba的创新之处。
视频来源:YouTube频道【博士Vlog】。该视频详细解析了2024年最新的Mamba模型,并探讨了其是否可能“取代”Transformer。
视频中深入探讨了Mamba的技术细节,例如状态空间模型(SSM)的演变,HiPPO框架如何启发了长距离依赖的建模,以及S4(Structured State Space Sequence Model)如何为Mamba铺平了道路。讲解者通常会对比Mamba与RNN、LSTM、GRU以及Transformer在处理序列数据时的根本区别,特别是Mamba如何通过其选择性扫描机制(Selective Scan)来实现对输入数据的上下文感知压缩,从而在保持线性复杂度的同时捕获关键信息。此外,视频可能还会涵盖Mamba在各种基准测试上的表现,以及它在不同领域(如自然语言处理、计算机视觉、语音识别、甚至生物信息学)的应用前景。
常见问题解答 (FAQ)
推荐探索
如果您希望更深入地了解Mamba模型及其相关技术,可以探索以下相关查询:
- 状态空间模型 (SSM) 在深度学习中的演进历史是怎样的?
- Mamba模型在计算机视觉领域的应用有哪些具体案例?
- 比较Mamba、Transformer和RNN在处理不同类型序列数据时的优缺点。
- 探索Mamba模型在多模态学习任务中的潜力与挑战。
参考资料
Last updated May 19, 2025