
Best Open Source Architecture for Enterprise Observability in Multinational Manufacturing
An integrated approach to monitoring, analyzing, and visualizing complex IT infrastructures
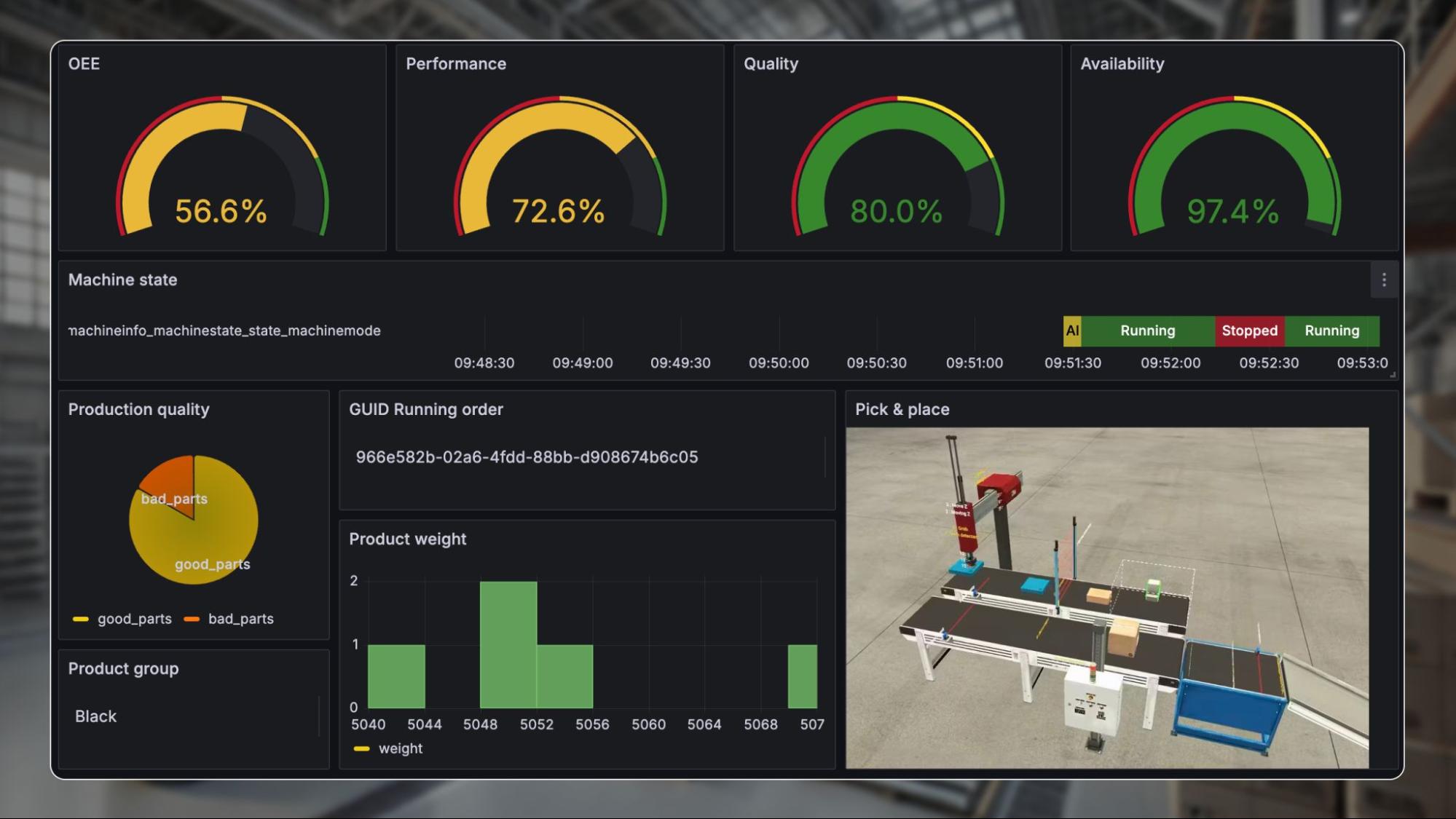
Key Highlights
- Comprehensive Data Collection: Utilize OpenTelemetry, Prometheus, and Fluentd for consistent telemetry data gathering.
- Scalable Data Management: Integrate Apache Kafka, Pinot/Prometheus, and Elasticsearch/ELK for efficient data ingestion and querying.
- Enhanced Visualization and Alerting: Leverage Grafana, Kibana, and Alertmanager to ensure real-time insights and rapid incident resolution.
Architecture Overview
In order to achieve enterprise observability for IT systems in a multinational manufacturing environment, it is vital to design an open source architecture that not only scales with the organization but also caters to a wide array of requirements spanning data collection, processing, analysis, and visualization. The proposed architecture consolidates best practices and components from several leading solutions. This holistic approach ensures robust performance monitoring, effective troubleshooting, and proactive maintenance throughout the entire IT ecosystem.
1. Instrumentation and Data Collection
OpenTelemetry as the Cornerstone
OpenTelemetry has emerged as the industry standard for instrumenting applications and collecting telemetry data. It offers a vendor-neutral framework that caters to logs, metrics, and traces uniformly across various systems. For a manufacturing company with operations spread across multiple geographies, having consistent telemetry is crucial for monitoring system health, diagnosing failures, and ensuring seamless integration of data from diverse sources.
Alongside OpenTelemetry, complementary tools such as Prometheus work efficiently in collecting and storing time-series metrics, while tools like Fluentd ensure that logs and event data from enterprise applications are aggregated effectively.
2. Data Ingestion and Transport
Apache Kafka for High-Volume Data Streams
Due to the massive volumes of telemetry data produced in a multinational manufacturing setup, an efficient early-stage ingestion mechanism is key. Apache Kafka steps in as a scalable, distributed data streaming platform, facilitating the reliable transport of data from instrumented applications to downstream processing systems. Kafka’s robust design enables it to handle concurrent data streams with minimal latency, providing a dependable data pipeline.
3. Data Storage and Query Processing
Real-Time Metrics with Prometheus
Prometheus offers an excellent solution for real-time metrics storage and querying. Its time-series database is optimized for capturing and evaluating metrics from numerous endpoints scattered across multinational sites. Integration with Grafana further improves its capability by providing intuitive visual dashboards that display data trends and anomalies in real-time.
Log Management with ELK Stack and Lightweight Alternatives
For the management of log data, the ELK Stack (Elasticsearch, Logstash, and Kibana) stands out as a popular solution. While Elasticsearch stores logs securely and allows efficient query processing, Logstash ingests data from a variety of sources. Kibana then brings light to this data by providing rich visualization options. Alternatively, for environments that require leaner setups, Grafana Loki can be employed to efficiently process log data.
Using Apache Pinot for Real-Time Analytics
Apache Pinot is another powerful data store designed for real-time analytics. It can handle high query loads and support sub-second latency, which is critical for decision-making processes in manufacturing. Pinot is especially effective for aggregating telemetry data and performing quick, ad hoc analyses, ensuring that operational issues are promptly identified and addressed.
4. Data Analysis and Distributed Tracing
Distributed Tracing with Jaeger or Zipkin
Modern IT systems often deploy microservices architectures which can complicate the task of tracking request journeys across multiple services. Open source tracing tools like Jaeger or Zipkin play a pivotal role in distributed tracing. They visualize how requests traverse through services, highlight bottlenecks, and pinpoint the origin of performance issues. This capability is essential in a production environment where fast incident resolution is necessary.
Incorporation of AI and Machine Learning
As manufacturing systems become increasingly complex, the integration of AI-driven analytics is also becoming a pivotal part of observability. Observability systems can apply machine learning models to predict failures, optimize maintenance schedules, and even suggest operational improvements based on collected telemetry data. This intelligent layer enhances the ability to detect looming issues before they impact operational productivity.
5. Visualization, Alerting, and Centralized Management
Grafana: The Visualization Powerhouse
Grafana remains the tool of choice for creating unified dashboards that synthesize data from Prometheus, OpenTelemetry, and other components. With Grafana, IT teams can build customized dashboards that combine metrics, logs, and trace data, giving them a “single pane of glass” view of system performance. Such centralized visibility is invaluable in multinational environments where consistent monitoring across diverse locations is critical.
Alerting with Prometheus Alertmanager
Complementing visualization, alerting is a vital component of observability. Prometheus Alertmanager is designed to process alerts generated by Prometheus and other integrated systems. It enables fine-tuned alert notifications across different channels (email, SMS, or messaging apps), ensuring the appropriate teams are quickly informed of any anomalies. This rapid alerting mechanism significantly reduces the mean time to resolution (MTTR) in case of incidents.
A Unified Centralized Management Dashboard
For multinational manufacturing companies, distributing management across various teams and geographic regions is a complex challenge. A centralized dashboard that compiles data from Prometheus, ELK, and Jaeger provides a consolidated view of the IT environment. This dashboard serves as a command center where strategic decisions are based on comprehensive, real-time insights derived from multiple telemetry streams.
Comparative Table of Key Tools and Their Roles
| Component | Primary Tool | Role | Key Benefit |
|---|---|---|---|
| Instrumentation & Data Collection | OpenTelemetry, Prometheus, Fluentd | Collect logs, metrics, and traces | Unified telemetry and seamless integration |
| Data Ingestion | Apache Kafka | Stream data from various sources | Efficient handling of high-volume data streams |
| Data Storage & Querying | Prometheus, Apache Pinot, Elasticsearch | Store and quickly query time-series and log data | Real-time analytics and rapid data retrieval |
| Distributed Tracing | Jaeger, Zipkin | Trace distributed microservices | Identify performance issues across services |
| Visualization & Alerting | Grafana, Kibana, Alertmanager | Display data insights and manage alerts | Immediate visualization and rapid incident response |
Implementation Considerations for a Global Deployment
Planning and Assessment
The move toward an open source observability architecture must start with a detailed assessment of the existing IT infrastructure. This involves identifying all data sources across manufacturing locations, evaluating network configurations, and determining regulatory or compliance mandates in different regions.
A critical part of the assessment is to map the various data pipelines and understand the data flow from machines on the shop floor to centralized systems. It is crucial to assess the current level of instrumentation available on legacy systems and plan their upgrade or integration using modern telemetry standards.
Centralized Team Setup and Training
Establishing a centralized observability team is vital. This team is responsible for standardizing data collection practices, managing centralized dashboards, and spearheading alert response protocols. Training IT staff on these new tools – including Grafana dashboard configurations, Prometheus query language, and the nuances of distributed tracing – will be key to ensuring a smooth transition.
Integration and Interoperability
The modular design of the proposed architecture allows manufacturers to select best-of-breed tools for each layer while maintaining interoperability. Leveraging community-supported integrations and maintaining a flexible architecture prevent vendor lock-in and enable custom solutions as requirements evolve.
Scalability and Future-Proofing
Scalability is a primary concern, especially in a multinational setup. The use of distributed tools like Apache Kafka for ingestion and Apache Pinot for analytics supports future growth. Furthermore, as systems generate more telemetry data, leveraging AI-enhanced analytics will provide predictive insights, ensuring that operations remain uninterrupted while accommodating ever-expanding datasets.
Practical Steps for Implementation
1. Evaluate and Map Existing Infrastructure
Start by reviewing your current IT environment. Identify all legacy and modern systems, and map out data flows, potential bottlenecks, and integration points. This initial step lays the groundwork for instrumenting systems with a unified telemetry strategy using OpenTelemetry.
2. Develop a Migration Roadmap
Create a phased migration plan that gradually integrates open source tools. Prioritize critical systems and ensure thorough testing at each phase to minimize disruptions. The roadmap should include setting up parallel monitoring systems until full adoption is achieved.
3. Deploy and Integrate Components
Implement data collection, ingestion, storage, and visualization components incrementally. Integrate tools like Kafka, Prometheus, and Grafana along with distributed tracing frameworks such as Jaeger. Validate interoperability through comprehensive testing across all manufacturing sites.
4. Continuous Monitoring and Optimization
Establish processes for continuous monitoring, regular system audits, and performance tuning. Utilize the centralized dashboard to assess system health in real time, and use feedback from alerts to optimize system configurations. Encourage cross-team collaboration to address issues promptly.
References
- Observability Directory - SourceForge
- Top 5 Observability Tools 2025 - Skedler
- Observability Tools Overview - Middleware.io
- Enterprise Observability Strategy - OpenObserve
- Open Source Observability Tools - Chronosphere
Recommended Related Queries
Last updated March 16, 2025