
释放潜能:Hyper-V 环境下 NVIDIA GPU 性能优化终极指南
深入探索在虚拟化环境中最大化 NVIDIA GPU 性能的关键策略与最佳实践。
在现代计算环境中,利用虚拟化技术共享和管理硬件资源已成为常态。特别是对于需要强大图形处理能力的应用,如专业图形设计、高级数据分析、机器学习和沉浸式游戏,如何在 Hyper-V 虚拟机中高效利用 NVIDIA GPU 资源至关重要。本指南将结合最新的技术进展和行业最佳实践,为您揭示优化 NVIDIA GPU 性能的核心方法。
核心优化亮点
关键洞察与核心建议
- 选择合适的GPU分配策略:深入了解GPU直通 (Discrete Device Assignment - DDA) 和GPU分区 (GPU Partitioning - GPU-P) 的差异,根据您的具体需求(极致性能或资源共享)做出明智选择。
- 确保硬件兼容与正确配置:主机CPU必须支持IOMMU (如Intel VT-d 或 AMD-Vi),所选NVIDIA GPU需支持虚拟化。至关重要的是,在主机和虚拟机内部署从NVIDIA官方获取的最新且版本匹配的驱动程序。
- 全面优化虚拟机与主机环境:为虚拟机分配充足的CPU核心、内存及其他必要资源,使用高性能存储(如SSD)以减少I/O瓶颈,并持续监控GPU利用率以识别并解决潜在的性能问题。
理解GPU虚拟化技术:DDA 与 GPU-P
GPU直通 (DDA) vs. GPU分区 (GPU-P)
在Hyper-V中利用NVIDIA GPU主要有两种技术:GPU直通 (DDA) 和GPU分区 (GPU-P)。理解它们的工作原理、优势和局限性是优化性能的第一步。
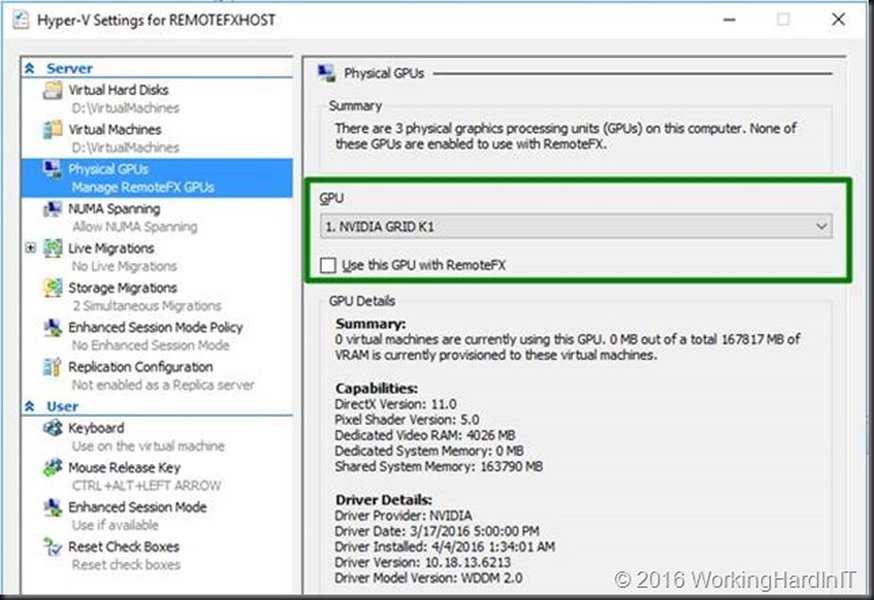
Hyper-V管理器中物理GPU设备分配给虚拟机的设置界面。
GPU直通 (Discrete Device Assignment - DDA)
DDA允许将一个物理PCIe设备(在此情境下是NVIDIA GPU)直接分配给一个虚拟机。虚拟机因此可以独占该GPU,直接访问其硬件资源,从而获得接近物理硬件的性能。这是对性能要求最高的应用(如高端游戏、专业CAD/CAM、大规模并行计算)的理想选择。
- 优势:提供最佳图形性能和最低延迟,因为虚拟机直接控制GPU。
- 劣势:一个GPU只能分配给一个虚拟机,降低了硬件的共享率。配置相对复杂,且实时迁移可能受限或导致性能下降。
- 要求:主机CPU和芯片组需支持IOMMU(Intel VT-d或AMD IOMMU/AMD-Vi),GPU本身也需兼容DDA。
GPU分区 (GPU Partitioning - GPU-P)
GPU-P是较新的技术(在Windows Server 2022及更新版本,如Windows Server 2025中得到增强),它允许将单个物理GPU的资源分割成多个虚拟GPU (vGPU) 实例,并将这些vGPU分配给不同的虚拟机。这使得多个虚拟机可以共享同一个物理GPU的计算能力。
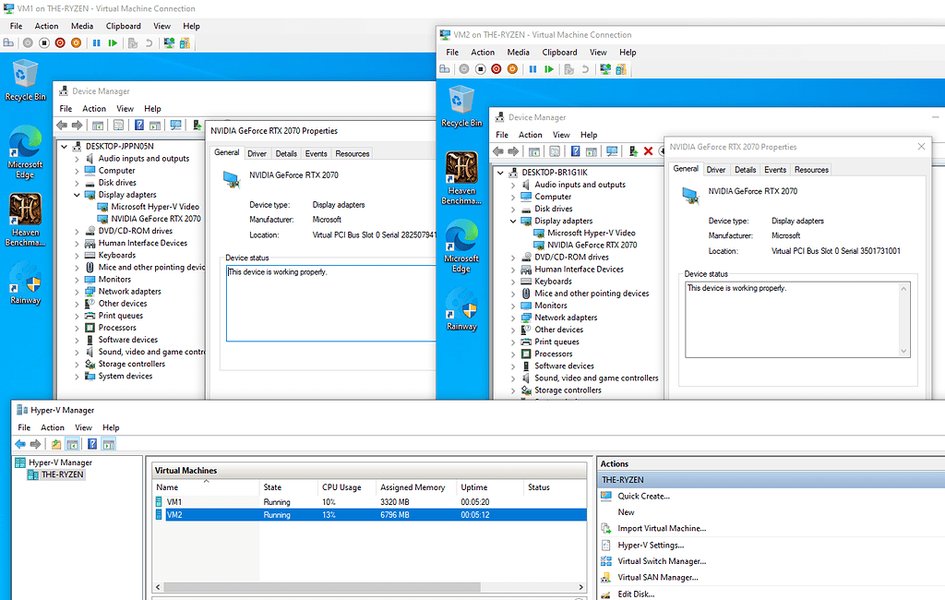
展示GPU分区如何允许多个虚拟机共享单个物理GPU的概念图。
- 优势:提高了GPU的利用率和虚拟机密度,适合VDI环境、轻量级图形应用或多个用户需要GPU加速的场景。
- 劣势:单个虚拟机的性能不如DDA,因为资源是共享的。驱动和硬件兼容性要求特定,目前NVIDIA驱动对GPU-P的实时迁移支持可能有限。
- 要求:需要支持GPU分区的NVIDIA GPU(例如某些NVIDIA A系列或更新的消费级显卡)和相应的驱动程序。
选择合适的虚拟化技术:DDA 与 GPU-P 对比
下表总结了GPU直通 (DDA) 和GPU分区 (GPU-P) 之间的关键区别,以帮助您根据特定需求做出选择。
| 特性 | GPU 直通 (DDA) | GPU 分区 (GPU-P) |
|---|---|---|
| 核心目标 | 为单个VM提供极致、独占的GPU性能 | 在多个VM之间共享物理GPU资源 |
| 性能 | 接近物理GPU的原始性能,延迟最低 | 共享性能,单个VM性能低于DDA,但允许多个VM并发使用 |
| 资源分配 | 整个物理GPU专用于单个VM | 单个物理GPU可划分为多个虚拟GPU,分配给不同VM |
| VM 密度 | 低 (一个物理GPU对应一个VM) | 较高 (一个物理GPU可支持多个VM) |
| 适用场景 | 高性能计算、专业图形工作站、AI训练、高端游戏 | 虚拟桌面基础架构 (VDI)、轻量级图形应用、教育、多用户共享GPU资源 |
| 硬件要求 | 支持IOMMU的CPU,兼容DDA的NVIDIA GPU | 支持GPU分区的NVIDIA GPU (如NVIDIA A系列,部分消费级卡),支持IOMMU的CPU |
| 实时迁移 | 复杂,可能回退到基于TCP/IP的迁移,影响主机CPU和迁移时间 | 支持情况依赖于驱动程序和Hyper-V版本,NVIDIA驱动对GPU-P的实时迁移支持可能存在限制 |
| 配置复杂度 | 中等,主要涉及PowerShell配置 | 中高,涉及GPU驱动、Hyper-V配置及可能的许可管理 |
硬件与主机配置最佳实践
奠定坚实的硬件基础
优化的第一步是确保您的Hyper-V主机硬件能够支持并充分发挥NVIDIA GPU的潜力。
CPU 与主板支持
CPU必须支持输入/输出内存管理单元 (IOMMU) 虚拟化技术。对于Intel平台,这通常指的是VT-d (Virtualization Technology for Directed I/O);对于AMD平台,则是AMD-Vi或IOMMU。此功能需要在系统BIOS/UEFI中启用。确保主板芯片组也完全支持此功能。
选择合适的NVIDIA GPU
并非所有NVIDIA GPU都同等支持虚拟化。企业级GPU(如NVIDIA A系列、Tesla系列、Quadro vDWS)通常提供更全面的虚拟化支持和专用驱动程序(如NVIDIA RTX Virtual Workstation (vWS) 或 NVIDIA Virtual Compute Server (vCS)软件)。一些较新的消费级GPU(如GeForce RTX系列)也可能支持GPU-P等功能,但支持程度和稳定性可能不如企业级产品。请查阅NVIDIA官方文档和您的服务器OEM提供的兼容性列表。

展示NVIDIA先进GPU技术的服务器机架,代表了可用于虚拟化的高性能硬件。
主机内存与存储
为Hyper-V主机分配充足的内存至关重要,建议主机至少保留1GB以上的空闲内存。对于运行GPU密集型任务的虚拟机,其自身也需要大量内存。使用高性能存储,如NVMe SSD,来存放虚拟机VHDX文件和相关数据,可以显著减少I/O瓶颈,从而让GPU更高效地工作。
同构集群配置
如果您在Hyper-V集群环境中使用GPU,强烈建议所有集群节点上的GPU采用相同的品牌、型号、固件版本和驱动程序版本。这种同构配置有助于确保实时迁移的兼容性和成功率,并简化管理。
驱动程序与软件配置
确保软件层面协同工作
正确的驱动程序和软件配置是发挥GPU性能的关键。
主机和虚拟机驱动程序
始终从NVIDIA官方网站下载最新且经过认证的驱动程序。不要依赖Windows Update提供的通用驱动程序,它们可能不包含针对虚拟化优化的全部功能或性能特性。 主机和虚拟机内部安装的NVIDIA驱动程序版本应尽可能匹配,或者遵循NVIDIA针对特定虚拟化方案(DDA或GPU-P)的推荐。 对于DDA,在主机上安装GPU驱动后,通过PowerShell卸载GPU设备,然后将其分配给虚拟机。虚拟机启动后,在其内部安装相应的NVIDIA驱动程序。 对于GPU-P,主机驱动程序需要支持分区功能。虚拟机内部也需要安装支持vGPU的驱动程序。部分场景可能需要NVIDIA RTX Enterprise驱动或许可。
Hyper-V集成服务
确保虚拟机内部安装并运行最新版本的Hyper-V集成服务。这些服务改进了虚拟机与Hyper-V主机之间的交互,对整体性能至关重要。
NVIDIA控制面板和管理工具
在虚拟机内部,如果驱动程序支持,安装并使用NVIDIA控制面板可以对GPU的特定设置进行微调。对于企业级vGPU部署,NVIDIA提供了专门的管理和授权工具,如NVIDIA License System。
虚拟机与 Hyper-V 性能调优
精细调整以获得最佳效果
虚拟机资源分配
为承载GPU加速工作负载的虚拟机分配足够的vCPU核心和内存。CPU和内存不足会成为GPU性能的瓶颈。避免过度分配主机资源,以免导致资源争抢。
避免使用增强会话模式进行高性能图形处理
Hyper-V的增强会话模式基于远程桌面协议 (RDP),它并非为高性能图形或游戏设计。如果您的目标是运行图形密集型应用或游戏,应确保通过DDA或GPU-P直接利用GPU,并可能需要其他远程连接方案(如Parsec、Moonlight等)以获得最佳体验,而非依赖增强会话。
存储和网络优化
除了使用SSD,还可以考虑将虚拟机的VHDX文件配置为固定大小而非动态扩展,以获取更可预测的I/O性能。对于网络敏感型应用,确保虚拟机网络适配器配置得当,并考虑将Hyper-V管理流量和虚拟机数据流量分离到不同的物理网络接口。
禁用不必要的快照和检查点
虽然检查点(快照)对于开发和测试很有用,但它们会引入性能开销,尤其是在I/O密集型操作中。对于生产环境中需要高性能GPU的虚拟机,应尽量避免或谨慎使用检查点。
HighMemoryMappedIoSpace 配置
对于DDA,可能需要调整分配给虚拟机的 `HighMemoryMappedIoSpace` 值。这个值决定了分配给PCIe设备(如GPU)的MMIO空间大小。如果GPU显存较大,可能需要通过PowerShell命令 `Set-VMMemory` 来增加此值,以确保GPU能够被虚拟机正确识别和使用全部显存。
GPU性能因素雷达图
DDA 与 GPU-P 性能特征对比
以下雷达图直观地比较了GPU直通 (DDA) 和GPU分区 (GPU-P) 在几个关键性能相关因素上的表现。这些评估是基于普遍的技术认知,具体表现可能因硬件、工作负载和配置而异。数值越高代表在该方面表现越优或程度越高。
此图表旨在提供一个概览:DDA在原始性能上通常领先,但牺牲了资源灵活性和虚拟机密度。GPU-P则在后两者表现更佳,但会带来更高的设置复杂度和驱动程序管理要求,且原始性能会有所折衷。
可视化优化路径:Hyper-V GPU性能优化思维导图
全面概览优化策略
下面的思维导图概述了在Hyper-V环境中优化NVIDIA GPU性能所涉及的关键领域和考虑因素。这有助于您系统地审视和规划您的优化工作。
(企业级/兼容消费级)"] id1c["高性能存储 (SSD/NVMe)"] id1d["充足的主机RAM"] id1e["同构GPU集群配置 (若适用)"] id1f["BIOS/UEFI 虚拟化支持开启"] id2["GPU虚拟化技术选择"] id2a["GPU直通 (DDA)"] id2aa["独占GPU,性能最佳"] id2ab["单一VM使用场景"] id2ac["PowerShell配置"] id2b["GPU分区 (GPU-P)"] id2ba["共享GPU资源"] id2bb["多VM使用场景 (VDI等)"] id2bc["Windows Server 2022/2025+ 支持"] id2bd["需要特定驱动和GPU型号"] id3["驱动程序管理"] id3a["主机NVIDIA驱动程序
(官方最新版)"] id3b["虚拟机NVIDIA驱动程序
(与主机匹配或推荐版本)"] id3c["定期更新与版本控制"] id3d["避免使用Windows Update提供的驱动"] id3e["NVIDIA RTX Enterprise / vGPU 驱动与许可 (若适用)"] id4["Hyper-V主机优化"] id4a["操作系统更新与补丁"] id4b["网络配置 (专用网络流量)"] id4c["资源监控与平衡"] id5["虚拟机配置与调优"] id5a["操作系统兼容性"] id5b["分配足够的vCPU和内存"] id5c["避免使用增强会话模式 (高性能场景)"] id5d["安装最新Hyper-V集成服务"] id5e["固定大小VHDX"] id5f["调整HighMemoryMappedIoSpace (DDA)"] id6["监控与故障排除"] id6a["使用NVIDIA SMI (nvidia-smi)"] id6b["Hyper-V性能监视器"] id6c["检查主机和VM事件日志"] id6d["性能基准测试 (前后对比)"] id6e["远程访问方案选择 (非RDP)"]
此思维导图将优化过程分解为六个主要分支:硬件考量、GPU虚拟化技术选择、驱动程序管理、Hyper-V主机优化、虚拟机配置与调优,以及监控与故障排除。每个分支下都列出了具体的行动点或考虑因素。
深入了解 Hyper-V GPU 虚拟化新特性
微软官方视角:GPU故障转移集群与GPU分区
观看以下视频,了解微软在 Windows Server 和 Azure Stack HCI 中引入的最新 GPU 虚拟化功能,包括 GPU 故障转移集群和 GPU 分区 (GPU-P)。这些新特性为数据中心带来了更高级别的灵活性和可靠性。
该视频由微软官方发布,深入探讨了如何在 Hyper-V 环境中利用最新的 GPU 技术来增强数据中心的性能和能力。特别关注了 GPU-P 如何允许多个虚拟机共享一个物理 GPU,以及 GPU 故障转移集群如何提高虚拟化 GPU 工作负载的可用性。这些信息对于规划和部署需要 GPU 加速的现代虚拟化基础设施非常有价值。
常见问题解答 (FAQ)
推荐探索
进一步深入研究的相关查询
- 如何在Hyper-V中为虚拟机配置NVIDIA GPU直通(DDA)的详细步骤?
- 比较不同NVIDIA GPU型号在Hyper-V虚拟化环境中的性能表现如何?
- Hyper-V GPU分区(GPU-P)与NVIDIA vGPU技术的许可和成本有哪些考虑因素?
- 解决Hyper-V虚拟机中NVIDIA GPU无法识别或驱动安装失败的常见方法有哪些?
参考资料
信息来源与深入阅读
Last updated May 6, 2025