
优化 vLLM 参数以提升性能
通过智能调优释放大语言模型的全部潜力
vLLM 是一个专为大语言模型(LLM)推理和服务而设计的快速且易于使用的库。它通过创新的优化技术,如 PagedAttention,显著提高了 LLM 的服务吞吐量和效率。为了进一步提升 vLLM 的性能以满足特定的应用需求,进行参数调优是至关重要的一步。本文将深入探讨 vLLM 的关键参数及其优化策略,帮助您最大限度地发挥 LLM 的潜力。
核心亮点
- PagedAttention 机制:vLLM 采用 PagedAttention,借鉴操作系统虚拟内存的思想,优化 KV Cache 的管理,显著提高吞吐量并减少内存占用。
- 关键参数调优:通过调整
max_num_batched_tokens、gpu_memory_utilization、max_model_len等参数,可以平衡吞吐量、延迟和内存使用,从而实现更优的性能。 - 并行策略:对于大型模型,利用 Tensor Parallelism、Pipeline Parallelism 和 Expert Parallelism 等并行策略,可以将模型分布到多个 GPU 上,克服单 GPU 内存限制。
vLLM 性能优化的基石:PagedAttention
在深入参数调优之前,理解 vLLM 实现高性能的核心机制——PagedAttention——是必要的。传统的 LLM 服务方式在处理变长序列时,KV Cache(Key and Value Cache)的管理效率低下,容易导致内存碎片和低 GPU 利用率。vLLM 的 PagedAttention 受操作系统虚拟内存的启发,将 KV Cache 存储在固定大小的块(blocks)中,这些块可以非连续地分配和管理。这种方法极大地提高了内存利用率,并允许高效地处理并发请求。
PagedAttention 的核心思想是将每个序列的 KV Cache 分割成固定大小的块,并使用一个页表来映射逻辑块到物理块。这使得 vLLM 能够有效地共享 KV Cache 块、避免内存碎片,并在需要时对请求进行抢占以释放资源。这种创新的 KV Cache 管理方式是 vLLM 实现高吞吐量和低延迟的关键。
关键 vLLM 参数及其优化策略
vLLM 提供了丰富的参数来控制其行为和性能。通过对这些参数进行精细调优,可以针对特定的硬件配置、模型大小和工作负载需求,最大化 vLLM 的性能。
批量处理与序列长度控制
max_num_batched_tokens
max_num_batched_tokens 参数控制在一次推理批次中允许的最大 token 数量。这个参数直接影响吞吐量和 GPU 内存使用。较大的值可以提高 GPU 的利用率,从而增加吞吐量,尤其对于较小的模型和大型 GPU。然而,过大的值可能会增加内存需求,甚至导致显存不足(OOM)错误。
默认情况下,该参数通常设置为 2048。根据 vLLM 的优化指南,为了获得最佳吞吐量,建议将 max_num_batched_tokens 设置得较大,尤其是在大型 GPU 上运行较小模型时,可以考虑大于 8096 的值。如果将其设置为与 max_model_len 相同,则行为将类似于 v0 版本的默认调度策略(但仍优先处理解码)。
调优建议:
- 对于追求高吞吐量的场景,可以尝试逐步增加
max_num_batched_tokens的值,同时监控 GPU 内存使用情况,直到达到性能瓶颈或遇到 OOM 错误。 - 对于对延迟要求较高的场景,可以尝试减小
max_num_batched_tokens的值,但这可能会牺牲一定的吞吐量。 - 如果启用 chunked prefill (
enable_chunked_prefill),可以从较小的值开始尝试,如 128,并逐步增加,以找到最佳平衡。
max_model_len
max_model_len 参数指定模型支持的最大上下文长度。设置合适的 max_model_len 可以限制 KV Cache 的大小,从而节省 GPU 内存并可能提升性能。如果您的应用场景不需要模型处理过长的序列,将此参数设置为小于模型原生最大上下文长度的值是一个有效的优化手段。
调优建议:
- 确定您的实际应用中所需的最大上下文长度,并将
max_model_len设置为该值。 - 如果模型原生支持的最大上下文长度远大于您的需求,适当减小
max_model_len可以显著降低内存占用并提高效率。
内存利用率控制
gpu_memory_utilization
gpu_memory_utilization 参数控制用于预分配 GPU KV Cache 的显存比例,取值范围在 0 到 1 之间。例如,0.5 表示使用 50% 的 GPU 显存用于 KV Cache。默认值通常为 0.9。
适当设置 gpu_memory_utilization 对于平衡吞吐量和 OOM 风险至关重要。较高的值可以为 KV Cache 提供更多空间,从而支持更大的批次和更长的序列,通常能提高吞吐量。然而,如果模型参数、优化器状态(如果在训练或微调过程中)以及 KV Cache 的总内存需求超过可用显存,就会发生 OOM 错误。
调优建议:
- 推荐的范围是 0.5 到 0.7,以平衡吞吐量和 OOM 风险。
- 如果遇到 OOM 错误,首先尝试减小
gpu_memory_utilization的值。 - 如果您的 GPU 内存充裕,并且希望最大化吞吐量,可以尝试逐步增加该值。
- 这是一个每个 vLLM 实例的限制,即使在同一 GPU 上运行多个 vLLM 实例,它们各自的
gpu_memory_utilization设置是独立的。
缓存和预填充优化
enable_prefix_caching
启用前缀缓存(enable_prefix_caching)可以提高处理具有相同前缀请求时的效率。vLLM 会缓存这些共享前缀的 KV Cache,避免重复计算。这对于处理大量具有相似开头的用户查询非常有用。
调优建议:
- 如果您的工作负载中包含大量具有共同前缀的请求,启用前缀缓存可以显著提高性能。
enable_chunked_prefill
启用分块预填充(enable_chunked_prefill)可以改善 इंटर-token latency (ITL)。传统的预填充阶段涉及处理整个输入序列,这可能导致较长的 ITL。分块预填充将输入序列分割成更小的块进行处理,使得解码阶段可以更快开始,从而降低 ITL。
调优建议:
- 如果对 ITL 有严格要求,可以尝试启用分块预填充。
- 启用此参数后,需要配合调整
max_num_batched_tokens等参数,从较小的值开始测试,找到最佳配置。 - 分块预填充可能会影响整体吞吐量,因此需要根据具体场景权衡。
并行化策略
对于无法完全载入单个 GPU 显存的大型模型(例如 70B 参数模型),vLLM 支持多种并行化策略,将模型分布到多个 GPU 上进行推理。
Tensor Parallelism (tensor_parallel_size)
Tensor Parallelism 将模型的每个层内的张量(例如权重矩阵)分割到多个 GPU 上。这减少了单个 GPU 的显存占用,使得更大的模型得以运行。tensor_parallel_size 参数指定用于 Tensor Parallelism 的 GPU 数量。
调优建议:
- 对于大型模型,Tensor Parallelism 是 필수 的。根据模型的需要和可用的 GPU 数量设置
tensor_parallel_size。
Pipeline Parallelism (pipeline_parallel_size)
Pipeline Parallelism 将模型的不同层分配给不同的 GPU,形成一个处理流水线。这可以减少内存需求并提高 GPU 利用率。
调优建议:
- Pipeline Parallelism 可以与 Tensor Parallelism 结合使用,进一步减少显存占用。
Expert Parallelism (enable_expert_parallel)
Expert Parallelism 专为 Mixture of Experts (MoE) 模型设计,将不同的专家网络分配到不同的 GPU 上。启用此参数后,MoE 层将使用 Expert Parallelism 而非 Tensor Parallelism 进行分片。
调优建议:
- 如果使用 MoE 模型,启用 Expert Parallelism 是一个有效的优化策略。
Data Parallelism (data_parallel_size)
Data Parallelism 将不同的请求分配到不同的 GPU 上,每个 GPU 运行模型的完整副本。这主要用于扩展吞吐量,处理大量并发请求。
调优建议:
- Data Parallelism 可以与 Tensor Parallelism 和 Pipeline Parallelism 结合使用。
采样参数
vLLM 也支持多种采样参数,用于控制文本生成的随机性和多样性,例如 temperature、top_p、top_k 等。这些参数通常不会显著影响推理性能本身(吞吐量和延迟),但会影响生成文本的质量和特性。可以通过 SamplingParams 类进行配置。
调优建议:
- 根据您的应用需求调整采样参数,以获得期望的生成结果。例如,较低的 temperature 值会产生更确定性的输出,而较高的值会增加随机性。
- 默认情况下,vLLM 会尝试加载 Hugging Face 模型仓库中的
generation_config.json文件中推荐的采样参数。如果您希望使用 vLLM 的默认采样参数,可以在初始化 LLM 实例时设置generation_config="vllm"。
量化技术
量化是一种减小模型大小和计算需求的技术,通过降低模型权重的精度(例如从 FP16 降到 INT8 或 FP8)。vLLM 支持多种量化技术,可以显著提高推理速度并减少显存占用。
调优建议:
- 考虑使用 FP8 或 INT8 等量化技术。根据 Reddit 上的讨论,FP8 动态量化可能比 BitsAndBytes 量化在处理更大批次时表现更好。
- 推荐预先量化模型,因为运行时量化会增加端点启动时间。
其他高级参数
optimization_level
optimization_level 参数控制 vLLM 应用的优化级别。默认级别为 0,表示没有应用任何优化。级别 1 和 2 用于内部测试,而级别 3 是推荐用于生产环境的优化级别。
调优建议:
- 在生产环境中,建议将
optimization_level设置为 3 以获得最佳性能。
guided_decoding_backend
guided_decoding_backend 参数指定用于 guided decoding(例如 JSON schema 或 regex 约束生成)的后端。默认值为 "auto",vLLM 会根据请求内容和后端库支持情况自动选择。v1 版本支持 "auto"、"xgrammar" 和 "guidance"。可以通过设置 disable_fallback=True 来禁用回退到不同后端。
调优建议:
- 如果您使用 guided decoding 功能,可以根据您的需求和特定后端库的特性选择合适的后端。
性能监控与测试
调优参数是一个迭代的过程。在调整参数后,需要对 vLLM 的性能进行监控和测试,以评估调整的效果。vLLM 提供了一些工具和指标来帮助您进行性能分析。
- Prometheus 指标:vLLM 可以暴露 Prometheus 指标,用于监控请求吞吐量、延迟、GPU 利用率、KV Cache 使用情况以及请求抢占次数等关键指标。
- 日志记录:通过设置
disable_log_stats=False,可以记录累计的性能统计信息,例如抢占请求的数量。 - 性能测试脚本:利用 vLLM OpenAI API 提供的测试脚本,可以检查速度和延迟,帮助您找到适合特定需求的最佳设置。
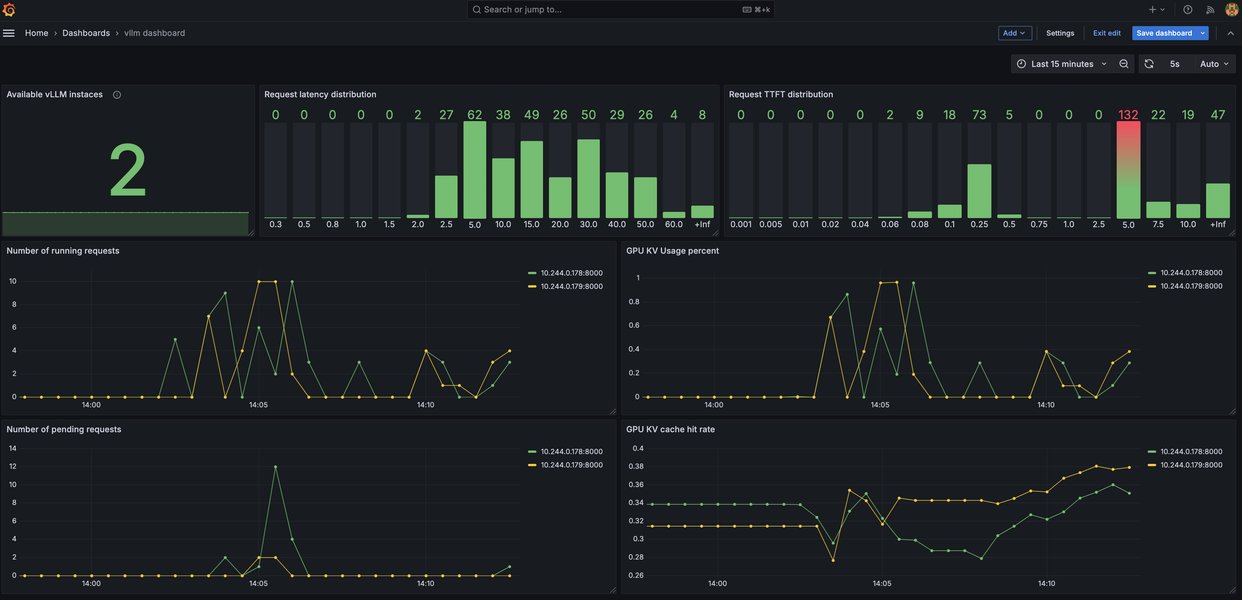
定期测试和解释结果是优化 vLLM 性能的关键。通过对不同参数配置下的性能数据进行分析,您可以找到最优的参数组合。
结合硬件平台进行优化
vLLM 的性能也与底层硬件平台密切相关。针对不同的 GPU 架构(如 NVIDIA A100、H100,或者 Habana Gaudi3、AMD MI300X),可能需要采取不同的优化策略。
-
NVIDIA GPU:vLLM 支持 FlashAttention、FlashInfer 或 XFormers 等多种高效的 Attention 计算后端,并会自动选择最适合您系统和模型的后端。也可以通过设置环境变量
VLLM_ATTENTION_BACKEND手动指定。 -
Habana Gaudi3:Gaudi3 针对 AI 工作负载进行了优化,并支持 BF16/FP8 精度。在 Gaudi3 上微调 LLM 时,建议使用 BF16 精度以获得最佳性能。
-
硬件选择:选择合适的硬件对于运行 LLM 至关重要。根据模型大小和性能需求,可能需要考虑具有足够显存和计算能力的 GPU。

常见问题解答 (FAQ)
如何平衡 vLLM 的吞吐量和延迟?
平衡吞吐量和延迟通常需要权衡。增加 max_num_batched_tokens 和 gpu_memory_utilization 通常可以提高吞吐量,但可能会增加延迟。启用 enable_chunked_prefill 可以降低 ITL,但可能牺牲整体吞吐量。通过实验不同参数组合并监控性能指标,可以找到适合您应用需求的最佳平衡点。
显存不足 (OOM) 时应该如何处理?
如果遇到 OOM 错误,可以尝试以下方法:减小 gpu_memory_utilization 的值;减小 max_model_len;减小 max_num_seqs(限制批处理大小);对于大型模型,使用 Tensor Parallelism 或 Pipeline Parallelism 将模型分布到多个 GPU 上;考虑使用量化技术减小模型大小。
vLLM V1 版本有哪些重要变化?
vLLM V1 引入了简化的核心架构,不再需要 KV Cache 交换来处理请求抢占,这简化了系统设计。V1 目前默认启用,但可以通过设置环境变量 VLLM_USE_V1=0 来禁用。V1 对某些模型架构和 structured output 后端支持有所调整。
如何选择合适的 vLLM 参数用于生产环境高负载场景?
针对生产环境的高用户负载,没有一个通用的最佳参数设置公式。建议从默认参数开始,然后根据实际负载模式和硬件资源,逐步调整 max_num_batched_tokens、gpu_memory_utilization 和并行化参数。持续监控性能指标并进行 A/B 测试是找到最优配置的关键。参考 vLLM 社区的讨论和 GitHub Issue 也可以获取其他用户的经验分享。
结论
vLLM 是一个强大的 LLM 推理和服务库,通过 PagedAttention 等创新技术实现了卓越的性能。通过理解和调优 max_num_batched_tokens、gpu_memory_utilization、并行化策略以及其他关键参数,并结合性能监控和硬件优化,您可以显著提升 LLM 的服务效率和用户体验。参数调优是一个持续优化的过程,需要根据具体需求和环境进行迭代。
参考文献
Last updated May 15, 2025