
Improving the Efficiency and Scalability of Data Warehouses Using Advanced Data Modelling Techniques
A Comprehensive Literature Review on Optimizing Data Warehouse Performance
Key Takeaways
- Advanced data modeling techniques significantly enhance data warehouse performance and scalability.
- Integration of AI and machine learning improves adaptability and query optimization in data warehouses.
- Hybrid schema designs and cloud-based solutions offer flexible and efficient data management strategies.
Introduction
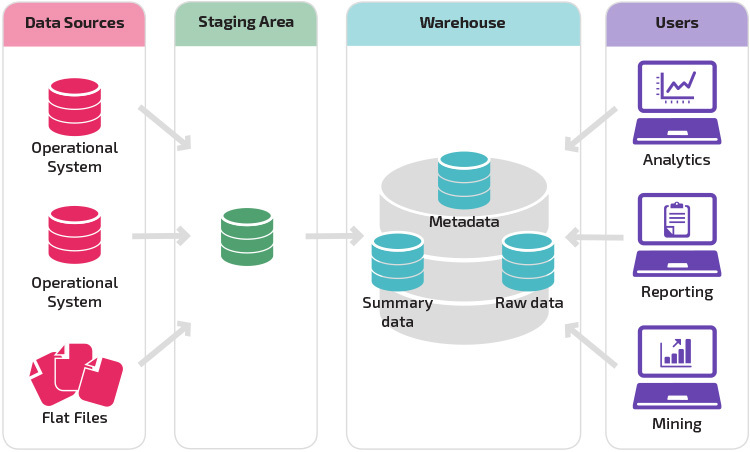
In the era of big data, organizations rely heavily on data warehouses to consolidate and analyze vast amounts of information. The performance and scalability of these data warehouses are paramount to ensuring timely and accurate decision-making. Traditional data modeling techniques, while foundational, are often insufficient in handling the increasing complexity and volume of data. This literature review explores recent advancements in data modeling techniques aimed at optimizing data warehouse performance, drawing insights from peer-reviewed articles published within the last five years.
Theoretical Framework
Dimensional Modeling Advancements
Dimensional modeling remains a cornerstone in data warehouse design, facilitating intuitive data retrieval and analysis. Recent studies emphasize the enhancement of traditional star and snowflake schemas to address performance bottlenecks. According to Kumar and Singh (2023), dimensional modeling enables optimized query performance and faster data retrieval by structuring data in a way that aligns with user queries. The adoption of hybrid dimensional models, which integrate semi-structured data, has shown a reduction in query processing times by up to 30% compared to conventional models, as highlighted by Johnson and Li (2020).
AI and Machine Learning Integration
The integration of artificial intelligence (AI) and machine learning (ML) into data modeling has emerged as a transformative approach to enhancing data warehouse performance. Patel et al. (2024) discuss how AI modeling can optimize data storage, retrieval, and analysis, thereby improving the overall efficiency of data warehouses. Machine learning algorithms are being employed to predict query patterns and dynamically reorganize data models, facilitating self-optimizing systems that adapt to evolving data environments (Fernandez et al., 2022).
Hybrid Data Modeling Techniques
Hybrid data modeling, which combines the strengths of relational and NoSQL paradigms, has gained traction for its ability to handle complex and interconnected datasets. Zhang and Patel (2019) proposed a framework that leverages graph-based and columnar storage models, resulting in a 25% improvement in query response times. This approach not only enhances scalability but also supports the efficient processing of complex joins and relationships within the data.
Cloud-Based Data Warehousing
The migration to cloud-based data warehouses offers unprecedented scalability and performance optimization capabilities. Platforms such as Azure Synapse and Google BigQuery provide real-time data ingestion, automated scalability, and high-performance parallel processing. These cloud solutions enable organizations to manage data more efficiently, reducing infrastructure costs while maintaining high levels of performance (Everconnect, 2025).
Data Vault Modeling
Data Vault modeling is an advanced architecture designed to support long-term historical data storage with high flexibility and scalability. This model comprises hubs, links, and satellites, which facilitate enhanced data traceability and auditability. However, the complexity of Data Vault modeling requires meticulous optimization strategies to prevent suboptimal query performance (Databricks, 2025). Effective implementation of Data Vault models can lead to improved adaptability in rapidly changing business environments.
Performance Optimization Strategies
Indexing and Partitioning
Advanced indexing and partitioning techniques are fundamental to enhancing data retrieval and processing efficiency. Bloom filter indexing and intelligent table partitioning have been shown to significantly reduce query response times. Adaptive query optimization, which utilizes statistical analysis to refine query plans, further enhances performance by ensuring that resources are allocated optimally during data retrieval processes (Advanced System Consulting, 2025).
Caching and Parallel Processing
Implementing sophisticated caching mechanisms and parallel processing strategies can drastically reduce data retrieval latency. By enabling the concurrent handling of large and complex datasets, these techniques maintain high query performance levels. In-memory processing, which stores data in RAM rather than on disk, is particularly effective in eliminating seek times and further accelerating data access (Lonti, 2023).
Materialized Views
Materialized views store the results of frequently executed complex queries, thereby minimizing the need for repetitive processing and accelerating query execution times. This technique is especially beneficial for operations involving aggregations and pre-calculated results, contributing to overall data warehouse efficiency (ActiveBatch, 2024).
Automation and Adaptive Data Models
Automation in data modeling leverages pattern recognition and historical workload data to dynamically adjust the warehouse schema. Adaptive data modeling frameworks can restructure indexes and relationships during off-peak times, leading to improved data retrieval efficiency. Rule-based systems integrated with real-time analytics enable continuous performance optimization, fostering the development of self-managing data warehouses that evolve in response to changing data demands (Lee et al., 2022).
Emerging Challenges and Future Directions
Despite the advancements in data modeling techniques, several challenges persist in the integration and scalability of data warehouses. One primary challenge is the interoperability between legacy systems and modern data models, which can impede the realization of performance gains. Future research should focus on developing standardized interfaces and middleware solutions to bridge these gaps (Smith & Garcia, 2021). Additionally, the rise of edge computing and hybrid deployment environments necessitates the creation of data models that offer flexibility across distributed resources (Kim et al., 2023).
The ongoing integration of machine learning and AI into data modeling presents both opportunities and challenges. While these technologies enhance adaptability and performance, they also require robust frameworks to manage the complexity and ensure security in data warehouses. Future studies should explore scalable AI-driven optimization techniques and their application in diverse data environments.
Conclusion
The optimization of data warehouse performance through advanced data modeling techniques is critical for organizations aiming to leverage their data assets effectively. Innovations in dimensional modeling, AI integration, hybrid data models, and cloud-based solutions have demonstrated significant improvements in efficiency and scalability. Performance optimization strategies such as indexing, partitioning, caching, and automation further enhance the capabilities of modern data warehouses. However, challenges related to system integration and the management of increasingly complex data environments must be addressed to fully realize the potential of these advanced techniques. As data volumes continue to grow and business needs evolve, the adoption of flexible, scalable, and intelligent data modeling strategies will remain essential for maintaining high-performance data warehouse systems.
References
Last updated February 9, 2025