
ไขความลับโมเดลข้อมูลนับ: Poisson, ZIP, และ Negative Binomial Regression แตกต่างกันอย่างไร?
เจาะลึก 3 โมเดลการถดถอยยอดนิยมสำหรับวิเคราะห์ข้อมูลจำนวนนับ พร้อมเลือกใช้ให้เหมาะกับงานของคุณ
ในโลกของการวิเคราะห์ข้อมูล การทำความเข้าใจลักษณะเฉพาะของข้อมูลที่เรากำลังทำงานด้วยเป็นสิ่งสำคัญอย่างยิ่ง โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับ "ข้อมูลนับ" (count data) ซึ่งหมายถึงข้อมูลที่แสดงจำนวนครั้งของการเกิดเหตุการณ์ต่างๆ เช่น จำนวนลูกค้าที่เข้าร้านต่อวัน จำนวนข้อบกพร่องในผลิตภัณฑ์ หรือจำนวนการคลิกโฆษณา โมเดลการถดถอยทั่วไปอาจไม่เหมาะสมกับข้อมูลประเภทนี้เสมอไป วันนี้เราจะมาทำความรู้จักกับ 3 โมเดลการถดถอยที่ถูกออกแบบมาสำหรับข้อมูลนับโดยเฉพาะ ได้แก่ Poisson Regression, Zero-Inflated Poisson (ZIP) Regression และ Negative Binomial Regression พร้อมทั้งเปรียบเทียบความแตกต่างและแนวทางการเลือกใช้งานอย่างละเอียด
ไฮไลท์สำคัญ: สรุปประเด็นหลักที่คุณควรรู้
- Poisson Regression: เหมาะสำหรับข้อมูลนับพื้นฐานที่ค่าเฉลี่ยและความแปรปรวนมีค่าเท่ากัน (equidispersion) และไม่มีจำนวนศูนย์มากผิดปกติ
- Negative Binomial Regression: เป็นตัวเลือกที่ดีเมื่อข้อมูลนับของคุณแสดงลักษณะ "overdispersion" คือมีความแปรปรวนสูงกว่าค่าเฉลี่ย
- Zero-Inflated Poisson (ZIP) Regression: ออกแบบมาเพื่อจัดการกับข้อมูลที่มี "excess zeros" หรือจำนวนค่าศูนย์ที่สังเกตได้มีมากกว่าที่คาดการณ์ไว้โดยโมเดล Poisson มาตรฐาน
ทำความรู้จักแต่ละโมเดลอย่างละเอียด
การเลือกโมเดลที่เหมาะสมขึ้นอยู่กับความเข้าใจในข้อสมมติฐานและลักษณะเฉพาะของแต่ละโมเดล เรามาเจาะลึกรายละเอียดของแต่ละโมเดลกันครับ
1. Poisson Regression: พื้นฐานของข้อมูลนับ
Poisson Regression เป็นรูปแบบหนึ่งของ Generalized Linear Model (GLM) ที่ใช้ในการสร้างแบบจำลองความสัมพันธ์ระหว่างตัวแปรตาม (dependent variable) ที่เป็นข้อมูลนับ กับชุดของตัวแปรอิสระ (independent variables)
ภาพตัวอย่างกราฟที่แสดงการกระจายของข้อมูลที่อาจเหมาะสมกับ Poisson Regression
ข้อสมมติฐานหลัก
ข้อสมมติฐานที่สำคัญที่สุดของ Poisson Regression คือ ค่าเฉลี่ย (mean) ของข้อมูลนับจะเท่ากับค่าความแปรปรวน (variance) ของมัน หรือที่เรียกว่า "equidispersion" เขียนเป็นสมการได้ว่า:
\[ E(Y_i) = \lambda_i \]
\[ \text{Var}(Y_i) = \lambda_i \]
โดยที่ \( Y_i \) คือจำนวนนับที่สังเกตได้ และ \( \lambda_i \) คืออัตราการเกิดเหตุการณ์เฉลี่ยสำหรับ observation ที่ \( i \)
โมเดลนี้จะเชื่อมโยงอัตราการเกิดเหตุการณ์ \( \lambda_i \) กับตัวแปรอิสระ \( X \) ผ่านฟังก์ชัน log link:
\[ \ln(\lambda_i) = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \dots + \beta_p X_{pi} \]
การใช้งานและข้อจำกัด
Poisson Regression เหมาะสำหรับข้อมูลที่จำนวนเหตุการณ์เกิดขึ้นอย่างสุ่มและเป็นอิสระต่อกันในช่วงเวลาหรือพื้นที่ที่กำหนด และอัตราการเกิดคงที่ ตัวอย่างเช่น จำนวนอีเมลที่ได้รับต่อชั่วโมง หรือจำนวนลูกค้าที่โทรเข้ามายังศูนย์บริการต่อวัน
ข้อจำกัด:
- Overdispersion: หากข้อมูลจริงมีความแปรปรวนมากกว่าค่าเฉลี่ย (Variance > Mean) การใช้ Poisson Regression อาจนำไปสู่การประมาณค่า standard errors ที่ต่ำเกินไป ทำให้สรุปผลผิดพลาดได้ (เช่น พบว่าตัวแปรมีนัยสำคัญทั้งที่จริงแล้วไม่มี)
- Underdispersion: ในทางกลับกัน หากความแปรปรวนน้อยกว่าค่าเฉลี่ย (Variance < Mean) ก็เป็นปัญหาเช่นกัน แม้จะพบได้น้อยกว่า
- Excess Zeros: ถ้าข้อมูลมีจำนวนค่าศูนย์ (0) มากเกินกว่าที่การกระจายแบบ Poisson คาดการณ์ไว้ โมเดลนี้อาจไม่เหมาะสม
2. Negative Binomial Regression: รับมือกับ Overdispersion
Negative Binomial Regression (NBR) เป็นอีกทางเลือกหนึ่งสำหรับข้อมูลนับ และมักถูกใช้เมื่อข้อมูลแสดงลักษณะ "overdispersion" อย่างชัดเจน NBR เป็นการขยายแนวคิดของ Poisson Regression โดยเพิ่มพารามิเตอร์ที่เรียกว่า "dispersion parameter" (มักแทนด้วย \( \alpha \) หรือ \( k \)) เข้ามาเพื่อจัดการกับความแปรปรวนส่วนเกิน
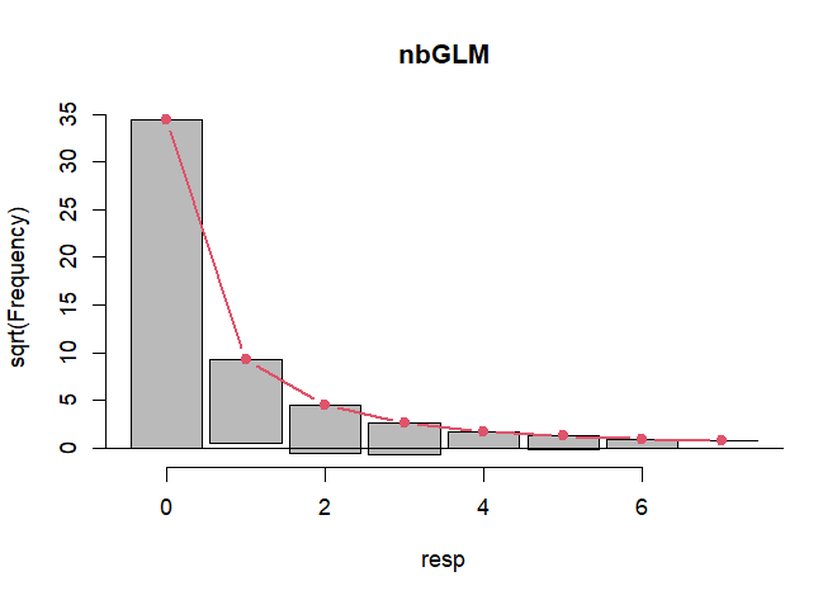
Rootogram เปรียบเทียบความถี่ที่สังเกตได้กับความถี่ที่คาดการณ์โดยโมเดล Negative Binomial ซึ่งช่วยประเมินความพอดีของโมเดลกับข้อมูลที่มี overdispersion
ข้อสมมติฐานและความสัมพันธ์กับ Poisson
ใน Negative Binomial Regression ความสัมพันธ์ระหว่างค่าเฉลี่ยและความแปรปรวนจะเป็นดังนี้:
\[ \text{Var}(Y_i) = \mu_i + \alpha \mu_i^2 \]
หรือในบางตำราอาจเขียนเป็น:
\[ \text{Var}(Y_i) = \mu_i (1 + \alpha \mu_i) \]
หรือ
\[ \text{Var}(Y_i) = \mu_i + \frac{\mu_i^2}{k} \]
โดย \( \mu_i \) คือค่าเฉลี่ย และ \( \alpha \) (หรือ \( 1/k \)) คือ dispersion parameter ที่แสดงระดับของ overdispersion
- ถ้า \( \alpha = 0 \) (หรือ \( k \to \infty \)), Negative Binomial Regression จะลดรูปกลายเป็น Poisson Regression ซึ่งหมายความว่า Poisson Regression เป็นกรณีพิเศษของ Negative Binomial Regression
- ถ้า \( \alpha > 0 \), แสดงว่ามี overdispersion (Variance > Mean)
การใช้งาน
NBR เหมาะสำหรับข้อมูลนับที่ความแปรปรวนมีค่าสูงกว่าค่าเฉลี่ยอย่างมีนัยสำคัญ เช่น จำนวนครั้งที่นักเรียนขาดเรียน (บางคนอาจไม่เคยขาด บางคนอาจขาดบ่อยมาก) หรือจำนวนปรสิตในโฮสต์ (การกระจายตัวของปรสิตมักไม่สม่ำเสมอ) การใช้ NBR ในสถานการณ์เหล่านี้จะให้ค่า standard errors และ p-values ที่น่าเชื่อถือกว่า Poisson Regression
3. Zero-Inflated Poisson (ZIP) Regression: จัดการกับ "Excess Zeros"
Zero-Inflated Poisson (ZIP) Regression เป็นโมเดลที่ออกแบบมาเพื่อจัดการกับข้อมูลนับที่มีจำนวนค่าศูนย์ (zeros) มากเกินไปกว่าที่โมเดล Poisson มาตรฐานจะคาดการณ์ได้ (เรียกว่า "excess zeros" หรือ "zero inflation") โมเดล ZIP สันนิษฐานว่าค่าศูนย์ที่สังเกตได้นั้นมาจากสองกระบวนการที่แตกต่างกัน:
- กระบวนการสร้างศูนย์ (Zero-generating process): ส่วนนี้จะทำนายว่าผลลัพธ์จะเป็น "ศูนย์แท้" (true zero) หรือไม่ ซึ่งหมายถึงกลุ่มที่ไม่สามารถเกิดเหตุการณ์ได้เลย หรือมีโอกาสเกิดเหตุการณ์เป็นศูนย์เสมอด้วยเหตุผลบางอย่าง ส่วนนี้มักจะใช้โมเดลโลจิสติก (Logistic Regression) เพื่อทำนายความน่าจะเป็น \( \pi_i \) ที่ observation \( i \) จะมาจากกลุ่ม "ศูนย์แท้"
- กระบวนการนับ (Count process): ส่วนนี้จะทำนายจำนวนนับสำหรับกลุ่มที่ "ไม่ใช่ศูนย์แท้" (สามารถเกิดเหตุการณ์ได้) ซึ่งจะตามการกระจายแบบ Poisson ด้วยค่าเฉลี่ย \( \lambda_i \)
ดังนั้น ความน่าจะเป็นที่จะสังเกตเห็นค่าศูนย์ \( P(Y_i=0) \) ในโมเดล ZIP คือ:
\[ P(Y_i=0) = \pi_i + (1-\pi_i)e^{-\lambda_i} \]
และความน่าจะเป็นที่จะสังเกตเห็นค่าที่ไม่ใช่ศูนย์ \( k > 0 \) คือ:
\[ P(Y_i=k) = (1-\pi_i) \frac{e^{-\lambda_i}\lambda_i^k}{k!} \quad \text{for } k > 0 \]
การใช้งาน
ZIP Regression เหมาะสมเมื่อมีเหตุผลทางทฤษฎีที่เชื่อได้ว่ามีสองกลุ่มประชากรที่แตกต่างกันในการสร้างข้อมูลศูนย์ ตัวอย่างเช่น:
- จำนวนบุหรี่ที่สูบต่อวัน: กลุ่มหนึ่งคือผู้ที่ไม่เคยสูบบุหรี่ (ศูนย์แท้) และอีกกลุ่มคือผู้ที่สูบบุหรี่ (อาจสูบ 0 มวนในวันนั้น หรือมากกว่านั้น)
- จำนวนปลาที่จับได้ในแต่ละครั้งที่ออกเรือ: บางครั้งอาจจะไม่ได้ปลาเลยเพราะสภาพอากาศไม่อำนวย (ปัจจัยที่ทำให้เป็นศูนย์แท้) หรือบางครั้งไม่ได้ปลาเพราะโชคไม่ดี (ปัจจัยในกระบวนการนับ)
หมายเหตุ: หากข้อมูลมีทั้ง overdispersion และ excess zeros อาจต้องพิจารณาโมเดลที่ซับซ้อนขึ้น เช่น Zero-Inflated Negative Binomial (ZINB) Regression ซึ่งรวมคุณสมบัติของ NBR (จัดการ overdispersion) และ ZIP (จัดการ excess zeros) เข้าด้วยกัน
ตารางเปรียบเทียบความแตกต่างที่สำคัญ
เพื่อให้เห็นภาพรวมความแตกต่างระหว่างโมเดลทั้งสามได้ชัดเจนยิ่งขึ้น สามารถสรุปได้ดังตารางต่อไปนี้:
| คุณสมบัติ | Poisson Regression | Negative Binomial Regression | Zero-Inflated Poisson (ZIP) Regression |
|---|---|---|---|
| ข้อสมมติฐานหลักเกี่ยวกับความแปรปรวน | ค่าเฉลี่ย = ความแปรปรวน (Equidispersion) | ความแปรปรวน > ค่าเฉลี่ย (Overdispersion) (มี dispersion parameter) | ส่วนที่เป็น Count process มีค่าเฉลี่ย = ความแปรปรวน (Poisson part) |
| การจัดการ Overdispersion | ไม่สามารถจัดการได้โดยตรง | ออกแบบมาเพื่อจัดการโดยเฉพาะ | ไม่ได้ออกแบบมาเพื่อจัดการ overdispersion โดยตรง (แต่ ZINB ทำได้) |
| การจัดการ Excess Zeros | ไม่สามารถจัดการได้โดยตรง | ไม่ได้ออกแบบมาเพื่อจัดการโดยเฉพาะ (แต่ ZINB ทำได้) | ออกแบบมาเพื่อจัดการโดยเฉพาะ (มีส่วน zero-inflation model) |
| โครงสร้างโมเดล | ส่วนเดียว (กระบวนการนับ) | ส่วนเดียว (กระบวนการนับ, ปรับแก้ overdispersion) | สองส่วน (กระบวนการสร้างศูนย์ และกระบวนการนับ) |
| สถานการณ์ที่เหมาะสม | ข้อมูลนับที่ไม่มี overdispersion หรือ excess zeros | ข้อมูลนับที่มี overdispersion | ข้อมูลนับที่มี excess zeros อย่างชัดเจน และมีเหตุผลรองรับว่ามาจากสองกระบวนการ |
การแสดงภาพเปรียบเทียบคุณสมบัติโมเดล
เพื่อให้เห็นภาพรวมการเปรียบเทียบคุณสมบัติเด่นของแต่ละโมเดลในหลายมิติ เราสามารถใช้แผนภูมิเรดาร์ (Radar Chart) ได้ โดยแกนต่างๆ แสดงถึงคุณลักษณะที่สำคัญ เช่น ความสามารถในการจัดการกับ Overdispersion, การจัดการ Excess Zeros, ความง่ายของแบบจำลอง, ความยืดหยุ่นต่อการละเมิดข้อสมมติฐาน, และความซับซ้อนในการคำนวณ
หมายเหตุ: ค่าในแผนภูมิเรดาร์เป็นค่าเชิงคุณภาพเพื่อแสดงแนวโน้ม ไม่ใช่ค่าที่ได้จากการคำนวณทางสถิติที่แม่นยำ และได้รวม ZINB Regression เข้ามาเพื่อการเปรียบเทียบที่สมบูรณ์ยิ่งขึ้น
แผนผังความคิด: สรุปความสัมพันธ์ของโมเดล
แผนผังความคิด (Mindmap) ด้านล่างนี้จะช่วยให้คุณเห็นภาพรวมความสัมพันธ์และลักษณะเด่นของแต่ละโมเดลการถดถอยสำหรับข้อมูลนับได้ชัดเจนยิ่งขึ้น:
ค่าเฉลี่ย = ความแปรปรวน (Equidispersion)"] id1b["การใช้งาน:
ข้อมูลนับพื้นฐาน
ไม่มี overdispersion
ไม่มี excess zeros"] id1c["ข้อจำกัด:
ไวต่อ overdispersion
ไวต่อ excess zeros"] id2["Negative Binomial Regression (NBR)"] id2a["ข้อสมมติฐานหลัก:
ความแปรปรวน > ค่าเฉลี่ย (Overdispersion)"] id2b["มี Dispersion Parameter (\(\alpha\) หรือ \(k\))"] id2c["การใช้งาน:
ข้อมูลนับที่มี overdispersion"] id2d["เป็น Generalization ของ Poisson Regression"] id3["Zero-Inflated Poisson (ZIP) Regression"] id3a["ข้อสมมติฐานหลัก:
มี Excess Zeros"] id3b["โครงสร้าง 2 ส่วน:
1. Zero-inflation model (Logistic)
2. Count model (Poisson)"] id3c["การใช้งาน:
ข้อมูลนับที่มีศูนย์มากผิดปกติ
ศูนย์มาจาก 2 กระบวนการ"] id4["Zero-Inflated Negative Binomial (ZINB) Regression"] id4a["การผสมผสาน:
คุณสมบัติของ NBR + ZIP"] id4b["การใช้งาน:
ข้อมูลนับที่มีทั้ง overdispersion และ excess zeros"]
แผนผังนี้แสดงให้เห็นว่า Poisson Regression เป็นพื้นฐาน โดยมี Negative Binomial Regression เป็นส่วนขยายเพื่อจัดการกับ overdispersion และ Zero-Inflated Poisson Regression เป็นส่วนขยายเพื่อจัดการกับ excess zeros นอกจากนี้ยังมี Zero-Inflated Negative Binomial (ZINB) Regression ซึ่งรวมความสามารถของทั้ง NBR และ ZIP เข้าด้วยกัน เพื่อจัดการกับข้อมูลที่มีทั้ง overdispersion และ excess zeros พร้อมกัน
การเลือกโมเดลที่เหมาะสม
การเลือกโมเดลที่เหมาะสมที่สุดสำหรับการวิเคราะห์ข้อมูลนับของคุณนั้นขึ้นอยู่กับลักษณะของข้อมูลเป็นสำคัญ ขั้นตอนทั่วไปในการพิจารณาคือ:
- ตรวจสอบข้อมูลเบื้องต้น: สำรวจการกระจายตัวของข้อมูลนับของคุณ ดูฮิสโตแกรม คำนวณค่าเฉลี่ยและความแปรปรวน สังเกตจำนวนค่าศูนย์
- ทดสอบ Equidispersion: หากค่าความแปรปรวนใกล้เคียงกับค่าเฉลี่ย Poisson Regression อาจเป็นตัวเลือกที่ดี
- ทดสอบ Overdispersion: หากค่าความแปรปรวนสูงกว่าค่าเฉลี่ยอย่างมีนัยสำคัญ (Variance > Mean) ควรพิจารณา Negative Binomial Regression การทดสอบทางสถิติ เช่น Likelihood Ratio Test ระหว่าง Poisson และ NB model สามารถช่วยในการตัดสินใจได้
- ตรวจสอบ Excess Zeros: หากข้อมูลมีจำนวนศูนย์มากกว่าที่คาดการณ์จากการกระจายแบบ Poisson หรือ Negative Binomial อย่างชัดเจน ควรพิจารณา Zero-Inflated Model (ZIP หรือ ZINB) การทดสอบ Vuong test สามารถใช้เปรียบเทียบระหว่างโมเดล non-nested เช่น Poisson กับ ZIP หรือ NB กับ ZINB
- พิจารณาบริบทของปัญหา: มีเหตุผลทางทฤษฎีที่สนับสนุนว่าค่าศูนย์มาจากสองกระบวนการที่แตกต่างกันหรือไม่? ถ้าใช่ ZIP หรือ ZINB อาจเหมาะสมกว่า
- ประเมินความพอดีของโมเดล (Goodness-of-fit): หลังจากเลือกโมเดลแล้ว ควรประเมินว่าโมเดลนั้นเหมาะสมกับข้อมูลเพียงใดโดยใช้สถิติต่างๆ เช่น Deviance, Pearson Chi-squared, AIC, BIC หรือการพิจารณา Residuals
วิดีโอนี้อธิบายเกี่ยวกับ Regression with Count Data โดยครอบคลุม Poisson และ Negative Binomial Regression รวมถึงประเด็นเรื่อง Overdispersion ซึ่งเป็นประโยชน์ในการทำความเข้าใจการเลือกใช้โมเดลเหล่านี้
การเลือกโมเดลไม่ใช่เรื่องตายตัวเสมอไป บางครั้งอาจต้องลองหลายโมเดลและเปรียบเทียบผลลัพธ์เพื่อให้ได้โมเดลที่อธิบายข้อมูลได้ดีที่สุดและสอดคล้องกับทฤษฎีที่เกี่ยวข้อง
คำถามที่พบบ่อย (FAQ)
คำแนะนำสำหรับการค้นคว้าเพิ่มเติม
- วิธีการทดสอบ overdispersion และ excess zeros ในข้อมูลนับอย่างละเอียดควรทำอย่างไร?
- มีตัวอย่างการประยุกต์ใช้ Poisson, Negative Binomial และ ZIP regression ในงานวิจัยด้านสาธารณสุขอย่างไรบ้าง?
- การตีความค่าสัมประสิทธิ์ (coefficients) ในโมเดล Poisson, Negative Binomial และ ZIP regression แตกต่างกันอย่างไร?
- โมเดล Zero-Inflated กับ Hurdle models แตกต่างกันอย่างไรในการวิเคราะห์ข้อมูลนับ?
แหล่งอ้างอิง
- Poisson regression - Wikipedia
- Negative binomial distribution - Wikipedia
- Zero-inflated model - Wikipedia
- Getting Started with Negative Binomial Regression Modeling - University of Virginia Library
- Negative Binomial Regression | R Data Analysis Examples - UCLA IDRE Stats
- Zero-Inflated Poisson Regression | R Data Analysis Examples - UCLA IDRE Stats
- The Negative Binomial Regression Model - TimeseriesReasoning.com
- Improved estimation in Negative Binomial Regression - PMC NCBI
ไขความลับโมเดลข้อมูลนับ: Poisson, ZIP, และ Negative Binomial Regression แตกต่างกันอย่างไร?
เจาะลึก 3 โมเดลการถดถอยยอดนิยมสำหรับวิเคราะห์ข้อมูลจำนวนนับ พร้อมเลือกใช้ให้เหมาะกับงานของคุณ
ในโลกของการวิเคราะห์ข้อมูล การทำความเข้าใจลักษณะเฉพาะของข้อมูลที่เรากำลังทำงานด้วยเป็นสิ่งสำคัญอย่างยิ่ง โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับ "ข้อมูลนับ" (count data) ซึ่งหมายถึงข้อมูลที่แสดงจำนวนครั้งของการเกิดเหตุการณ์ต่างๆ เช่น จำนวนลูกค้าที่เข้าร้านต่อวัน จำนวนข้อบกพร่องในผลิตภัณฑ์ หรือจำนวนการคลิกโฆษณา โมเดลการถดถอยทั่วไปอาจไม่เหมาะสมกับข้อมูลประเภทนี้เสมอไป วันนี้เราจะมาทำความรู้จักกับ 3 โมเดลการถดถอยที่ถูกออกแบบมาสำหรับข้อมูลนับโดยเฉพาะ ได้แก่ Poisson Regression, Zero-Inflated Poisson (ZIP) Regression และ Negative Binomial Regression พร้อมทั้งเปรียบเทียบความแตกต่างและแนวทางการเลือกใช้งานอย่างละเอียด
ไฮไลท์สำคัญ: สรุปประเด็นหลักที่คุณควรรู้
- Poisson Regression: เหมาะสำหรับข้อมูลนับพื้นฐานที่ค่าเฉลี่ยและความแปรปรวนมีค่าเท่ากัน (equidispersion) และไม่มีจำนวนศูนย์มากผิดปกติ
- Negative Binomial Regression: เป็นตัวเลือกที่ดีเมื่อข้อมูลนับของคุณแสดงลักษณะ "overdispersion" คือมีความแปรปรวนสูงกว่าค่าเฉลี่ย
- Zero-Inflated Poisson (ZIP) Regression: ออกแบบมาเพื่อจัดการกับข้อมูลที่มี "excess zeros" หรือจำนวนค่าศูนย์ที่สังเกตได้มีมากกว่าที่คาดการณ์ไว้โดยโมเดล Poisson มาตรฐาน
ทำความรู้จักแต่ละโมเดลอย่างละเอียด
การเลือกโมเดลที่เหมาะสมขึ้นอยู่กับความเข้าใจในข้อสมมติฐานและลักษณะเฉพาะของแต่ละโมเดล เรามาเจาะลึกรายละเอียดของแต่ละโมเดลกันครับ
1. Poisson Regression: พื้นฐานของข้อมูลนับ
Poisson Regression เป็นรูปแบบหนึ่งของ Generalized Linear Model (GLM) ที่ใช้ในการสร้างแบบจำลองความสัมพันธ์ระหว่างตัวแปรตาม (dependent variable) ที่เป็นข้อมูลนับ กับชุดของตัวแปรอิสระ (independent variables)
ภาพตัวอย่างกราฟที่แสดงการกระจายของข้อมูลที่อาจเหมาะสมกับ Poisson Regression
ข้อสมมติฐานหลัก
ข้อสมมติฐานที่สำคัญที่สุดของ Poisson Regression คือ ค่าเฉลี่ย (mean) ของข้อมูลนับจะเท่ากับค่าความแปรปรวน (variance) ของมัน หรือที่เรียกว่า "equidispersion" เขียนเป็นสมการได้ว่า:
\[ E(Y_i) = \lambda_i \]
\[ \text{Var}(Y_i) = \lambda_i \]
โดยที่ \( Y_i \) คือจำนวนนับที่สังเกตได้ และ \( \lambda_i \) คืออัตราการเกิดเหตุการณ์เฉลี่ยสำหรับ observation ที่ \( i \)
โมเดลนี้จะเชื่อมโยงอัตราการเกิดเหตุการณ์ \( \lambda_i \) กับตัวแปรอิสระ \( X \) ผ่านฟังก์ชัน log link:
\[ \ln(\lambda_i) = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \dots + \beta_p X_{pi} \]
การใช้งานและข้อจำกัด
Poisson Regression เหมาะสำหรับข้อมูลที่จำนวนเหตุการณ์เกิดขึ้นอย่างสุ่มและเป็นอิสระต่อกันในช่วงเวลาหรือพื้นที่ที่กำหนด และอัตราการเกิดคงที่ ตัวอย่างเช่น จำนวนอีเมลที่ได้รับต่อชั่วโมง หรือจำนวนลูกค้าที่โทรเข้ามายังศูนย์บริการต่อวัน
ข้อจำกัด:
- Overdispersion: หากข้อมูลจริงมีความแปรปรวนมากกว่าค่าเฉลี่ย (Variance > Mean) การใช้ Poisson Regression อาจนำไปสู่การประมาณค่า standard errors ที่ต่ำเกินไป ทำให้สรุปผลผิดพลาดได้ (เช่น พบว่าตัวแปรมีนัยสำคัญทั้งที่จริงแล้วไม่มี)
- Underdispersion: ในทางกลับกัน หากความแปรปรวนน้อยกว่าค่าเฉลี่ย (Variance < Mean) ก็เป็นปัญหาเช่นกัน แม้จะพบได้น้อยกว่า
- Excess Zeros: ถ้าข้อมูลมีจำนวนค่าศูนย์ (0) มากเกินกว่าที่การกระจายแบบ Poisson คาดการณ์ไว้ โมเดลนี้อาจไม่เหมาะสม
2. Negative Binomial Regression: รับมือกับ Overdispersion
Negative Binomial Regression (NBR) เป็นอีกทางเลือกหนึ่งสำหรับข้อมูลนับ และมักถูกใช้เมื่อข้อมูลแสดงลักษณะ "overdispersion" อย่างชัดเจน NBR เป็นการขยายแนวคิดของ Poisson Regression โดยเพิ่มพารามิเตอร์ที่เรียกว่า "dispersion parameter" (มักแทนด้วย \( \alpha \) หรือ \( k \)) เข้ามาเพื่อจัดการกับความแปรปรวนส่วนเกิน
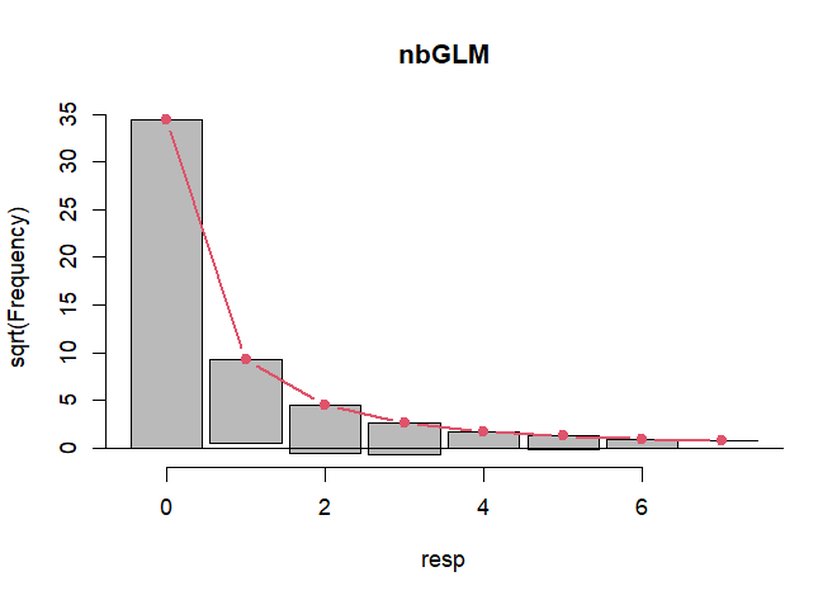
Rootogram เปรียบเทียบความถี่ที่สังเกตได้กับความถี่ที่คาดการณ์โดยโมเดล Negative Binomial ซึ่งช่วยประเมินความพอดีของโมเดลกับข้อมูลที่มี overdispersion
ข้อสมมติฐานและความสัมพันธ์กับ Poisson
ใน Negative Binomial Regression ความสัมพันธ์ระหว่างค่าเฉลี่ยและความแปรปรวนจะเป็นดังนี้:
\[ \text{Var}(Y_i) = \mu_i + \alpha \mu_i^2 \]
หรือในบางตำราอาจเขียนเป็น:
\[ \text{Var}(Y_i) = \mu_i (1 + \alpha \mu_i) \]
หรือ
\[ \text{Var}(Y_i) = \mu_i + \frac{\mu_i^2}{k} \]
โดย \( \mu_i \) คือค่าเฉลี่ย และ \( \alpha \) (หรือ \( 1/k \)) คือ dispersion parameter ที่แสดงระดับของ overdispersion
- ถ้า \( \alpha = 0 \) (หรือ \( k \to \infty \)), Negative Binomial Regression จะลดรูปกลายเป็น Poisson Regression ซึ่งหมายความว่า Poisson Regression เป็นกรณีพิเศษของ Negative Binomial Regression
- ถ้า \( \alpha > 0 \), แสดงว่ามี overdispersion (Variance > Mean)
การใช้งาน
NBR เหมาะสำหรับข้อมูลนับที่ความแปรปรวนมีค่าสูงกว่าค่าเฉลี่ยอย่างมีนัยสำคัญ เช่น จำนวนครั้งที่นักเรียนขาดเรียน (บางคนอาจไม่เคยขาด บางคนอาจขาดบ่อยมาก) หรือจำนวนปรสิตในโฮสต์ (การกระจายตัวของปรสิตมักไม่สม่ำเสมอ) การใช้ NBR ในสถานการณ์เหล่านี้จะให้ค่า standard errors และ p-values ที่น่าเชื่อถือกว่า Poisson Regression
3. Zero-Inflated Poisson (ZIP) Regression: จัดการกับ "Excess Zeros"
Zero-Inflated Poisson (ZIP) Regression เป็นโมเดลที่ออกแบบมาเพื่อจัดการกับข้อมูลนับที่มีจำนวนค่าศูนย์ (zeros) มากเกินไปกว่าที่โมเดล Poisson มาตรฐานจะคาดการณ์ได้ (เรียกว่า "excess zeros" หรือ "zero inflation") โมเดล ZIP สันนิษฐานว่าค่าศูนย์ที่สังเกตได้นั้นมาจากสองกระบวนการที่แตกต่างกัน:
- กระบวนการสร้างศูนย์ (Zero-generating process): ส่วนนี้จะทำนายว่าผลลัพธ์จะเป็น "ศูนย์แท้" (true zero) หรือไม่ ซึ่งหมายถึงกลุ่มที่ไม่สามารถเกิดเหตุการณ์ได้เลย หรือมีโอกาสเกิดเหตุการณ์เป็นศูนย์เสมอด้วยเหตุผลบางอย่าง ส่วนนี้มักจะใช้โมเดลโลจิสติก (Logistic Regression) เพื่อทำนายความน่าจะเป็น \( \pi_i \) ที่ observation \( i \) จะมาจากกลุ่ม "ศูนย์แท้"
- กระบวนการนับ (Count process): ส่วนนี้จะทำนายจำนวนนับสำหรับกลุ่มที่ "ไม่ใช่ศูนย์แท้" (สามารถเกิดเหตุการณ์ได้) ซึ่งจะตามการกระจายแบบ Poisson ด้วยค่าเฉลี่ย \( \lambda_i \)
ดังนั้น ความน่าจะเป็นที่จะสังเกตเห็นค่าศูนย์ \( P(Y_i=0) \) ในโมเดล ZIP คือ:
\[ P(Y_i=0) = \pi_i + (1-\pi_i)e^{-\lambda_i} \]
และความน่าจะเป็นที่จะสังเกตเห็นค่าที่ไม่ใช่ศูนย์ \( k > 0 \) คือ:
\[ P(Y_i=k) = (1-\pi_i) \frac{e^{-\lambda_i}\lambda_i^k}{k!} \quad \text{for } k > 0 \]
การใช้งาน
ZIP Regression เหมาะสมเมื่อมีเหตุผลทางทฤษฎีที่เชื่อได้ว่ามีสองกลุ่มประชากรที่แตกต่างกันในการสร้างข้อมูลศูนย์ ตัวอย่างเช่น:
- จำนวนบุหรี่ที่สูบต่อวัน: กลุ่มหนึ่งคือผู้ที่ไม่เคยสูบบุหรี่ (ศูนย์แท้) และอีกกลุ่มคือผู้ที่สูบบุหรี่ (อาจสูบ 0 มวนในวันนั้น หรือมากกว่านั้น)
- จำนวนปลาที่จับได้ในแต่ละครั้งที่ออกเรือ: บางครั้งอาจจะไม่ได้ปลาเลยเพราะสภาพอากาศไม่อำนวย (ปัจจัยที่ทำให้เป็นศูนย์แท้) หรือบางครั้งไม่ได้ปลาเพราะโชคไม่ดี (ปัจจัยในกระบวนการนับ)
หมายเหตุ: หากข้อมูลมีทั้ง overdispersion และ excess zeros อาจต้องพิจารณาโมเดลที่ซับซ้อนขึ้น เช่น Zero-Inflated Negative Binomial (ZINB) Regression ซึ่งรวมคุณสมบัติของ NBR (จัดการ overdispersion) และ ZIP (จัดการ excess zeros) เข้าด้วยกัน
ตารางเปรียบเทียบความแตกต่างที่สำคัญ
เพื่อให้เห็นภาพรวมความแตกต่างระหว่างโมเดลทั้งสามได้ชัดเจนยิ่งขึ้น สามารถสรุปได้ดังตารางต่อไปนี้:
| คุณสมบัติ | Poisson Regression | Negative Binomial Regression | Zero-Inflated Poisson (ZIP) Regression |
|---|---|---|---|
| ข้อสมมติฐานหลักเกี่ยวกับความแปรปรวน | ค่าเฉลี่ย = ความแปรปรวน (Equidispersion) | ความแปรปรวน > ค่าเฉลี่ย (Overdispersion) (มี dispersion parameter) | ส่วนที่เป็น Count process มีค่าเฉลี่ย = ความแปรปรวน (Poisson part) |
| การจัดการ Overdispersion | ไม่สามารถจัดการได้โดยตรง | ออกแบบมาเพื่อจัดการโดยเฉพาะ | ไม่ได้ออกแบบมาเพื่อจัดการ overdispersion โดยตรง (แต่ ZINB ทำได้) |
| การจัดการ Excess Zeros | ไม่สามารถจัดการได้โดยตรง | ไม่ได้ออกแบบมาเพื่อจัดการโดยเฉพาะ (แต่ ZINB ทำได้) | ออกแบบมาเพื่อจัดการโดยเฉพาะ (มีส่วน zero-inflation model) |
| โครงสร้างโมเดล | ส่วนเดียว (กระบวนการนับ) | ส่วนเดียว (กระบวนการนับ, ปรับแก้ overdispersion) | สองส่วน (กระบวนการสร้างศูนย์ และกระบวนการนับ) |
| สถานการณ์ที่เหมาะสม | ข้อมูลนับที่ไม่มี overdispersion หรือ excess zeros | ข้อมูลนับที่มี overdispersion | ข้อมูลนับที่มี excess zeros อย่างชัดเจน และมีเหตุผลรองรับว่ามาจากสองกระบวนการ |
การแสดงภาพเปรียบเทียบคุณสมบัติโมเดล
เพื่อให้เห็นภาพรวมการเปรียบเทียบคุณสมบัติเด่นของแต่ละโมเดลในหลายมิติ เราสามารถใช้แผนภูมิเรดาร์ (Radar Chart) ได้ โดยแกนต่างๆ แสดงถึงคุณลักษณะที่สำคัญ เช่น ความสามารถในการจัดการกับ Overdispersion, การจัดการ Excess Zeros, ความง่ายของแบบจำลอง, ความยืดหยุ่นต่อการละเมิดข้อสมมติฐาน, และความซับซ้อนในการคำนวณ
หมายเหตุ: ค่าในแผนภูมิเรดาร์เป็นค่าเชิงคุณภาพเพื่อแสดงแนวโน้ม ไม่ใช่ค่าที่ได้จากการคำนวณทางสถิติที่แม่นยำ และได้รวม ZINB Regression เข้ามาเพื่อการเปรียบเทียบที่สมบูรณ์ยิ่งขึ้น
แผนผังความคิด: สรุปความสัมพันธ์ของโมเดล
แผนผังความคิด (Mindmap) ด้านล่างนี้จะช่วยให้คุณเห็นภาพรวมความสัมพันธ์และลักษณะเด่นของแต่ละโมเดลการถดถอยสำหรับข้อมูลนับได้ชัดเจนยิ่งขึ้น:
ค่าเฉลี่ย = ความแปรปรวน (Equidispersion)"] id1b["การใช้งาน:
ข้อมูลนับพื้นฐาน
ไม่มี overdispersion
ไม่มี excess zeros"] id1c["ข้อจำกัด:
ไวต่อ overdispersion
ไวต่อ excess zeros"] id2["Negative Binomial Regression (NBR)"] id2a["ข้อสมมติฐานหลัก:
ความแปรปรวน > ค่าเฉลี่ย (Overdispersion)"] id2b["มี Dispersion Parameter (\(\alpha\) หรือ \(k\))"] id2c["การใช้งาน:
ข้อมูลนับที่มี overdispersion"] id2d["เป็น Generalization ของ Poisson Regression"] id3["Zero-Inflated Poisson (ZIP) Regression"] id3a["ข้อสมมติฐานหลัก:
มี Excess Zeros"] id3b["โครงสร้าง 2 ส่วน:
1. Zero-inflation model (Logistic)
2. Count model (Poisson)"] id3c["การใช้งาน:
ข้อมูลนับที่มีศูนย์มากผิดปกติ
ศูนย์มาจาก 2 กระบวนการ"] id4["Zero-Inflated Negative Binomial (ZINB) Regression"] id4a["การผสมผสาน:
คุณสมบัติของ NBR + ZIP"] id4b["การใช้งาน:
ข้อมูลนับที่มีทั้ง overdispersion และ excess zeros"]
แผนผังนี้แสดงให้เห็นว่า Poisson Regression เป็นพื้นฐาน โดยมี Negative Binomial Regression เป็นส่วนขยายเพื่อจัดการกับ overdispersion และ Zero-Inflated Poisson Regression เป็นส่วนขยายเพื่อจัดการกับ excess zeros นอกจากนี้ยังมี Zero-Inflated Negative Binomial (ZINB) Regression ซึ่งรวมความสามารถของทั้ง NBR และ ZIP เข้าด้วยกัน เพื่อจัดการกับข้อมูลที่มีทั้ง overdispersion และ excess zeros พร้อมกัน
การเลือกโมเดลที่เหมาะสม
การเลือกโมเดลที่เหมาะสมที่สุดสำหรับการวิเคราะห์ข้อมูลนับของคุณนั้นขึ้นอยู่กับลักษณะของข้อมูลเป็นสำคัญ ขั้นตอนทั่วไปในการพิจารณาคือ:
- ตรวจสอบข้อมูลเบื้องต้น: สำรวจการกระจายตัวของข้อมูลนับของคุณ ดูฮิสโตแกรม คำนวณค่าเฉลี่ยและความแปรปรวน สังเกตจำนวนค่าศูนย์
- ทดสอบ Equidispersion: หากค่าความแปรปรวนใกล้เคียงกับค่าเฉลี่ย Poisson Regression อาจเป็นตัวเลือกที่ดี
- ทดสอบ Overdispersion: หากค่าความแปรปรวนสูงกว่าค่าเฉลี่ยอย่างมีนัยสำคัญ (Variance > Mean) ควรพิจารณา Negative Binomial Regression การทดสอบทางสถิติ เช่น Likelihood Ratio Test ระหว่าง Poisson และ NB model สามารถช่วยในการตัดสินใจได้
- ตรวจสอบ Excess Zeros: หากข้อมูลมีจำนวนศูนย์มากกว่าที่คาดการณ์จากการกระจายแบบ Poisson หรือ Negative Binomial อย่างชัดเจน ควรพิจารณา Zero-Inflated Model (ZIP หรือ ZINB) การทดสอบ Vuong test สามารถใช้เปรียบเทียบระหว่างโมเดล non-nested เช่น Poisson กับ ZIP หรือ NB กับ ZINB
- พิจารณาบริบทของปัญหา: มีเหตุผลทางทฤษฎีที่สนับสนุนว่าค่าศูนย์มาจากสองกระบวนการที่แตกต่างกันหรือไม่? ถ้าใช่ ZIP หรือ ZINB อาจเหมาะสมกว่า
- ประเมินความพอดีของโมเดล (Goodness-of-fit): หลังจากเลือกโมเดลแล้ว ควรประเมินว่าโมเดลนั้นเหมาะสมกับข้อมูลเพียงใดโดยใช้สถิติต่างๆ เช่น Deviance, Pearson Chi-squared, AIC, BIC หรือการพิจารณา Residuals
วิดีโอนี้อธิบายเกี่ยวกับ Regression with Count Data โดยครอบคลุม Poisson และ Negative Binomial Regression รวมถึงประเด็นเรื่อง Overdispersion ซึ่งเป็นประโยชน์ในการทำความเข้าใจการเลือกใช้โมเดลเหล่านี้
การเลือกโมเดลไม่ใช่เรื่องตายตัวเสมอไป บางครั้งอาจต้องลองหลายโมเดลและเปรียบเทียบผลลัพธ์เพื่อให้ได้โมเดลที่อธิบายข้อมูลได้ดีที่สุดและสอดคล้องกับทฤษฎีที่เกี่ยวข้อง
คำถามที่พบบ่อย (FAQ)
คำแนะนำสำหรับการค้นคว้าเพิ่มเติม
- วิธีการทดสอบ overdispersion และ excess zeros ในข้อมูลนับอย่างละเอียดควรทำอย่างไร?
- มีตัวอย่างการประยุกต์ใช้ Poisson, Negative Binomial และ ZIP regression ในงานวิจัยด้านสาธารณสุขอย่างไรบ้าง?
- การตีความค่าสัมประสิทธิ์ (coefficients) ในโมเดล Poisson, Negative Binomial และ ZIP regression แตกต่างกันอย่างไร?
- โมเดล Zero-Inflated กับ Hurdle models แตกต่างกันอย่างไรในการวิเคราะห์ข้อมูลนับ?
แหล่งอ้างอิง
Last updated May 14, 2025