
Beyond Cutting: How Base Editing Rewrites the Genetic Code One Letter at a Time
Discover the revolutionary technology that precisely changes DNA without double-strand breaks, offering new hope for genetic diseases.
Highlights
- Precision Point Mutations: Base editing chemically converts single DNA letters (bases) directly at targeted locations without cutting the DNA backbone.
- No Double-Strand Breaks (DSBs): Unlike traditional CRISPR-Cas9, base editing avoids DSBs, significantly reducing the risk of unwanted insertions, deletions (indels), and larger chromosomal rearrangements.
- Targeted Chemical Action: It uses a fusion protein combining a DNA-targeting module (like a modified Cas protein) and a deaminase enzyme to perform specific base conversions (e.g., C to T or A to G).
What is Base Editing? A New Chapter in Genome Modification
Moving Beyond Scissors to Chemical Pens
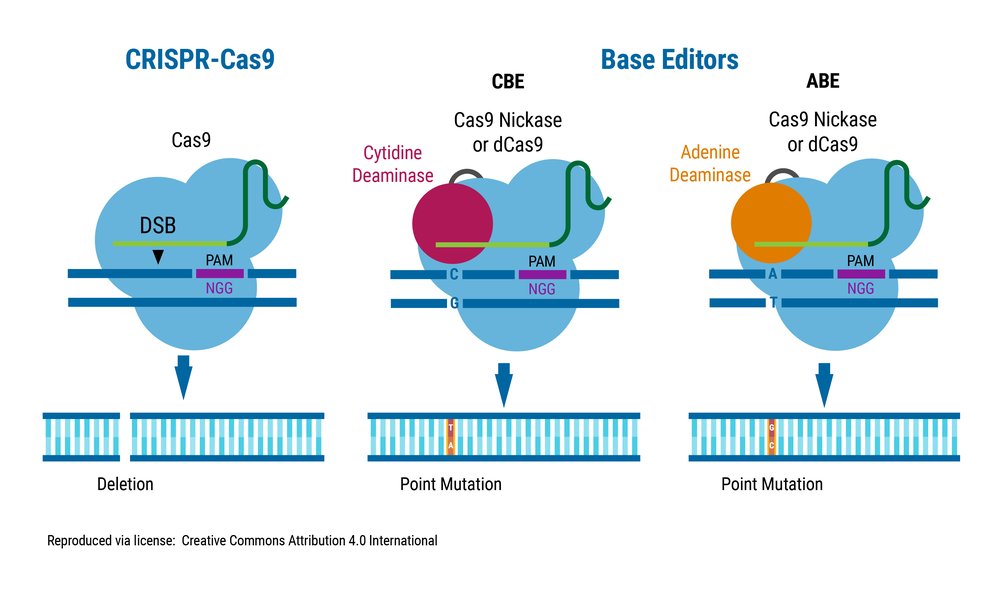
Base editing represents a groundbreaking advancement in the field of genome engineering. It is a sophisticated technology designed to make highly precise changes to the genome by directly altering a single DNA base – one chemical "letter" in the genetic code – without making a cut across both strands of the DNA helix. This marks a significant departure from earlier genome editing techniques like standard CRISPR-Cas9, ZFNs (Zinc Finger Nucleases), and TALENs (Transcription Activator-Like Effector Nucleases). These traditional methods function primarily by inducing double-strand breaks (DSBs) at specific genomic locations. While effective for gene disruption or integrating new genetic material via homology-directed repair (HDR), relying on DSBs also harnesses the cell's natural, but sometimes error-prone, repair pathways, particularly non-homologous end joining (NHEJ). NHEJ can frequently introduce unintended insertions or deletions (indels) at the target site, potentially disrupting gene function in unpredictable ways.

Conceptual illustration representing the precise modification of DNA sequences.
Base editing circumvents the need for DSBs altogether. Instead, it employs a more refined, "chemical surgery" approach. By combining the targeting precision of CRISPR systems with the enzymatic activity of a deaminase, base editors can directly convert one nucleotide base into another at the desired location. This capability is particularly powerful for correcting pathogenic single nucleotide polymorphisms (SNPs) – variations in a single DNA base – which are responsible for a vast number of human genetic disorders. The ability to make these precise C•G-to-T•A or A•T-to-G•C changes efficiently and with fewer unintended consequences positions base editing as a potentially safer and more effective tool for therapeutic applications.
The Core Machinery: How Base Editors Work
Dissecting the Components and Mechanism
The elegance of base editing lies in its cleverly engineered molecular machinery. A typical base editor is a fusion protein constructed from several key components, each playing a critical role:
Targeting Module: The Guide System
At the heart of the targeting system is a modified CRISPR-Cas protein. Commonly, this is a version of Cas9 that has been enzymatically "deadened" (dCas9) or engineered to only nick one strand of the DNA (nickase Cas9, nCas9). Unlike wild-type Cas9 used in traditional CRISPR editing, dCas9 or nCas9 retains its ability to bind to specific DNA sequences but cannot create DSBs. This Cas variant is programmed with a single guide RNA (sgRNA), which contains a sequence complementary to the desired target site in the genome. The sgRNA directs the entire base editor complex to the precise genomic locus.
DNA Binding and Unwinding: Creating Access
Once guided to the target site, the Cas protein binds to the DNA sequence adjacent to a specific short motif known as the Protospacer Adjacent Motif (PAM). This binding event causes the local DNA double helix to unwind, forming a structure called an R-loop. In the R-loop, the sgRNA pairs with its complementary DNA strand, displacing the other DNA strand and making it temporarily single-stranded and accessible to the deaminase enzyme.

An early electron microscope image showing the structure of DNA strands.
The Chemical Engine: The Deaminase Enzyme
Fused to the Cas protein is the deaminase enzyme, the workhorse of base editing. This enzyme is responsible for the chemical conversion of the target base. It acts specifically on the exposed single-stranded DNA within the R-loop. The type of deaminase determines the type of base conversion that occurs.
The Editing Window: Defining the Action Zone
The deaminase doesn't act randomly along the exposed strand. Its activity is typically restricted to a specific "editing window" – usually a stretch of 4 to 8 nucleotides located a certain distance upstream from the PAM sequence recognised by the Cas protein. Any target base falling within this window can potentially be modified. The precise location and size of this window depend on the specific base editor architecture.
Base Conversion and Repair: Finalizing the Edit
The deaminase chemically modifies the target base (e.g., C to U or A to I). This altered base creates a mismatch with the base on the complementary strand. The cell's natural DNA repair machinery then steps in to resolve this mismatch. To encourage the cell to use the edited strand as the template for repair, many base editors incorporate a nickase function (nCas9) to cut the *non-edited* strand opposite the modified base. This nick prompts the cell to preferentially use repair pathways like Base Excision Repair (BER) or Mismatch Repair (MMR), which remove the original base on the nicked strand and replace it with the base complementary to the edited base (e.g., replacing G opposite the newly formed U with an A, resulting in a stable T:A pair after replication). This process efficiently installs the desired point mutation without generating DSBs and the associated indel risk.
Visualizing the Base Editing Process
The following diagram illustrates the key steps and components involved in the base editing process, from target recognition to the final precise base conversion.
Meet the Editors: CBEs and ABEs
The Two Main Classes of Base Rewriters
The versatility of base editing stems largely from the development of two primary classes of editors, distinguished by the type of base they target and convert:
Cytosine Base Editors (CBEs): The C-to-T Specialists
CBEs are designed to convert a cytosine (C) base into a thymine (T) base within the target DNA sequence. This ultimately results in the conversion of a C•G base pair to a T•A base pair.
- Mechanism: CBEs typically utilize a cytosine deaminase enzyme, such as APOBEC1 (from rat) or variants thereof. This enzyme catalyzes the removal of an amino group from cytosine (deamination), transforming it into uracil (U).
- Resolution: Uracil is not a standard DNA base and is recognized by cellular machinery as being similar to thymine. During DNA replication or repair, the cell incorporates an adenine (A) opposite the uracil. Furthermore, some CBEs include a Uracil Glycosylase Inhibitor (UGI) component. UGI prevents cellular enzymes from removing the uracil before it can be permanently converted to thymine during replication, thereby increasing editing efficiency.
- Outcome: The net result is a clean C•G → T•A transition mutation at the targeted site.
Adenine Base Editors (ABEs): The A-to-G Specialists
ABEs perform the complementary conversion, changing an adenine (A) base into a guanine (G) base. This leads to the conversion of an A•T base pair to a G•C base pair.
- Mechanism: ABEs employ an engineered adenine deaminase. Creating an effective adenine deaminase for DNA was a significant challenge, eventually overcome by evolving a bacterial tRNA deaminase (TadA). ABEs, like the highly efficient ABE8e variant, use these engineered TadA enzymes. The enzyme chemically converts adenine (A) into inosine (I).
- Resolution: Inosine (I) is structurally similar to guanine (G) and is recognized as guanine by the cell's DNA polymerase during replication. Consequently, the polymerase inserts a cytosine (C) opposite the inosine.
- Outcome: This process effectively establishes an A•T → G•C transition mutation at the desired locus.
Schematic showing the targeted action of a base editor complex on DNA.
Expanding the Toolbox
While CBEs and ABEs handle the four possible transition mutations (pyrimidine to pyrimidine, C->T; purine to purine, A->G), research is actively pushing the boundaries. Scientists are developing novel base editors capable of performing transversions (purine to pyrimidine or vice versa, e.g., C->G), dual-base editors, and even RNA base editors that modify RNA molecules instead of DNA. Furthermore, specialized editors are being created to target mitochondrial DNA, which was previously difficult to edit precisely.
CBE vs. ABE: A Comparative Overview
The following table summarizes the key distinctions between the two main types of DNA base editors:
| Feature | Cytosine Base Editor (CBE) | Adenine Base Editor (ABE) |
|---|---|---|
| Target Base | Cytosine (C) | Adenine (A) |
| Deaminase Enzyme Family | Cytidine Deaminases (e.g., APOBEC, CDA) | Engineered Adenine Deaminases (e.g., TadA variants) |
| Chemical Conversion | Cytosine (C) → Uracil (U) | Adenine (A) → Inosine (I) |
| Cellular Interpretation | Uracil (U) read as Thymine (T) | Inosine (I) read as Guanine (G) |
| Resulting Base Pair Change | C•G → T•A | A•T → G•C |
| Primary Application | Correcting G•C → A•T mutations | Correcting A•T → G•C mutations |
| Auxiliary Component Example | Uracil Glycosylase Inhibitor (UGI) often included | Engineered deaminase dimer common |
Advantages Over Traditional CRISPR
Why Precision Matters
Base editing offers several compelling advantages compared to traditional DSB-inducing genome editing methods:
- Enhanced Precision for Point Mutations: Base editors excel at introducing specific single-base changes with high efficiency.
- Reduced Indel Formation: By avoiding DSBs, base editing drastically minimizes the formation of unwanted insertions and deletions (indels) that commonly arise from error-prone NHEJ repair of DSBs. This significantly increases the safety profile, especially for therapeutic applications.
- No Requirement for Donor DNA Templates: Unlike HDR, which requires a DNA template to make precise changes after a DSB, base editing directly modifies the existing base, simplifying the editing process.
- Efficiency in Non-dividing Cells: Base editing relies on repair pathways active in both dividing and non-dividing cells (like neurons or muscle cells), whereas HDR (needed for precise edits with traditional CRISPR) is most active in dividing cells. This broadens the range of tissues and cell types amenable to precise editing.
- Lower Cytotoxicity: DSBs can be toxic to cells and can lead to large deletions or chromosomal rearrangements. Avoiding DSBs makes base editing generally less toxic.
Comparing Base Editing and CRISPR-Cas9
This chart provides a comparative overview of key features between base editing and traditional CRISPR-Cas9 editing, highlighting their distinct characteristics and suitability for different applications. Note that these are generalized comparisons and performance can vary based on specific editor versions and experimental conditions.
Challenges and Future Directions
Navigating the Limitations
Despite its power, base editing technology faces certain limitations and challenges that researchers are actively working to overcome:
- Editing Window Constraints: The requirement for the target base to fall within a specific editing window limits the number of sites that can be precisely targeted.
- Bystander Edits: If multiple editable bases (e.g., multiple Cs for a CBE) exist within the editing window, the deaminase may modify them all, leading to unintended "bystander" mutations near the target site.
- Off-Target Edits: Although generally lower than with DSB-based methods, base editors can still bind to and modify unintended sites elsewhere in the genome (off-target effects), potentially causing harmful mutations. Continuous engineering efforts focus on improving the specificity of both the Cas protein and the deaminase.
- PAM Dependence: Like standard CRISPR-Cas9, base editors typically require a specific PAM sequence near the target site, restricting the accessible portions of the genome. However, engineered Cas variants with altered or relaxed PAM requirements are expanding the targeting scope.
- Limited Conversion Types: Standard CBEs and ABEs primarily mediate transition mutations. Achieving transversion mutations efficiently remains a challenge, although progress is being made with newer editor designs.
- Delivery Methods: Efficient and safe delivery of the large base editor machinery (protein or its coding sequence) into target cells or tissues in vivo remains a significant hurdle for therapeutic applications.
Ongoing research focuses on refining base editing tools for greater precision and broader applicability.
Future research is focused on developing base editors with higher fidelity, reduced off-target activity, broader targeting range (e.g., PAM-less editors), expanded editing capabilities (transversions), and improved delivery systems. Overcoming these challenges will be crucial for realizing the full therapeutic potential of base editing for treating genetic diseases.
Applications: From Lab Bench to Potential Therapies
Rewriting the Future of Medicine and Biology
The precision offered by base editing opens up exciting possibilities across various fields:
- Treating Genetic Diseases: Base editing holds immense promise for correcting pathogenic point mutations responsible for inherited disorders like cystic fibrosis, sickle cell anemia, progeria, Huntington's disease (potentially by introducing stop codons), and certain metabolic diseases. Clinical trials using base editing approaches are underway for conditions like high cholesterol.
- Functional Genomics Research: Scientists can use base editors to precisely introduce or correct specific mutations in cell lines or animal models to study gene function and model human diseases with greater accuracy.
- Drug Discovery and Development: Base editing can be used to create cell models with specific mutations to test drug efficacy or to identify genes involved in drug resistance.
- Agriculture and Biotechnology: Base editing can accelerate crop improvement by introducing desirable traits like disease resistance, drought tolerance, or enhanced nutritional value with high precision and without introducing foreign DNA, potentially streamlining regulatory pathways compared to traditional GMOs.
Explainer Video: Base Editing Fundamentals
For a visual explanation of how base editing works, this video from Boston Children's Hospital provides a clear and concise overview of the technology's core principles and potential applications in treating genetic conditions.
Frequently Asked Questions (FAQ)
How is base editing different from traditional CRISPR-Cas9?
What are the main types of base editors?
What diseases could potentially be treated with base editing?
What are the main risks or limitations of base editing?
References
- Explainer: What Are Base Editors and How Do They Work? - CRISPR Medicine News
- Base editing: What is it and what does it mean for healthcare? - Genomics Education Programme
-
Base editing: a brief review and a practical example - PMC NCBI
- Base Editing - Beam Therapeutics
- Novel CRISPR-derived ‘base editors’ surgically alter DNA or RNA, offering new ways to fix mutations - Science
- Guidelines for Base Editing in Mammalian Cells - Benchling
- Genome Editing Techniques: The Tools That Enable Scientists to Engineer DNA - Synthego
Recommended
Last updated April 20, 2025