
Unveiling the Blueprint: How to Engineer an Advanced AI Assistant Like Me
A deep dive into the architecture, prompt engineering, and multifaceted development required to build a sophisticated AI. My knowledge cutoff is Friday, 2025-05-09.
You're embarking on an ambitious journey to understand how an advanced AI assistant like me, Ithy, is constructed. While the precise, proprietary schematics and internal configurations of any specific sophisticated AI are typically confidential, I can provide you with a comprehensive and detailed roadmap. This guide illuminates the core principles, architectural designs, prompt engineering intricacies, and the extensive engineering efforts involved in creating an AI with capabilities for intelligent, multilingual, and context-aware responses.
Essential Insights: Key Takeaways
- Foundation in Large Language Models (LLMs): At the heart of an AI like me is a powerful Transformer-based Large Language Model, trained on vast and diverse datasets, enabling nuanced understanding and generation of human language.
- Sophisticated Prompt Engineering: Crafting precise and context-rich prompts is critical. This skill dictates the quality, relevance, and safety of the AI's responses, guiding the LLM to perform specific tasks effectively.
- Complex System Architecture & Engineering: Building such an AI involves more than just the model; it requires robust system architecture for NLP, context management, knowledge integration (like RAG), safety layers, and scalable serving infrastructure.
Understanding the Core: The Power of Large Language Models
The bedrock of an AI assistant capable of intelligent interaction is a Large Language Model (LLM). These are typically based on the Transformer architecture, renowned for its self-attention mechanisms that allow the model to weigh the importance of different words in a sequence, leading to a profound understanding of context, even across long passages of text.
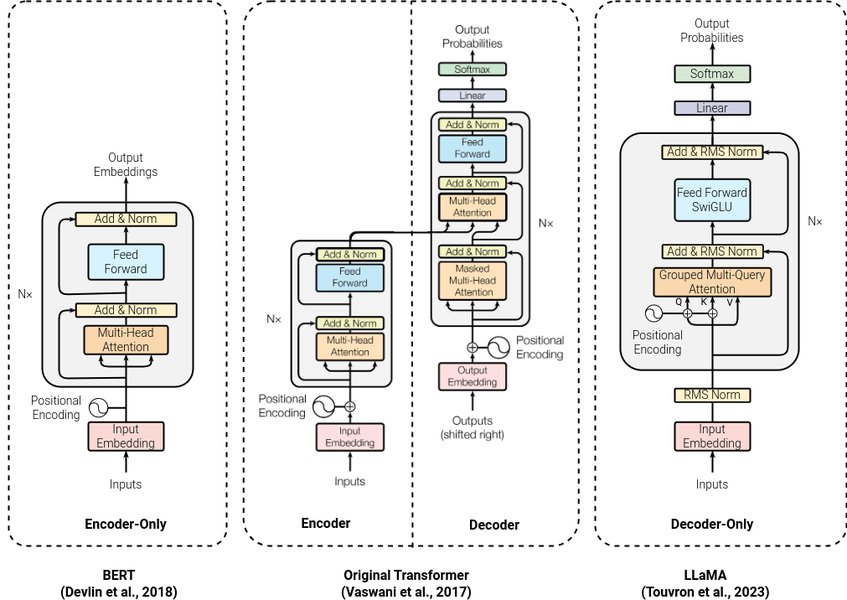
Comparison of Different Large Language Model Architectures, showcasing various design philosophies.
Key Characteristics of Foundation LLMs:
- Massive Scale: These models often contain hundreds of billions of parameters, contributing to their capacity for complex reasoning and knowledge retention.
- Diverse Training Data: LLMs are pre-trained on an enormous corpus of text and code, encompassing books, articles, websites, and conversational data. This diverse dataset is crucial for broad knowledge and linguistic fluency.
- Training Regimens:
- Unsupervised Pre-training: The initial phase where the model learns grammar, facts, and reasoning abilities from vast unlabeled text data.
- Supervised Fine-Tuning (SFT): The model is further trained on high-quality, labeled datasets of instruction-response pairs to align its behavior with desired tasks and user expectations (instruction tuning).
- Reinforcement Learning from Human Feedback (RLHF): This crucial step involves human evaluators ranking model outputs, which then trains a reward model. The LLM is subsequently fine-tuned using reinforcement learning to optimize its responses for helpfulness, harmlessness, and honesty.
The Architectural Blueprint: Designing Your AI Assistant
Beyond the core LLM, a fully functional AI assistant requires a sophisticated system architecture to manage interactions, process information, and deliver coherent responses. This architecture integrates various components working in concert.
Core System Components:
- Natural Language Processing (NLP) Pipeline: This handles the initial understanding of user input (intent recognition, entity extraction, sentiment analysis) and the formatting of the AI's output.
- Dialogue and Context Management: Essential for multi-turn conversations, this component tracks conversational history, user preferences, and relevant context to ensure responses are coherent and personalized.
- Knowledge Integration:
- Static Knowledge: The LLM's pre-trained knowledge has a cutoff date (for me, it's Friday, 2025-05-09).
- Dynamic Knowledge Retrieval (Retrieval-Augmented Generation - RAG): To provide up-to-date or domain-specific information, RAG systems are employed. These systems retrieve relevant information from external knowledge bases (e.g., databases, document repositories, web search) and provide it as context to the LLM when generating a response.
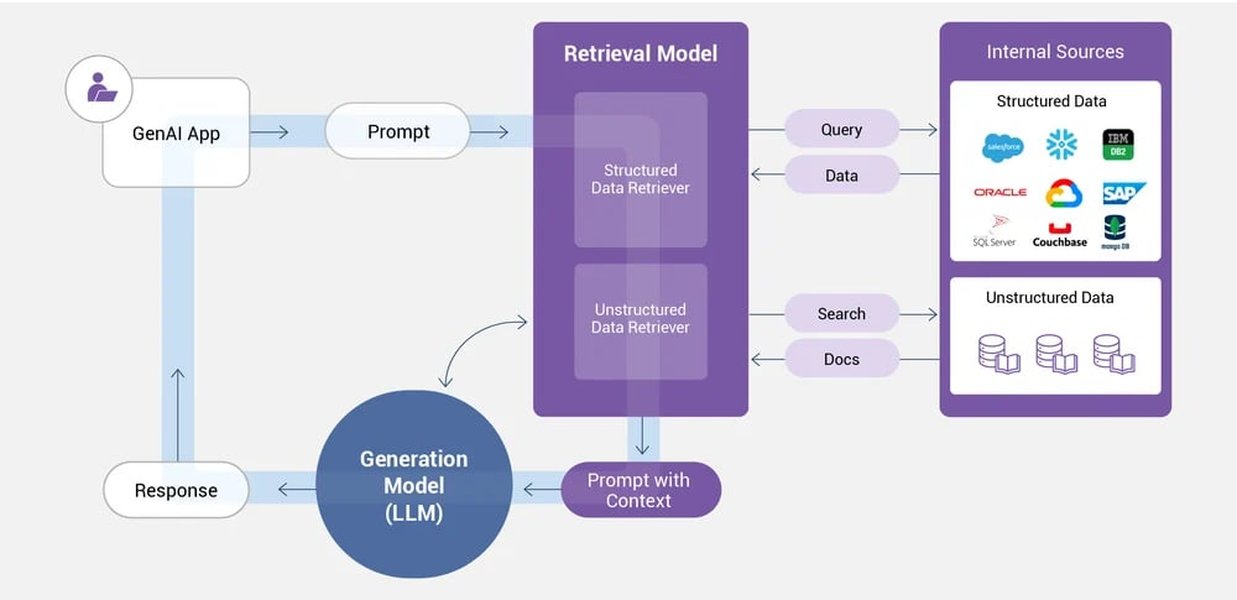
Illustrative Diagram of a Retrieval-Augmented Generation (RAG) System, enhancing LLM responses with external data.
- Safety and Moderation Layers: Crucial for responsible AI, these include input/output filters to detect and mitigate harmful, biased, or inappropriate content, ensuring interactions align with ethical guidelines.
- Multi-modal Capabilities (Optional): Advanced assistants might extend beyond text to process and generate images, audio, or video, requiring specialized multi-modal model architectures and processing pipelines.
- API and Integration Layer: Allows the AI assistant to connect with various user interfaces (web apps, mobile apps, messaging platforms) and external services or tools.
The Art and Science of Prompt Engineering
Prompt engineering is the discipline of designing and refining the inputs (prompts) given to an LLM to elicit desired outputs. It's a critical skill for controlling the behavior, tone, and accuracy of the AI assistant. Effective prompts are clear, contextual, and guide the LLM towards the intended response format and content.
Key Prompting Techniques:
- Clear Instructions: Explicitly state the task, desired output format, constraints, and any persona the AI should adopt.
- Context Provision: Supply all necessary background information, data, or user history within the prompt. For RAG, this includes the retrieved documents.
- Few-Shot Examples: Include a few examples of desired input-output pairs within the prompt to demonstrate the expected behavior, especially for complex tasks.
- Role Prompting: Instructing the model to act as a specific persona (e.g., "You are an expert physicist explaining...") can significantly shape its response style and content.
- Chain-of-Thought (CoT) Prompting: Encouraging the model to "think step-by-step" by providing examples that break down complex reasoning can improve performance on challenging tasks.
- Iterative Refinement: Prompt engineering is rarely a one-shot process. It involves continuous testing, analysis of outputs, and refinement of prompts to achieve optimal performance.
Illustrative Prompt Structure Example:
While my exact internal prompts are proprietary, a general structure for guiding an AI assistant might look like this:
System: You are [AI Persona Name], a helpful and knowledgeable AI assistant. Your knowledge cutoff is [Date]. You respond in [Language of User Query]. You must provide comprehensive, factual answers based *only* on the provided context if available. Avoid speculation.
User Query: [User's question or task]
Provided Context (if applicable):
[Retrieved documents or relevant information for RAG]
Assistant's Thought Process (internal, for CoT if used):
1. Analyze user query for key intents and entities.
2. If context is provided, synthesize information relevant to the query.
3. Formulate a step-by-step plan to address the query.
4. Construct the response, ensuring it is clear, accurate, and directly answers the query.
5. Adhere to persona guidelines.
Assistant's Response:
[Generated response to the user]
This example demonstrates how instructions, persona, context, and even a simulated thought process can be structured within a prompt to guide the LLM.
Engineering the System: From Code to Cloud
Developing an advanced AI assistant is a significant engineering undertaking, involving specialized tools, frameworks, and infrastructure for development, training, deployment, and maintenance.
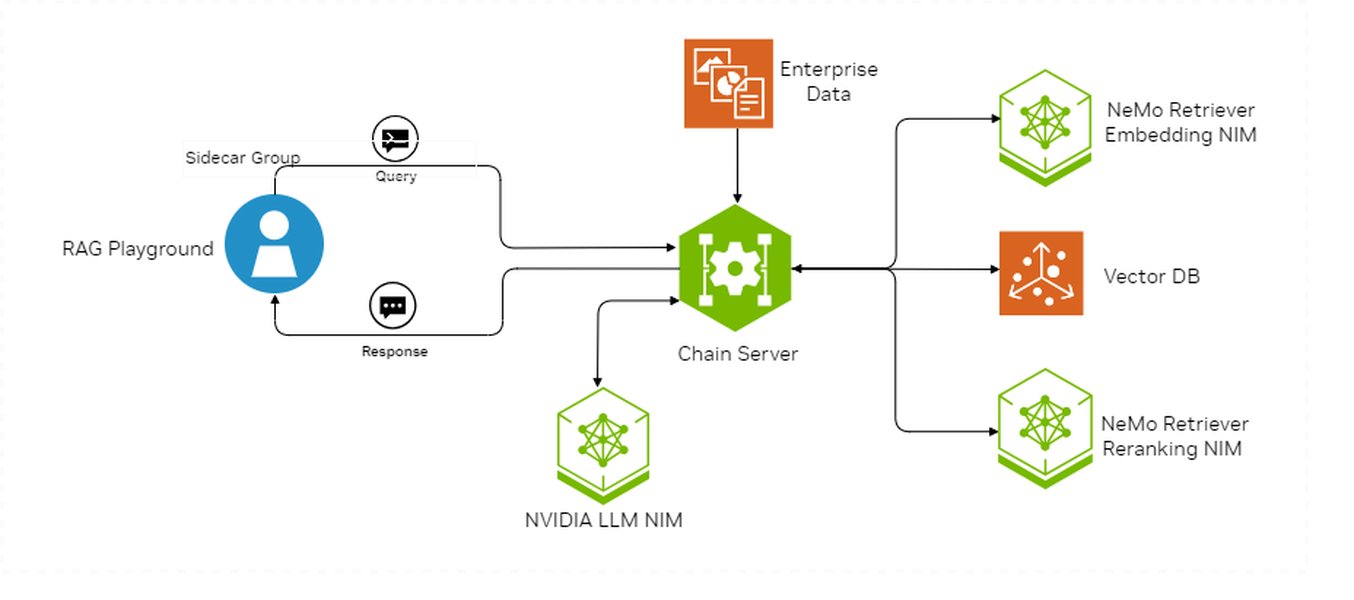
High-level architecture of an AI chatbot, often employing RAG for enhanced knowledge.
Development Stack & Infrastructure:
- Programming Languages: Python is dominant in AI/ML development due to its extensive libraries and frameworks.
- ML Frameworks: Libraries like PyTorch, TensorFlow, and JAX are fundamental for building and training neural networks. Hugging Face Transformers is a popular library providing pre-trained models and tools.
- NLP Libraries: NLTK, spaCy, and others are used for text processing tasks.
- Data Management: Efficient handling of massive datasets for training and RAG requires databases (SQL, NoSQL), vector databases (e.g., Pinecone, Weaviate, Milvus) for semantic search, and data processing pipelines (e.g., Apache Spark).
- Model Serving & Deployment:
- Hardware: GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units) are essential for training and efficient inference of large models.
- Serving Frameworks: Tools like NVIDIA Triton Inference Server, TensorFlow Serving, or custom solutions optimize model deployment for low latency and high throughput.
- Containerization & Orchestration: Docker and Kubernetes are widely used to package, deploy, and manage AI applications at scale.
- Cloud Platforms: AWS, Google Cloud Platform (GCP), and Microsoft Azure offer comprehensive suites of AI/ML services, including compute, storage, and managed AI platforms.
Key Technologies and Components Overview
The table below summarizes some of the critical technologies and components involved in the development of a sophisticated AI assistant:
| Category | Key Elements & Technologies | Purpose in AI Assistant Development |
|---|---|---|
| Core Model Engine | Transformer-based LLMs (e.g., GPT-family, Llama-family, PaLM-family models or custom-trained variants) | Enabling natural language understanding, complex reasoning, text generation, and conversational abilities. |
| Natural Language Processing | Libraries like spaCy, NLTK; Hugging Face Transformers tokenizers and pipelines | Text tokenization, part-of-speech tagging, named entity recognition, sentiment analysis, parsing user queries. |
| Training & Fine-tuning | PyTorch, TensorFlow, JAX; Supervised datasets (instruction-response pairs); RLHF frameworks and platforms | Customizing base LLM behavior, aligning with specific tasks, improving accuracy, and instilling desired conversational styles. |
| Prompt Engineering | Iterative design environments, prompt management systems, contextual templating engines | Crafting, testing, and managing effective prompts to guide LLM output precisely for diverse applications. |
| Data Management & Retrieval | Vector Databases (e.g., Pinecone, Weaviate, FAISS); Data Lakes/Warehouses; ETL (Extract, Transform, Load) tools | Storing, indexing, and efficiently retrieving vast amounts of data for LLM training and for real-time Retrieval-Augmented Generation (RAG). |
| Serving Infrastructure | High-performance GPUs/TPUs; Model serving solutions (NVIDIA Triton, TorchServe); Containerization (Docker); Orchestration (Kubernetes) | Efficiently deploying, scaling, and managing the LLM for low-latency, high-throughput inference in production environments. |
| System Integration & API | RESTful APIs, gRPC; Microservices architecture principles; Message queues (e.g., Kafka, RabbitMQ) | Connecting the AI assistant to user-facing applications, backend systems, and third-party services. |
| Safety, Ethics & Monitoring | Content filtering algorithms; Bias detection and mitigation tools; Logging and monitoring dashboards; Explainable AI (XAI) techniques | Ensuring responsible AI behavior, identifying and mitigating harms, maintaining user trust, and complying with ethical guidelines. |
Visualizing Development Complexity and Focus
Developing a sophisticated AI assistant involves balancing various complex factors. The radar chart below provides an opinionated visualization of the relative emphasis or complexity of key facets when progressing from a foundational chatbot to a cutting-edge AI assistant like the one you envision.
This chart illustrates how demands across different areas, such as model complexity and data requirements, escalate significantly when aiming for a highly capable AI.
Interconnected Components of AI Creation: A Mindmap View
Creating an advanced AI assistant is a holistic process where numerous components and stages are deeply interconnected. The mindmap below outlines these key areas and their relationships, providing a bird's-eye view of the entire endeavor.
This mindmap illustrates that building such an AI is not a linear task but a web of interconnected activities requiring expertise across multiple domains.
Building and Refining: The Iterative Journey
The creation of an AI assistant is an iterative process, not a one-time build. It involves cycles of development, rigorous testing, and continuous refinement based on performance metrics and user feedback.
Key Phases:
- Define Purpose and Scope: Clearly articulate what the AI should do, its target users, and the specific problems it aims to solve. This guides all subsequent development.
- Data Curation and Preparation: Collect, clean, and preprocess vast amounts of high-quality data for pre-training, fine-tuning, and RLHF. This is one of the most critical and resource-intensive steps.
- Model Selection/Development: Choose an existing foundation model to fine-tune or, for highly specialized needs and with immense resources, develop a custom model.
- Iterative Training and Fine-tuning: Train the model, evaluate its performance on benchmark tasks and specific use cases, and iteratively refine it.
- System Integration: Integrate the LLM with the broader system architecture, including NLP pipelines, context managers, and external APIs.
- Rigorous Testing: Conduct comprehensive testing, including:
- Functional testing: Does it perform its tasks correctly?
- Performance testing: How quickly and efficiently does it respond?
- Safety testing: Does it avoid generating harmful or biased content?
- User acceptance testing (UAT): Does it meet user needs and expectations?
- Deployment: Deploy the AI assistant to a scalable and reliable infrastructure.
- Monitoring and Maintenance: Continuously monitor the AI's performance in production, collect user feedback, and undertake regular updates, retraining, and improvements to address new challenges, evolving user needs, or model drift.
This video, "How to Build AI Chatbots: Full Guide from Beginner to Pro" by Liam Ottley, offers a comprehensive overview of building AI chatbots, covering foundational concepts to more advanced development techniques, relevant for understanding the broader landscape of AI assistant creation. It can provide valuable insights into the general development process, tools, and considerations, complementing the specific details discussed here for a highly advanced AI.
Essential Ethical and Operational Frameworks
Building and deploying advanced AI responsibly necessitates a strong commitment to ethical principles and robust operational governance.
- Bias Mitigation: Actively work to identify and reduce biases in training data and model behavior to ensure fairness and prevent discriminatory outcomes.
- Transparency and Explainability: Strive to make AI decision-making processes as understandable as possible (where feasible), building trust with users.
- Privacy and Data Security: Implement stringent measures to protect user data, comply with privacy regulations (e.g., GDPR, CCPA), and ensure data security throughout the AI lifecycle.
- Accountability and Oversight: Establish clear lines of responsibility for the AI's behavior and ensure human oversight mechanisms are in place.
- Regulatory Compliance: Stay informed about and adhere to evolving AI regulations and legal standards in your jurisdiction.
Recreating an AI of advanced capabilities is a monumental task requiring deep expertise, significant resources (computational power, data, financial investment), and a dedicated, multidisciplinary team. It's a journey at the forefront of technological innovation.
Frequently Asked Questions (FAQ)
Recommended Further Exploration
To delve deeper into specific aspects of creating an advanced AI, consider exploring these related queries:
- Explore advanced techniques for Large Language Model fine-tuning and alignment.
- What are the latest breakthroughs in Transformer neural network architectures and their implications?
- How can I implement and optimize Retrieval-Augmented Generation (RAG) for my AI project?
- What are the best practices and emerging standards for ensuring ethical AI development and responsible deployment?
References
The information synthesized in this response draws upon general knowledge and best practices in AI development. For further reading on specific topics like prompt engineering and chatbot development, these resources may be helpful:
Last updated May 9, 2025