
深入探索强化学习算法:原理、类型与未来发展
揭示AI智能决策的核心技术
亮点速览
- 核心思想:强化学习通过智能体与环境的交互,基于奖励信号学习最优决策策略。
- 主要分类:算法可大致分为Model-based(基于模型)和Model-free(无模型)两大类。
- 热门算法:当前流行的算法包括Q-learning、SARSA、DQN、PPO、A2C等。
什么是强化学习?
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,它关注智能体如何在环境中采取行动以最大化累积奖励。与监督学习和无监督学习不同,强化学习的智能体不是通过标注数据或发现数据中的隐藏结构来学习,而是通过“试错”的方式,从与环境的交互中学习最优策略。这个过程可以类比人类或动物的学习过程:通过行动、观察结果(奖励或惩罚)并调整后续行为来提高表现。
在强化学习框架中,主要包含以下几个核心组成部分:
- 智能体 (Agent): 学习和决策的主体,根据当前状态选择行动。
- 环境 (Environment): 智能体所处的外部世界,接收智能体的行动并返回新的状态和奖励。
- 状态 (State): 环境的当前状况,智能体根据状态来决定行动。
- 行动 (Action): 智能体在特定状态下可以采取的动作。
- 奖励 (Reward): 环境对智能体行动的反馈信号,可以是正面的(奖励)或负面的(惩罚)。智能体的目标是最大化长期累积奖励。
- 策略 (Policy): 智能体在给定状态下选择行动的规则或函数。
- 价值函数 (Value Function): 评估一个状态或一个状态-行动对的长期价值,即从该状态或状态-行动对出发,遵循某个策略能够获得的预期累积奖励。
强化学习与控制理论的关系
强化学习与最优控制理论有着紧密的联系。两者都旨在找到一个策略或控制器,使得系统达到最优性能。然而,强化学习通常在环境模型未知或难以精确建模的情况下工作,通过与环境的交互来学习,而最优控制则通常假设环境模型已知,并使用数学方法求解最优控制律。这种无需精确模型的能力是强化学习在复杂动态环境中应用广泛的关键。
例如,在机器人控制领域, 강화 학습 permite que los robots aprendan a realizar tareas complejas como caminar或抓取物体,即使对机器人的精确动力学模型不完全了解。以下是一个展示机器人应用强化学习的示例图片:
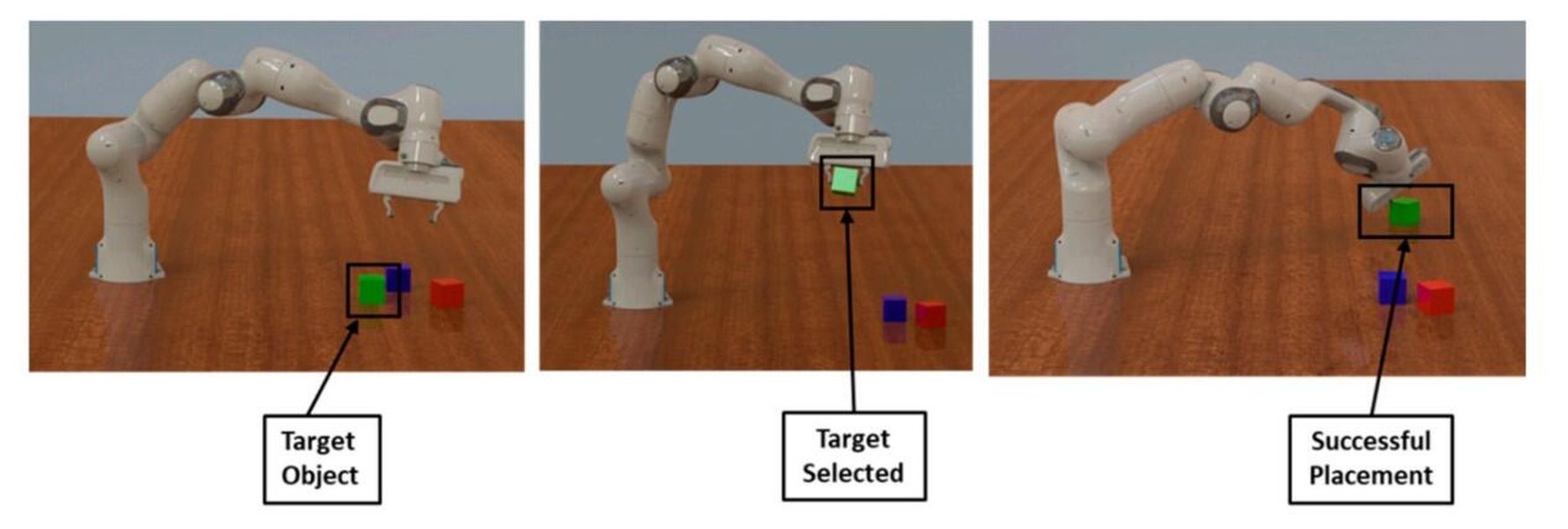
强化学习在机器人抓取任务中的应用。
强化学习算法的主要类型
强化学习算法可以根据智能体是否学习或使用环境的模型来预测下一个状态和奖励,大致分为两大类:Model-based(基于模型)和Model-free(无模型)算法。
Model-based (基于模型) 算法
基于模型的强化学习算法尝试学习或构建一个环境的模型。这个模型描述了在给定状态下采取某个行动后,环境会转移到哪个新状态以及会获得多少奖励。有了环境模型,智能体就可以在实际与环境交互之前,通过模拟来规划未来的行动。这使得智能体能够更有效地学习,尤其是在需要大量试验才能找到最优策略的环境中。
一个常见的Model-based方法是模型预测控制(Model Predictive Control, MPC)。MPC利用学习到的环境模型预测未来几个时间步的状态和奖励,然后选择能够最大化短期累积奖励的行动序列,并在每个时间步重复这个过程。
Model-free (无模型) 算法
无模型的强化学习算法不学习或使用环境的模型。它们直接从与环境的实际交互中学习最优策略或价值函数。这类算法通常更容易实现,并且在环境模型复杂或难以学习时表现良好。无模型算法又可以进一步细分为以下几种类型:
Value-based (基于价值) 方法
基于价值的方法旨在学习一个价值函数,通常是Q值函数 \(Q(s, a)\),表示在状态 \(s\) 下采取行动 \(a\) 的预期未来累积奖励。一旦学到了最优的Q值函数 \(Q^*(s, a)\),最优策略就可以通过在每个状态下选择具有最高Q值的行动来获得:\(a^* = \arg\max_a Q^*(s, a)\)。
- Q-learning: Q-learning 是一种离线(Off-policy)的无模型算法,它学习最优的Q值函数,而不依赖于当前遵循的策略。它使用贝尔曼方程(Bellman equation)的变体来更新Q值: \[ Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma \max_{a'} Q(s', a') - Q(s, a)] \] 其中 \(s\) 是当前状态,\(a\) 是当前行动,\(r\) 是获得的奖励,\(s'\) 是下一个状态,\(a'\) 是在 \(s'\) 下所有可能的行动,\(\alpha\) 是学习率,\(\gamma\) 是折扣因子。
- SARSA (State-Action-Reward-State-Action): SARSA 是一种在线(On-policy)的无模型算法,它也学习Q值函数,但其更新规则依赖于当前遵循的策略所选择的下一个行动 \(a'\)。SARSA 的更新规则如下: \[ Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma Q(s', a') - Q(s, a)] \] 注意与Q-learning的区别在于使用 \(Q(s', a')\) 而不是 \(\max_{a'} Q(s', a')\)。
- Deep Q-Networks (DQN): DQN 将深度神经网络用于近似Q值函数,使得强化学习能够处理高维度的状态空间,例如图像。DQN 引入了经验回放(Experience Replay)和固定Q目标(Fixed Q-targets)等技术来提高训练的稳定性和效率。
Policy-based (基于策略) 方法
基于策略的方法直接学习最优策略 \(\pi(a|s)\),这是一个从状态到行动概率分布的映射。这类方法的目标是找到能够最大化预期累积奖励的策略参数。基于策略的方法在连续行动空间中表现出色,因为它们可以直接输出连续的行动值,而基于价值的方法通常需要离散化行动空间。
- Policy Gradient: Policy Gradient 算法通过计算策略的梯度并沿着梯度方向更新策略参数来最大化预期奖励。REINFORCE算法是一个基本的Policy Gradient算法。
Actor-Critic (行动者-评论家) 方法
行动者-评论家方法结合了基于策略和基于价值的方法。它包含两个主要组成部分:一个行动者(Actor)学习策略函数,负责选择行动;一个评论家(Critic)学习价值函数(通常是价值函数 \(V(s)\) 或优势函数 \(A(s, a)\)),负责评估行动者的行动。评论家的评估信号被用来更新行动者的策略,从而指导行动者学习更好的策略。
- A2C (Advantage Actor-Critic): A2C 是一种流行的Actor-Critic算法,它使用优势函数 \(A(s, a) = Q(s, a) - V(s)\) 来减少策略梯度的方差。
- PPO (Proximal Policy Optimization): PPO 是一种介于Policy Gradient和Actor-Critic之间的算法,它通过限制策略更新的幅度来提高训练的稳定性。PPO 在许多任务中都取得了良好的性能,是目前非常流行的算法之一。
- DDPG (Deep Deterministic Policy Gradient): DDPG 是一种用于连续行动空间的Off-policy Actor-Critic算法。它结合了DQN的思想和Actor-Critic结构,使用深度神经网络来近似行动者和评论家。
流行强化学习算法比较
下表总结了一些流行强化学习算法的主要特点:
| 算法 | 类型 | 策略 | 行动空间 | 特点 |
|---|---|---|---|---|
| Q-learning | Model-free, Value-based | Off-policy | 离散 | 易于理解和实现,可以学习最优策略 |
| SARSA | Model-free, Value-based | On-policy | 离散 | 更新依赖于实际采取的行动 |
| DQN | Model-free, Value-based | Off-policy | 离散 | 使用深度神经网络处理高维状态,引入经验回放和固定Q目标 |
| Policy Gradient (REINFORCE) | Model-free, Policy-based | On-policy | 离散/连续 | 直接学习策略,适用于连续行动空间 |
| A2C | Model-free, Actor-Critic | On-policy | 离散/连续 | 结合Policy-based和Value-based方法,使用优势函数 |
| PPO | Model-free, Actor-Critic | On-policy | 离散/连续 | 通过限制策略更新幅度提高稳定性,性能良好 |
| DDPG | Model-free, Actor-Critic | Off-policy | 连续 | 用于连续行动空间的Off-policy算法,结合DQN和Actor-Critic |
深度强化学习
深度强化学习(Deep Reinforcement Learning, DRL)是强化学习领域的一个重要发展方向,它将深度学习的强大表示能力与强化学习的决策能力相结合。通过使用深度神经网络作为函数近似器来表示策略或价值函数,DRL 使得智能体能够处理高维度的状态空间(如图像、声音)和复杂的任务。
DQN 是最早成功的深度强化学习算法之一,它展示了深度神经网络在玩Atari游戏等任务中的潜力。随后,涌现了大量新的DRL算法,如 AlphaGo、AlphaFold 等。
以下是一个关于深度强化学习方法概述的视频:
概述深度强化学习方法的视频。
强化学习算法的应用
强化学习算法在众多领域展现出巨大的应用潜力:
- 游戏: 强化学习在游戏领域取得了显著成功,例如AlphaGo击败围棋世界冠军,以及在Atari游戏、星际争霸等复杂游戏中的出色表现。
- 机器人学: 强化学习 enables robots to learn complex motor skills, such as walking, grasping, and manipulation, through trial and error.
- 自动驾驶: 强化学习可用于训练自动驾驶汽车进行决策,例如路径规划、避障和控制。
- 推荐系统: 强化学习可以用于优化推荐策略,以最大化用户参与度和满意度。
- 金融交易: 强化学习算法可以用于开发自动交易策略,根据市场数据做出买卖决策。
- 医疗健康: 强化学习在个性化医疗、药物发现和治疗方案优化等方面具有潜在应用。
- 资源管理: 强化学习可用于优化能源消耗、交通流量控制等。

波士顿动力机器人利用强化学习在不稳定地面行走。
强化学习算法的挑战与未来
尽管强化学习取得了 impressive advancements,但仍面临一些挑战:
- 样本效率低: 许多强化学习算法需要大量的与环境的交互才能学习到良好的策略,这在实际应用中可能成本高昂或不切实际。
- 高计算成本: 训练复杂的强化学习模型,特别是深度强化学习模型,通常需要大量的计算资源。
- 奖励函数设计: 设计一个能够引导智能体学习期望行为的奖励函数可能非常具有挑战性。
- 安全性和鲁棒性: 强化学习智能体在面对未知或变化的环境时可能表现不稳定或不安全。
- 可解释性: 深度强化学习模型的决策过程往往缺乏透明度,难以解释其为何做出特定决策。
未来的研究方向包括提高样本效率、降低计算成本、开发更有效的探索策略、设计更 robust and interpretable 的算法,以及将强化学习与其他机器学习技术(如模仿学习、迁移学习)相结合。
常见问题解答 (FAQ)
强化学习与监督学习和无监督学习有什么区别?
监督学习使用带有标签的数据进行训练,学习从输入到输出的映射;无监督学习使用无标签的数据,旨在发现数据中的隐藏结构或模式;而强化学习通过与环境的交互,根据奖励信号学习如何采取行动以最大化累积奖励。
Model-based 和 Model-free 算法哪个更好?
这取决于具体的任务和环境。Model-based算法在环境模型准确且易于构建时可能更有效率,因为它们可以进行规划。Model-free算法在环境模型未知或复杂时更具优势,因为它们直接从经验中学习。在实践中,一些方法结合了两者的优点。
哪些是目前最流行的强化学习算法?
目前流行的强化学习算法包括Q-learning、SARSA、DQN、PPO、A2C、DDPG等。PPO因其良好的性能和稳定性而 widespread adoption。
如何开始学习强化学习?
可以通过在线课程、教程和实践项目来学习强化学习。许多开源库(如TensorFlow Agents, PyTorch, OpenAI Gym)提供了实现和实验强化学习算法的工具和环境。
参考文献
- Reinforcement Learning: What It Is, Algorithms, Types and Examples - Turing
- Reinforcement Learning | GeeksforGeeks
- Reinforcement learning - Wikipedia
- Part 2: Kinds of RL Algorithms — Spinning Up documentation
- Top 6 Reinforcement Learning Tools to Use - Turing
- Reinforcement Learning: An Introduction With Python Examples
- Dive Deep in Reinforcement Learning: Types, Tools and Examples
Last updated April 24, 2025