
Desvendando o Mundo das Sequências: RNN, LSTM e Transformers Explicados
Um guia didático para entender como a IA processa linguagem e séries temporais, mesmo sem conhecimento prévio.
Bem-vindo(a)! Hoje, vamos embarcar em uma jornada para entender três arquiteturas fundamentais da inteligência artificial (IA) que permitem às máquinas compreender dados sequenciais, como textos, falas ou séries temporais. Exploraremos as Redes Neurais Recorrentes (RNNs), a Memória de Longo Prazo (LSTMs) e os revolucionários Transformers. O objetivo é tornar esses conceitos acessíveis, usando analogias e exemplos visuais, mesmo que você esteja começando agora no mundo da IA.
Destaques da Exploração
- Compreensão Intuitiva: Descubra o funcionamento básico de RNNs, LSTMs e Transformers através de analogias simples do dia a dia.
- Diferenças Essenciais: Entenda as limitações das RNNs, as melhorias trazidas pelas LSTMs e o salto quântico proporcionado pelos Transformers, especialmente com o mecanismo de atenção.
- O Poder dos Transformers: Veja por que os Transformers se tornaram a base para modelos de IA avançados como o GPT e o BERT, revolucionando áreas como tradução automática e chatbots.
Antes de Começar: O que São Redes Neurais?
A Base da Inteligência Artificial Moderna
Antes de mergulharmos nas arquiteturas específicas, vamos entender o conceito fundamental: as Redes Neurais Artificiais. Pense nelas como sistemas computacionais inspirados na estrutura e funcionamento do cérebro humano.
Como Funcionam?
- Neurônios Artificiais: São compostas por unidades básicas de processamento, chamadas neurônios artificiais, organizadas em camadas.
- Aprendizado por Dados: Assim como aprendemos com a experiência, as redes neurais aprendem padrões "observando" grandes volumes de dados durante um processo chamado treinamento.
- Camadas de Processamento: A informação flui através dessas camadas: uma camada de entrada recebe os dados brutos, camadas ocultas (intermediárias) processam e transformam esses dados, e uma camada de saída produz o resultado final (uma previsão, classificação, etc.).
Analogia: Imagine uma rede neural como um cozinheiro aprendendo uma receita complexa. No início, ele pode cometer erros, mas com cada tentativa (dado), ele ajusta suas ações (conexões entre neurônios) até conseguir preparar o prato perfeitamente (realizar a tarefa desejada).
Essas redes são a espinha dorsal das arquiteturas que vamos explorar: RNN, LSTM e Transformer.
Explorando as Arquiteturas Sequenciais
1. Redes Neurais Recorrentes (RNNs): A Memória de Curto Prazo
Processando Passo a Passo
As RNNs foram uma das primeiras arquiteturas projetadas especificamente para lidar com dados onde a ordem importa – dados sequenciais. Pense em prever a próxima palavra em uma frase ou analisar o sentimento de um texto.
O conceito chave da RNN é a recorrência. Ela processa a sequência um elemento por vez (por exemplo, uma palavra de cada vez) e, a cada passo, utiliza não apenas a entrada atual, mas também uma "memória" do que viu nos passos anteriores. Essa memória é chamada de estado oculto.
Analogia: Imagine ler um livro. Para entender a frase atual, você precisa lembrar do contexto das frases anteriores. A RNN tenta fazer algo similar, mantendo um resumo do passado recente.
O Desafio da Memória Curta
Apesar de sua inteligência, as RNNs têm uma limitação significativa: elas sofrem do problema do "gradiente evanescente" (vanishing gradient). Isso significa que, em sequências longas, a informação dos passos iniciais tende a se perder ou "desvanecer" ao longo do tempo. A rede "esquece" o contexto distante.
Exemplo: Na frase "Nasci na França, por isso falo fluentemente...", uma RNN simples pode ter dificuldade em conectar "francês" com "França" se houver muitas palavras no meio.
Elas são boas para dependências curtas, mas limitadas quando o contexto crucial está muito atrás na sequência.
2. Long Short-Term Memory (LSTMs): Turbinando a Memória
Superando o Esquecimento
Para resolver o problema da memória curta das RNNs, surgiram as LSTMs. Elas são um tipo especial de RNN, mas com uma estrutura interna mais complexa, projetada para lembrar informações por períodos muito mais longos.
O segredo das LSTMs está em sua "célula de memória" e em três mecanismos especiais chamados portões (gates):
- Portão de Esquecimento (Forget Gate): Decide quais informações da memória antiga devem ser descartadas.
- Portão de Entrada (Input Gate): Decide quais novas informações da entrada atual devem ser armazenadas na célula de memória.
- Portão de Saída (Output Gate): Decide qual parte da célula de memória deve ser usada para gerar a saída daquele passo.
Analogia: Pense na célula LSTM como uma esteira de bagagens em um aeroporto com portões inteligentes. O portão de esquecimento remove malas irrelevantes, o portão de entrada adiciona novas malas importantes, e o portão de saída envia as malas certas para o destino final.
Vantagens e Limitações
As LSTMs são muito mais eficazes em capturar dependências de longo prazo do que as RNNs simples. Elas se tornaram a escolha padrão para muitas tarefas de Processamento de Linguagem Natural (PLN) por anos.
No entanto, elas ainda processam a informação sequencialmente (um passo de cada vez), o que pode ser lento para treinar em grandes volumes de dados. Além disso, sua estrutura complexa aumenta o custo computacional.
3. Transformers: A Revolução da Atenção e do Paralelismo
Adeus Sequencialidade, Olá Atenção!
Em 2017, um artigo intitulado "Attention Is All You Need" introduziu a arquitetura Transformer, marcando uma mudança radical. Em vez de processar a sequência passo a passo como RNNs e LSTMs, os Transformers analisam a sequência inteira de uma vez, usando um mecanismo poderoso chamado autoatenção (self-attention).
A autoatenção permite que cada palavra (ou elemento) na sequência "preste atenção" a todas as outras palavras na mesma sequência, ponderando a importância de cada uma para entender o contexto global. Isso permite capturar relações complexas entre palavras, mesmo que estejam distantes uma da outra.
Analogia: Imagine que, em vez de ler um livro palavra por palavra (RNN/LSTM), você pudesse olhar para a página inteira e instantaneamente entender como cada palavra se conecta com as outras para formar o significado geral. É isso que a atenção faz.
Paralelismo e Eficiência
Uma das maiores vantagens dos Transformers é sua capacidade de processamento paralelo. Como eles não dependem do estado oculto do passo anterior, todos os elementos da sequência podem ser processados simultaneamente. Isso acelera drasticamente o treinamento em hardware moderno (como GPUs) e permite treinar modelos muito maiores em conjuntos de dados massivos.
Os Transformers geralmente consistem em uma arquitetura de Codificador-Decodificador (Encoder-Decoder), onde o codificador processa a sequência de entrada e o decodificador gera a sequência de saída, ambos utilizando múltiplos blocos de autoatenção.
Comparando as Arquiteturas: RNN vs. LSTM vs. Transformer
Para visualizar as principais diferenças, vamos resumir as características de cada arquitetura:
| Característica | RNN (Rede Neural Recorrente) | LSTM (Long Short-Term Memory) | Transformer |
|---|---|---|---|
| Processamento da Sequência | Sequencial (um elemento por vez) | Sequencial (um elemento por vez) | Paralelo (todos os elementos simultaneamente) |
| Tratamento de Dependências Longas | Limitado (Problema do Gradiente Evanescente) | Melhorado (Usando portões e célula de memória) | Excelente (Usando mecanismo de autoatenção) |
| Velocidade de Treinamento | Lenta (devido à sequencialidade) | Mais Lenta que RNN (devido à complexidade) | Rápida (devido ao paralelismo) |
| Complexidade | Baixa | Alta | Muito Alta |
| Mecanismo Principal | Recorrência (Estado Oculto) | Recorrência + Portões (Gates) | Autoatenção (Self-Attention) |
| Exemplo de Uso Histórico | Tarefas simples de PLN, previsão básica | Tradução automática, análise de sentimento, geração de texto (antes dos Transformers) | Modelos de linguagem de ponta (GPT, BERT), tradução, chatbots avançados |
Análise Comparativa Visual
O gráfico radar abaixo oferece uma comparação visual das três arquiteturas com base em critérios-chave. Valores mais altos indicam melhor desempenho ou maior capacidade naquela dimensão (escala de 1 a 10, representando uma avaliação qualitativa).
Como podemos ver, os Transformers se destacam na velocidade de treinamento devido ao paralelismo e na capacidade de lidar com dependências longas graças à atenção. RNNs são mais simples, enquanto LSTMs oferecem um meio-termo, melhorando a memória das RNNs, mas sem a eficiência paralela dos Transformers.
Mapa Mental das Arquiteturas
Este mapa mental resume visualmente os conceitos chave e as relações entre as arquiteturas RNN, LSTM e Transformer.
Visualizando Aplicações dos Transformers
Os Transformers não são apenas teoria; eles impulsionam muitas das aplicações de IA que usamos hoje. As imagens abaixo, cortesia da NVIDIA, ilustram a arquitetura básica e algumas de suas diversas aplicações no mundo real.
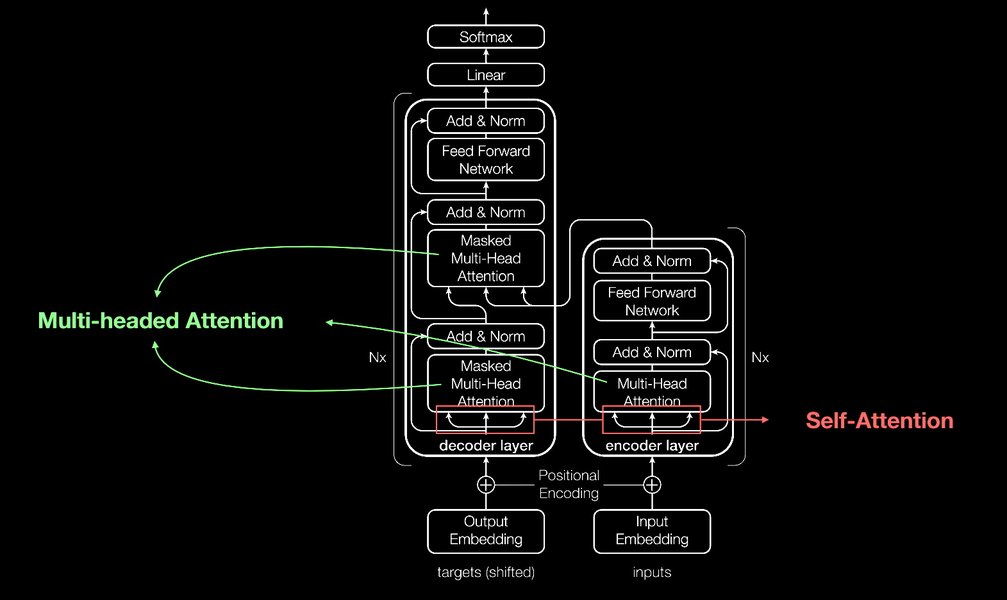
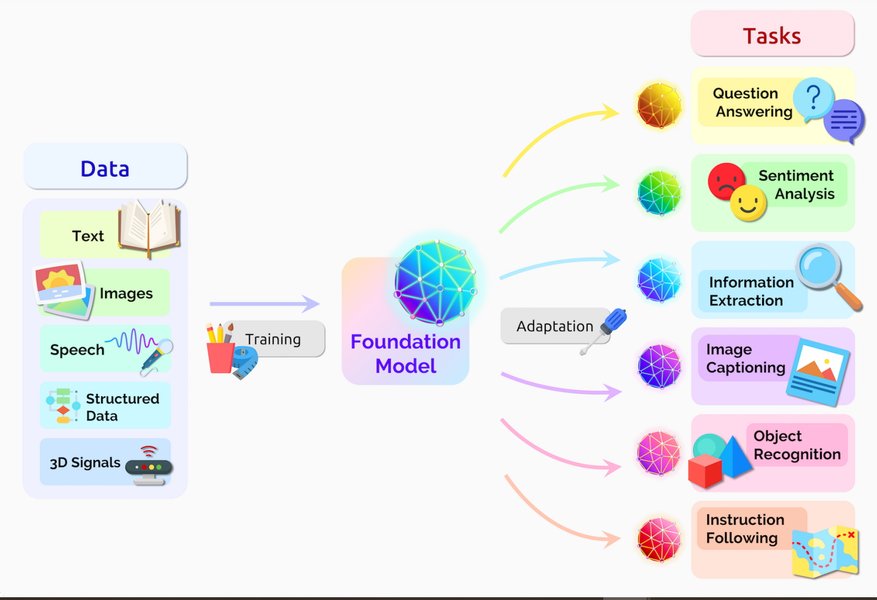
Como as imagens demonstram, a arquitetura Transformer, com seus mecanismos de atenção, provou ser extremamente versátil. Originalmente desenvolvida para tradução automática, sua capacidade de modelar relações complexas em sequências foi adaptada com sucesso para tarefas que vão desde a compreensão e geração de texto (como chatbots e sumarização) até análise de imagens e até mesmo descobertas científicas em áreas como biologia molecular.
Aprofundando com Vídeo
Para uma explicação mais dinâmica sobre as diferenças e evoluções dessas arquiteturas, o vídeo abaixo oferece uma visão geral comparativa (em inglês), abordando os conceitos que discutimos.
Este vídeo compara RNNs, LSTMs, GRUs (uma variação da LSTM) e Transformers, destacando os problemas como o gradiente evanescente nas RNNs e como as arquiteturas subsequentes tentaram resolvê-los, culminando nos Transformers e seu mecanismo de atenção. É um ótimo complemento visual para solidificar a compreensão das vantagens e desvantagens de cada abordagem.
Por Que os Transformers se Destacam?
Os Pilares do Sucesso
Os Transformers superaram as arquiteturas anteriores e se tornaram dominantes em tarefas de sequência por várias razões:
- Paralelização Superior: A capacidade de processar toda a sequência de entrada em paralelo os torna muito mais rápidos para treinar em hardware moderno (GPUs/TPUs) comparado à natureza sequencial de RNNs/LSTMs.
- Captura Eficaz de Dependências Longas: O mecanismo de autoatenção permite que o modelo relacione diretamente palavras ou elementos distantes na sequência, superando a limitação de memória das RNNs e sendo mais direto que as LSTMs.
- Escalabilidade: A arquitetura se mostrou altamente escalável. Aumentar o tamanho do modelo (mais camadas, mais parâmetros) e treiná-lo com mais dados geralmente leva a melhorias significativas de desempenho, resultando em modelos gigantes como GPT-3 e outros.
- Desempenho State-of-the-Art: Transformers estabeleceram novos recordes de desempenho em uma vasta gama de benchmarks de PLN, incluindo tradução automática, resposta a perguntas, sumarização de texto e muito mais.
Esses fatores combinados levaram à adoção generalizada dos Transformers como a arquitetura preferida para a maioria das tarefas de processamento de sequências complexas atualmente.
Aplicações no Mundo Real
Estas arquiteturas não são apenas conceitos acadêmicos; elas impulsionam tecnologias que usamos todos os dias:
- Tradução Automática: Ferramentas como o Google Tradutor usam (ou usaram extensivamente) LSTMs e, mais predominantemente agora, Transformers para fornecer traduções mais fluentes e contextualmente precisas.
- Chatbots e Assistentes Virtuais: Modelos baseados em Transformers (como GPT) permitem conversas mais naturais e coerentes com IAs.
- Geração de Texto: Desde completar frases em e-mails até escrever artigos ou código, os Transformers são a base dessas capacidades.
- Reconhecimento de Fala: A conversão de áudio em texto também se beneficia dessas arquiteturas para entender a sequência de sons.
- Análise de Sentimento: Empresas usam essas redes para entender a opinião pública sobre produtos ou serviços a partir de avaliações e mídias sociais.
- Previsão de Séries Temporais: Análise de dados financeiros, previsão do tempo e outras tarefas baseadas em sequências temporais.
Perguntas Frequentes (FAQ)
Qual arquitetura devo usar para o meu projeto?
Os Transformers tornaram as RNNs e LSTMs obsoletas?
O que é "Atenção" em termos simples?
Os Transformers são usados apenas para texto?
Referências
- RNN vs LSTM vs GRU vs Transformers - GeeksforGeeks
- From RNNs to Transformers | Baeldung on Computer Science
- RNN vs. LSTM vs. Transformers: Unraveling the Secrets of ... - Medium
- RNNs vs LSTM vs Transformers | SabrePC Blog
- O que é uma Rede Neural Recorrente (RNN)? - IBM
- O que é um Modelo Transformer? - Blog da NVIDIA (Imagem Aplicações)
- O que é um Modelo Transformer? - Blog da NVIDIA (Imagem Arquitetura)
Leituras Recomendadas
 aws.amazon.com
aws.amazon.com
Last updated April 10, 2025