
Unlock Big Data Potential: Master SAS to Parquet Conversion on HDFS
Comprehensive guide to efficiently transform large SAS datasets into high-performance Parquet format for advanced analytics
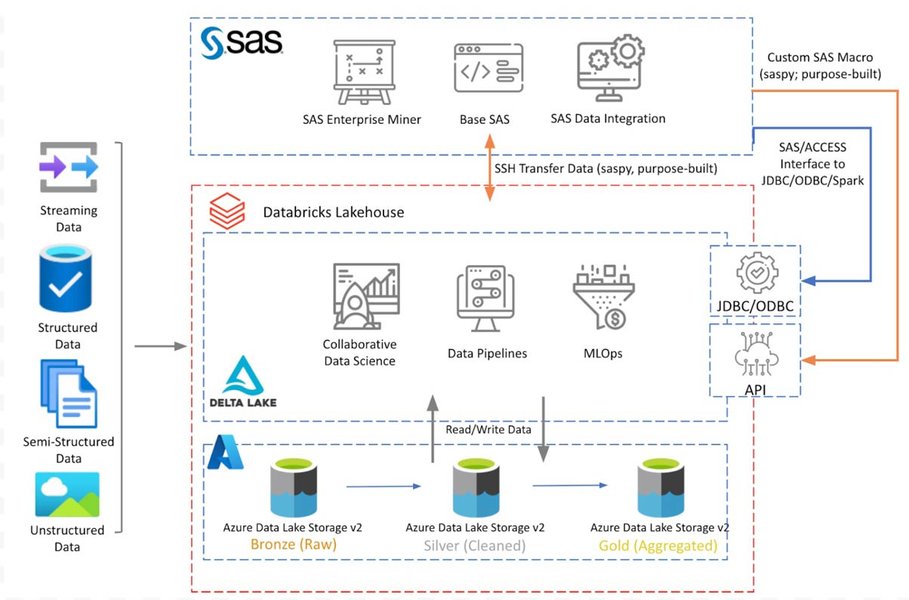
Key Approaches to Converting SAS Files to Parquet on HDFS
- Apache Spark - Leverage distributed processing for seamless conversion of large SAS files
- SAS-specific Tools - Utilize SAS Viya and custom steps for direct Parquet export
- Programming Languages - Implement R and Python solutions for flexible conversion options
Using Apache Spark for SAS to Parquet Conversion
Apache Spark provides powerful distributed processing capabilities that make it ideal for handling large SAS files. The spark-sas7bdat library enables Spark to read SAS data directly and convert it to Parquet format.
Spark-SAS7BDAT Approach
The spark-sas7bdat library allows direct reading of SAS7BDAT files into Spark DataFrames:
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("SAS to Parquet").getOrCreate()
# Read SAS file using spark-sas7bdat
df = spark.read.format('com.github.saurfang.sas7bdat').load('path/to/local/file.sas7bdat')
# Write to Parquet format on HDFS
df.write.parquet('hdfs://path/to/hdfs/output.parquet')
Setting Up Spark with SAS7BDAT Support
To use the spark-sas7bdat library, you'll need to include it when launching Spark:
spark-shell --master local[4] --packages saurfang:spark-sas7bdat:3.0.0-s_2.12
Benefits of the Spark Approach
- Handles very large files that wouldn't fit in memory
- Leverages distributed processing for faster conversion
- Supports partitioning of output data for better query performance
- Allows transformation during conversion
Using SAS-Specific Tools for Parquet Conversion
SAS Viya Direct Export
If you have access to SAS Viya 4, you can directly export SAS datasets to Parquet files:
/* SAS Viya 4 code for Parquet export */
libname parqout parquet "/path/to/output/";
data parqout.dataset;
set work.source_data;
run;
SAS Studio Custom Step
SAS Studio users can utilize a custom step that leverages the SAS Viya LIBNAME Engine for Parquet:
/* Using SAS Studio custom step */
libname pq parquet '/path/to/output/' compress=snappy;
proc copy in=work out=pq;
select dataset;
run;
Using PROC HADOOP with FILENAME HADOOP
For SAS 9.4 environments with Hadoop integration, you can use PROC HADOOP to interact with HDFS:
/* Access HDFS with FILENAME HADOOP */
filename hdfsfile hadoop "/path/to/hdfs/file.parquet";
/* Execute Hadoop commands via PROC HADOOP */
proc hadoop options=(fs);
mkdir '/path/to/hdfs/output';
chmod '/path/to/hdfs/output' 777;
quit;
SAS to Hive and Then to HDFS
You can also create Hive tables that store data in Parquet format:
libname hive hadoop
server="hadoop-server.example.com"
user=&sysuserid
password="password"
database=hive_db
subprotocol=hive2
DBCREATE_TABLE_OPTS='STORED AS PARQUET';
proc sql;
create table hive.sas_data_parquet as select * from work.source_data;
quit;
Using R and Python for SAS to Parquet Conversion
R with parquetize Package
The parquetize package in R provides memory-efficient conversion of large SAS files:
library(parquetize)
# Convert SAS to Parquet with memory limits
table_to_parquet(
path_to_file = "large_file.sas7bdat",
path_to_parquet = "output_directory",
max_memory = 5000, # Maximum memory usage in MB
encoding = "utf-8"
)
Python with Pandas and PyArrow
For Python users, pandas combined with pyarrow can read SAS files and write to Parquet:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
from pyarrow import fs
# Read SAS file
df = pd.read_sas("large_file.sas7bdat", encoding="utf-8")
# Create PyArrow table
table = pa.Table.from_pandas(df)
# Create HDFS filesystem object
hdfs = fs.HadoopFileSystem(host="namenode", port=8020)
# Write to Parquet on HDFS
pq.write_table(table, "path/to/output.parquet", filesystem=hdfs)
Using Jupyter Notebook with saspy
The saspy library allows Python users to execute SAS procedures and convert data:
import saspy
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Connect to SAS session
sas = saspy.SASsession()
# Get SAS data
sas_data = sas.sasdata('dataset', libref='mylib')
# Convert to pandas DataFrame
df = sas_data.to_df()
# Write to Parquet
df.to_parquet("output.parquet")
Intermediate Format Approaches
When direct conversion isn't possible, you may need to use intermediate formats before converting to Parquet.
| Approach | Intermediate Format | Tools | Advantages | Disadvantages |
|---|---|---|---|---|
| CSV Conversion | CSV | SAS PROC EXPORT, Spark, Pandas | Simple, widely supported | Large file size, slow conversion |
| JSON Conversion | JSON | SAS JSON engine, Python json library | Preserves complex structures | Even larger file size than CSV |
| Avro Conversion | Avro | Spark, Hadoop tools | Schema evolution, compact binary format | More complex conversion process |
| Database Import/Export | RDBMS | SAS/ACCESS, JDBC, ODBC | Leverages existing database tools | Requires database infrastructure |
Data Pipeline Tools
Tools like Apache NiFi and AWS Glue can automate the entire conversion workflow:
Apache NiFi Workflow
- Configure GetFile processor to read local SAS files
- Use ConvertRecord or ExecuteScript processors for conversion
- Configure PutHDFS processor to write Parquet files to HDFS
AWS Glue for Cloud-Based Conversion
- Upload SAS files to Amazon S3
- Create and run an AWS Glue ETL job to convert to Parquet
- Transfer the Parquet files from S3 to HDFS using distcp or S3 connector
Frequently Asked Questions
References
- Transform SAS files to Parquet through Spark - GitHub
- Converting Huge Input Files to Parquet Format - CRAN
- How can I export my data in parquet format - SAS Communities
- Spark SAS7BDAT - GitHub
- Reading Parquet Files in SAS 9.4 - SAS Communities
- SAS Studio Custom Steps - GitHub
Recommended Queries
Last updated March 29, 2025