
Understanding Apache Spark Internals on Amazon EMR
A Comprehensive Guide to Spark Architecture, Partitioning, and Configuration on EMR
Key Takeaways
- Optimized Performance: Amazon EMR enhances Spark's performance through specialized runtimes and resource management techniques.
- Effective Data Partitioning: Utilizing
repartitionandcoalesceefficiently is crucial for optimal data distribution and processing. - Critical Configurations: Properly tuning Spark configurations on EMR can significantly impact resource utilization, performance, and cost-effectiveness.
1. Spark Internals on Amazon EMR
1.1. Cluster Architecture and Execution Model
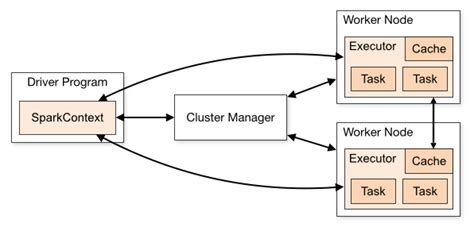
Apache Spark, when deployed on Amazon EMR (Elastic MapReduce), operates within a managed Hadoop ecosystem. This integration leverages AWS's robust infrastructure to optimize the distribution and processing of large datasets. The core components of Spark on EMR include:
- Driver and Executors: The driver program orchestrates the execution of Spark applications, managing task scheduling and maintaining metadata. Executors, running on worker nodes, carry out the actual data processing tasks.
- Resource Management: EMR utilizes resource managers like YARN (Yet Another Resource Negotiator) or Kubernetes (in the case of EMR on EKS) to allocate CPU, memory, and other resources dynamically among Spark jobs.
- Directed Acyclic Graph (DAG) Engine: Spark employs a DAG execution engine that optimizes the execution plan by organizing tasks into stages, minimizing data shuffling, and enhancing parallelism.
- Fault Tolerance: Leveraging lineage information, Spark can recompute lost data partitions in the event of node failures, ensuring robust and reliable data processing.
1.2. Optimized Runtime and Performance Enhancements
Amazon EMR provides an optimized runtime for Spark, delivering substantial performance improvements over open-source Spark deployments. Key optimizations include:
- Adaptive Query Execution (AQE): AQE dynamically adjusts query plans based on runtime statistics, optimizing shuffle operations and join strategies to reduce latency and improve throughput.
- Task Deduplication: EMR's task deduplication mechanism ensures that redundant tasks are minimized, enhancing overall cluster efficiency.
- Integration with S3: Using EMR File System (EMRFS), Spark on EMR seamlessly integrates with Amazon S3, offering features like consistent view and S3 Select optimizations for faster data access.
- Dynamic Resource Scaling: EMR's dynamic allocation feature allows Spark to scale the number of executors up or down based on workload demands, ensuring optimal resource utilization and cost management.
1.3. EMR-Specific Features and Integrations
Beyond standard Spark features, Amazon EMR introduces several enhancements tailored for cloud environments:
- Spot Instance Integration: EMR leverages AWS Spot Instances to reduce costs. Spark jobs are configured to handle the volatility of Spot Instances gracefully, ensuring resilience against node interruptions.
- EMRFS Tuning: Features like consistent view ensure data consistency during concurrent writes, while S3 Select optimizations enable efficient querying of S3 data directly.
- Autoscaling Mechanisms: EMR's autoscaling adjusts the cluster size based on real-time workload, ensuring that Spark applications have the necessary resources without overprovisioning.
2. Repartition vs. Coalesce in Spark
2.1. Importance of Data Partitioning
Effective data partitioning is fundamental to achieving high performance in distributed computing with Spark. Proper partitioning ensures balanced workload distribution, minimizes data shuffling, and optimizes resource utilization across the cluster.
2.2. Understanding repartition and coalesce
2.2.1. repartition
repartition is a transformative operation in Spark that adjusts the number of partitions in a DataFrame or RDD. It can both increase and decrease the partition count, ensuring an even distribution of data across the cluster.
- Purpose: To alter the number of partitions for enhancing parallelism or balancing data distribution.
- Behavior: Triggers a full shuffle of data across executors, redistributing data uniformly.
- Use Case: Ideal for increasing the number of partitions to leverage more parallelism or ensuring even data distribution after operations that may cause data skew.
- Performance Impact: Since it involves a comprehensive data shuffle, it is computationally more intensive and can lead to higher latency.
- Example:
df = df.repartition(100)This command redistributes the DataFrame
dfinto 100 partitions.
2.2.2. coalesce
coalesce is an optimized operation designed primarily for reducing the number of partitions in a DataFrame or RDD without incurring the overhead of a full data shuffle.
- Purpose: To decrease the number of partitions efficiently, minimizing data movement.
- Behavior: Combines existing partitions locally within the same executor, avoiding a full shuffle whenever possible.
- Use Case: Best suited for operations like filtering, where post-operation data size is reduced, and fewer partitions are sufficient.
- Performance Advantage: More performance-efficient compared to
repartition, as it reduces unnecessary data movement. - Example:
df = df.coalesce(10)Reduces the number of partitions in the DataFrame
dfto 10.
2.3. Comparative Analysis
| Feature | Repartition | Coalesce |
|---|---|---|
| Shuffling | Full shuffle of data across executors. | Minimizes shuffle by consolidating existing partitions locally. |
| Partition Count Adjustment | Can both increase and decrease the number of partitions. | Only decreases the number of partitions. |
| Performance Impact | Higher due to comprehensive data movement. | Lower as it avoids extensive shuffling. |
| Use Case | Enhancing parallelism or redistributing skewed data. | Optimizing partitions post data reduction operations. |
3. Essential Spark Configurations on EMR
3.1. Core Configuration Parameters
Properly configuring Spark is paramount to harnessing its full potential on EMR. Key configuration parameters influence memory allocation, parallelism, resource utilization, and overall application performance.
3.1.1. Memory Management
spark.executor.memory: Defines the amount of memory allocated to each executor. Adequate memory allocation prevents out-of-memory errors and ensures efficient task execution.spark.driver.memory: Specifies the memory allocated to the driver program, which manages job scheduling and metadata.spark.memory.fraction: Determines the fraction of executor memory dedicated to execution and storage. Tuning this parameter helps balance between caching data and executing tasks.
3.1.2. Parallelism Settings
spark.default.parallelism: Sets the default number of partitions for RDDs. Typically, this value is set to the number of executor cores multiplied by the number of executors to maximize parallelism.spark.sql.shuffle.partitions: Controls the number of partitions created during shuffle operations. A higher number can enhance parallelism but may increase overhead if set excessively high.
3.1.3. Dynamic Resource Allocation
spark.dynamicAllocation.enabled: Enables Spark to adjust the number of executors dynamically based on workload demands, optimizing resource utilization.spark.dynamicAllocation.minExecutors&spark.dynamicAllocation.maxExecutors: Define the minimum and maximum number of executors that Spark can allocate, providing boundaries for dynamic scaling.
3.1.4. Shuffle and I/O Optimization
spark.shuffle.file.buffer: Sets the buffer size for writing shuffle files, directly impacting disk I/O performance during shuffle operations.spark.sql.autoBroadcastJoinThreshold: Determines the size threshold for performing broadcast joins. Increasing this value can expedite join operations involving smaller lookup tables.
3.1.5. Execution Settings
spark.executor.cores: Number of CPU cores allocated per executor. Balancing cores and memory per executor ensures optimal parallelism and resource utilization.spark.local.dir: Specifies the directory for temporary storage during shuffles and spills. On EMR, pointing this to high-performance instance storage can enhance I/O operations.
3.2. EMR-Specific Configurations
3.2.1. YARN Integration
spark.yarn.executor.memoryOverhead: Accounts for non-JVM memory usage, such as native libraries, preventing memory-related issues.spark.hadoop.fs.s3a.connection.maximum: Optimizes the number of parallel S3 connections, improving data read/write performance to Amazon S3.
3.2.2. EMRFS Tuning
fs.s3.consistent: Enables consistent views for Amazon S3 operations, preventing race conditions during concurrent reads and writes.
3.2.3. Autoscaling Configurations
spark.executor.instances: Defines the number of executor instances. While manual tuning is possible, leveraging EMR's autoscaling features is often more efficient for dynamic workloads.
3.3. Configuration Hierarchy and Management
Spark configurations can be specified through multiple channels, each with varying precedence:
- Programmatically: Using
SparkConfor the Spark session builder within application code. - Command-Line Arguments: Passing configurations as arguments during the
spark-submitprocess. - Configuration Files: Defining cluster-wide settings in the
spark-defaults.conffile.
Understanding the configuration hierarchy ensures that critical settings are correctly applied, preventing conflicts and optimizing cluster performance.
4. Best Practices for Running Spark on EMR
4.1. Efficient Data Partitioning
- Balanced Partitioning: Use
repartitionto ensure even data distribution across executors, especially after operations that may cause data skew. - Minimize Shuffling: Adjust
spark.sql.shuffle.partitionsthoughtfully to balance between parallelism and overhead, avoiding excessively high partition counts. - Reduce Partitions When Necessary: Utilize
coalescepost data reduction operations to decrease partition counts without incurring the cost of a full shuffle.
4.2. Optimal Resource Allocation
- Memory and CPU Allocation: Allocate sufficient memory and CPU cores to executors based on the workload and dataset size, preventing memory bottlenecks and ensuring efficient processing.
- Leverage Dynamic Allocation: Enable dynamic resource allocation to allow Spark to scale executors based on real-time workload demands, optimizing resource usage and cost.
4.3. Data Localization and Storage Optimization
- Use EMRFS for Data Storage: Store data in Amazon S3 using EMRFS for scalable and reliable storage, benefiting from features like consistent view and S3 Select optimizations.
- Optimize Data Access Patterns: Ensure data is partitioned and stored in a manner that minimizes access latency and maximizes throughput, enhancing overall job performance.
4.4. Monitoring and Performance Tuning
-
Utilize EMR Monitoring Tools: Employ Amazon CloudWatch and EMR's native monitoring tools to track performance metrics, identify bottlenecks, and gain insights into resource utilization.
-
Tune Configurations Based on Insights: Adjust Spark configurations iteratively based on monitoring data to continuously optimize job performance and resource efficiency.
-
Implement Logging and Alerting: Set up comprehensive logging and alerting mechanisms to proactively detect and address issues, ensuring smooth Spark operations.
Conclusion
Deploying Apache Spark on Amazon EMR offers a powerful combination of Spark's distributed computing capabilities with AWS's scalable and managed infrastructure. Understanding the intricacies of Spark's internals on EMR, effectively utilizing partitioning mechanisms like repartition and coalesce, and meticulously tuning Spark configurations are essential for maximizing performance, ensuring efficient resource utilization, and optimizing operational costs. By adhering to best practices and leveraging EMR's specialized features, organizations can harness the full potential of Spark for their big data processing needs.
References
 docs.aws.amazon.com
docs.aws.amazon.com
docs.aws.amazon.com
docs.aws.amazon.com

Last updated January 19, 2025