
Introduction to Speech Enhancement Research
Exploring the Fusion of Spectrogram Analysis and U-Net Architecture for Advanced Audio Denoising
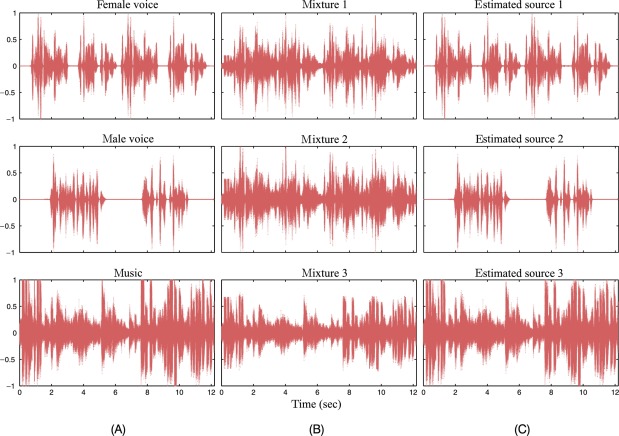
Key Takeaways
- Integration Synergy: Combining spectrogram analysis with U-Net architecture leverages image processing capabilities for effective noise reduction in audio signals.
- Data-Driven Enhancement: Using deep learning enables adaptive feature extraction and noise separation, outperforming traditional statistical approaches.
- Innovative Applications: This research methodology holds promise for a wide range of applications in telecommunications, hearing aids, and automatic speech recognition systems.
Overview of Speech Enhancement
Speech enhancement represents a critical domain within audio signal processing, aimed at improving the intelligibility and quality of speech under noisy and challenging conditions. With the increasing ubiquity of audio-based interactions in modern technology—including teleconferencing, voice-activated systems, and assistive hearing devices—the quest for effective noise reduction methods has become ever more essential. Amidst a backdrop of rapidly advancing deep learning techniques, contemporary research is turning towards innovative strategies that combine traditional signal processing with robust machine learning architectures, such as the U-Net.
The Central Role of Spectrogram Analysis
Understanding Spectrograms
A spectrogram is a visual representation that displays the frequency content of an audio signal over time. By mapping sound into an image-like structure, with time plotted along the horizontal axis and frequency along the vertical axis, spectrograms provide an intuitive understanding of the temporal and spectral characteristics crucial for speech analysis. In these images, brightness or color intensity corresponds to the amplitude of specific frequency components at given times.
The utility of spectrograms in speech enhancement lies in their ability to illustrate distinct speech features—such as phonemes, harmonics, and formants—while concurrently highlighting noise elements. This separation is vital in isolating meaningful speech information from unwanted ambient sounds. Applying deep learning techniques to spectrogram data allows models to effectively learn patterns that distinguish clean speech from noise, thus providing a pathway for automated and accurate speech improvement.
Applications of Spectrogram Analysis
Spectrogram analysis finds application in various tasks including:
- Noise Reduction: Identifying and subtracting noise components from the audio frequency domain.
- Feature Extraction: Enabling the detection of pertinent acoustic features that vary with speech content.
- Speech Recognition: Facilitating the accurate transcription and recognition of speech by enhancing clarity.
The rich informational content embedded in spectrograms acts as a superior medium for feeding neural networks that are designed to refine and regenerate clean audio signals from degraded recordings.
U-Net Architecture for Speech Enhancement
Foundations of the U-Net Model
Historical Background and Adaptation
Originally developed for biomedical image segmentation, the U-Net architecture has found a transformative role in the field of speech enhancement. Its unique encoder-decoder structure is designed to compress input data into a compact representation and subsequently reconstruct it with preserved spatial (or spectral) details. The presence of skip connections between the encoder and decoder pathways is particularly beneficial as it helps bypass the information bottleneck, ensuring that fine-grained details of the input spectrogram are retained throughout the processing pipeline.
Model Structure and Feature Extraction
The U-Net model processes input spectrograms by initially applying several layers of convolutional operations. In the encoder phase, these layers progressively abstract the input into features that capture the essence of the speech signal and noise. The subsequent decoder phase uses these abstracted features to generate a noise model that, when subtracted from the original spectrogram, results in a cleaner speech representation.
Notable characteristics of the U-Net architecture include its modular design, scalable depth, and the inclusion of activation functions such as ReLU or LeakyReLU, which help maintain non-linearities in the transformation processes. Additionally, the architecture benefits from modern optimization algorithms like Adam and robust loss functions (e.g., Huber loss), which are instrumental in balancing reconstruction fidelity with noise suppression.
Integrating Spectrogram Analysis with U-Net for Enhanced Speech Denoising
Insights into the Methodology
The fusion of spectrogram analysis and U-Net architecture forms a sophisticated framework for tackling the inherent challenges of noisy speech environments. The process begins with the transformation of raw audio into magnitude spectrograms via the short-time Fourier transform (STFT), which dissects the audio into overlapping temporal segments to reveal frequency content. This representation serves as an ideal input for convolutional neural networks due to its image-like qualities.
Processing Pipeline
The speech enhancement process can be broadly divided into the following stages:
- Data Preparation: Aggregation of clean speech and noise datasets, followed by their conversion into spectrogram forms. This step involves resampling and windowing techniques to create standardized input representations.
- Model Training: Feeding noisy spectrograms into the U-Net model, which learns to predict the noise pattern present in the audio. The training phase involves iterative optimization over large datasets, often complemented by data augmentation to improve model robustness.
- Prediction and Reconstruction: Once trained, the model applies the learned noise profile to subtract it from new, unseen noisy spectrograms. The refined spectrogram is then transformed back into an audio signal through an inverse STFT, ideally resulting in enhanced speech quality.
The integration schema takes full advantage of the spectral decomposition provided by spectrograms and the deep feature extraction capabilities of the U-Net model. The dual approach ensures that even in the presence of significant environmental noise, the underlying speech components are effectively restored.
Real-World Performance and Challenges
Practical applications of this integrated approach have demonstrated high levels of performance in challenging acoustic conditions. The trained models are capable of generalizing across diverse noise types such as mechanical sounds, urban ambient noise, and dynamic background chatter. While the approach is robust, it also faces challenges, including the accurate recovery of phase information during the reverse transformation from spectrogram back to time-domain audio. In some advanced models, phase-sensitive masks are employed to address these challenges and further refine the quality of the output.
Comparative Analysis: Traditional Methods vs. Deep Learning Approaches
Understanding the Evolution in Speech Enhancement Techniques
Historically, speech enhancement relied heavily on methods such as spectral subtraction, Wiener filtering, and other statistical techniques. These methods work effectively under certain controlled conditions but tend to falter in dynamic or unpredictable noisy environments. Their reliance on defined statistical characteristics limits adaptability.
Table: Comparison of Traditional and Deep Learning-Based Speech Enhancement Methods
| Aspect | Traditional Methods | Deep Learning Approaches |
|---|---|---|
| Data Dependency | Primarily model-driven with fixed parameters | Data-driven with adaptive feature extraction |
| Noise Adaptability | Struggle with non-stationary noise | Effective handling of dynamic noise patterns |
| Computational Complexity | Less intensive but less flexible | High computational demand during training but efficient inference |
| Output Quality | Often compromised by artifacts and distortions | Produces higher quality, cleaner speech signals |
| Application Range | Limited to specific noise environments | Wide applicability across diverse scenarios |
This comparative analysis underscores the evolutionary shift in speech enhancement techniques. While traditional methods have provided foundational insights and baseline performance, the robust learning capabilities and adaptability of deep learning approaches, especially those employing U-Net architectures, have substantially advanced the state-of-the-art in this field.
Detailed Methodology for Research Implementation
Data Acquisition and Preprocessing
Data Collection
The cornerstone of any robust speech enhancement system is the availability of high-quality, diverse datasets. In this research, clean speech recordings are typically sourced from established corpora, while various types of environmental noise are collected from public repositories and specifically tailored recordings that capture realistic ambient conditions. These datasets are often sampled at frequencies such as 8 kHz or 16 kHz to ensure clarity and compatibility with standard speech processing tasks.
Preprocessing Techniques
Preprocessing involves segmenting the audio into fixed-duration windows, performing noise normalization, and converting time-domain signals into spectrograms using techniques like the Short-Time Fourier Transform (STFT). The magnitude of the spectrogram is then extracted to serve as the primary input for the U-Net model, while techniques for handling phase information are also integrated to allow a proper reconstruction of the final enhanced audio. Data augmentation strategies are employed to expose the model to a variety of noise intensities, ensuring improved generalizability.
Model Training Process
Designing the U-Net Architecture
The U-Net model, with its deep convolutional layers, features an initial encoding phase followed by a decoding phase. In the encoding phase, the model extracts hierarchical features from input spectrograms, compressing the environment noise information along with the fine details of speech. The decoding phase then reconstructs a noise profile that is subtracted from the noisy signal, effectively isolating the clean voice content.
Optimization strategies such as the Adam optimizer, specially chosen loss functions like Huber loss or a hybrid of L1 and L2 losses, contribute to the model's balanced learning process. Training is conducted over multiple epochs on GPUs, employing batch processing for efficient computation.
Validation and Evaluation
To assess performance, the enhanced speech output is compared against ground truth clean audio using objective metrics such as Signal-to-Noise Ratio (SNR), Perceptual Evaluation of Speech Quality (PESQ), and Short-Time Objective Intelligibility (STOI). These evaluations help quantify the improvements and identify potential areas for optimization regarding noise removal and speech clarity.
Applications and Impact of Enhanced Speech Processing
Real-World Implementations
Enhancing speech quality through the combination of spectrogram analysis and U-Net architecture is not just a theoretical pursuit. Its applications extend to several high-impact areas:
- Telecommunications: Improved clarity in voice calls and video conferencing, which is essential for professional communication.
- Hearing Aids: Enhanced speech signal quality can directly benefit users with hearing impairments, making everyday communication smoother.
- Voice-Controlled Systems: Noise robust systems are pivotal for the reliability of virtual assistants, smart speakers, and other automated services that rely on audio input.
- Speech Recognition: Cleaner audio signals lead to more accurate transcription and data extraction, critical in domains such as security and automated customer service.
Societal and Technological Impacts
On a societal level, advancements in speech enhancement technology promote inclusivity and accessibility. With clearer and more intelligible speech, devices can better serve diverse populations, including non-native speakers and individuals in noisy environments. Technologically, such research underscores the potential of deep learning in solving real-world problems where traditional methods have reached their limits, pushing the boundaries of what automated systems can achieve.
Conclusion and Future Perspectives
In summary, this research introduces an innovative approach to speech enhancement by merging the analytical power of spectrograms with the sophisticated feature extraction and reconstruction capabilities of the U-Net architecture. This method has demonstrated a significant potential for reducing background noise while preserving the essential qualities of speech, thereby addressing critical challenges present in many real-world audio processing scenarios.
The collaborative use of these techniques not only provides an improved pathway for audio clarity in noisy environments but also paves the way for future advancements in various audio-centric applications. The adaptability of deep learning models like U-Net ensures that as datasets grow and computational techniques evolve, the quality of speech enhancement will continue to improve. Future research may explore more refined phase reconstruction techniques, integration with other deep architectures, and wider applications in real-time systems.
References
- Alden-Crist/speech-enhancement-noise-reduction-unet - GitHub
- Complex U-Net for Enhanced Speech Processing - Academia.edu
- Speech_enhancement_using_convolutional_autoencoders - GitHub
- Spectrogram-based-Audio-Enhancement-with-U-Net - GitHub
- P SPEECH ENHANCEMENT WITH D C U-NET - OpenReview
Learn More
Last updated February 18, 2025