
Mastering SQL Joins: Best Practices for Handling NULL Values
Explore strategies to manage missing data according to join types in SQL
Key Highlights
- Understanding NULLs: NULL represents missing or unknown data and affects join conditions uniquely.
- Join Behavior: INNER, LEFT, RIGHT, and FULL OUTER JOINS treat NULLs differently, crucial for data retrieval.
- Effective Strategies: Use functions like COALESCE/ISNULL and specific join conditions to handle NULL values.
Overview of NULL Behavior in SQL Joins
In SQL, NULL is not merely an empty string or zero value; it represents an unknown or missing value. This peculiar trait often complicates SQL join operations, as NULL is never considered equal to another NULL. An equal comparison such as NULL = NULL evaluates to UNKNOWN rather than true. As a result, join conditions that involve NULLs demand a careful approach to retrieve accurate and expected data.
Understanding the Effect of NULL in JOIN Clauses
When dealing with JOINs, the way NULL values are treated can greatly impact the outcome of your query:
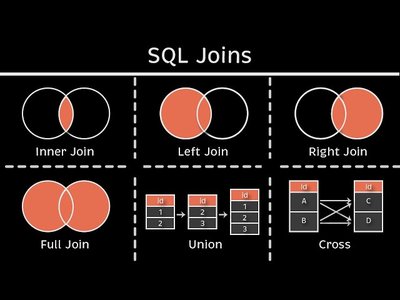
INNER JOIN
Only rows where the join condition evaluates to a true match are returned. Rows containing NULL in the join key from either table will be excluded.
LEFT (and RIGHT) OUTER JOIN
These join types include all rows from the specified primary table (left or right) regardless of whether there is a matching row in the secondary table. If no match is found, the columns for the secondary table are filled with NULL values. This ensures that no data from the primary table is omitted even if the join condition misses due to NULL values.
FULL OUTER JOIN
FULL OUTER JOIN returns all rows from both tables. If one table has a NULL in the join column or lacks a corresponding match, rows will still appear in the final result set with NULL values filling in for the missing data. However, careful handling is required to prevent redundancy and ensure that duplicate NULLs do not cause misinterpretations.
Strategies for Handling NULL Values in SQL Joins
There are several techniques to manage NULL values effectively when performing SQL join operations. The selection of an appropriate method should be based on the specific data model and business logic requirements.
1. Using COALESCE and ISNULL Functions
Functions such as COALESCE and ISNULL are frequently used to replace NULL values with a default value during join conditions. Using these functions can simplify the join process by ensuring that what might otherwise be an unmatched pair due to NULL values becomes a match when both sides are transformed to a predefined value.
SELECT *
FROM tableA A
INNER JOIN tableB B
ON COALESCE(A.key, 'default_value') = COALESCE(B.key, 'default_value');Although this approach is effective, it is important to note that using functions directly in the join condition may sometimes affect performance if indexes on the keys are rendered non-sargable. Apply such techniques judiciously and consider their impact on query optimization.
2. Explicitly Handling NULLs in Join Conditions
Another method involves explicitly specifying conditions to account for NULL values. Rather than transforming the values, this approach checks for both equality and the condition where both columns are NULL.
SELECT *
FROM tableA A
INNER JOIN tableB B
ON (A.key = B.key OR (A.key IS NULL AND B.key IS NULL));This explicit approach ensures that rows with NULL values in join columns can be correctly matched, particularly in scenarios where NULLs represent equivalent missing data rather than distinct cases.
3. Leveraging Outer Joins to Include NULLs
Outer joins, such as LEFT, RIGHT, and FULL OUTER JOIN, are specifically designed to handle situations where one side of the join contains NULL values in key columns. These joins return all rows from one table even when there is no corresponding match in the other table. This characteristic makes them highly useful when it is important to include incomplete data sets in the result.
4. Optimizing Table Design and Data Model
The best practice is to design tables in a manner that minimizes the occurrence of NULL values in key columns that are critical for joins. If your data model can be adjusted so that join columns do not contain NULLs, the entire join logic can be greatly simplified, and performance can be enhanced.
In cases where NULLs are unavoidable, consider using surrogate keys or other non-nullable identifiers in the join to maintain consistency and performance across your database operations.
5. Considering Performance Implications
While handling NULL values is essential for data accuracy, it is equally important to ensure that query performance is not compromised. When functions like COALESCE or explicit OR conditions are used, they can sometimes hinder the database's ability to utilize indexes effectively. Always test and optimize your queries to strike a balance between handling NULLs correctly and maintaining efficient performance.
Comparative Overview of Strategies
| Strategy | Advantages | Limitations |
|---|---|---|
| COALESCE/ISNULL Functions |
|
|
| Explicit NULL Checks |
|
|
| Outer Joins |
|
|
| Table Design Optimization |
|
|
Best Practices and Practical Considerations
Data Analysis and Preparation
It is essential to analyze your underlying data for the presence of NULL values before designing your join operations. Data cleaning (ETL processes) should ensure that NULLs are either addressed or explicitly documented so that the subsequent query logic can handle those cases correctly.
Documentation and Code Maintenance
Document the approach adopted for handling NULL values inside your SQL queries. This practice improves code maintainability, ensures that other developers understand the logic behind the join conditions, and helps in debugging and future modifications.
Testing Under Real-World Scenarios
Run comprehensive tests with realistic data sets to understand the impact of your join strategy on query performance and correctness. These tests help in evaluating whether the treatment of NULL values as missing data, unknown data, or placeholders is appropriate for the business logic.
References
-
Handling Null Values in SQL Joins - SQL Queries
- Handling NULL in SQL Joins - IT Trip
- Dealing with NULL Values in SQL Joins - Infinite JS
- Handling NULL Values in Join Key - Medium
- Join SQL Server Tables with NULL Values - MSSQLTips
Recommended Next Steps
Last updated March 27, 2025