
टैब्युलेटेड डेटा की व्याख्या
डेटा को संरचित और व्यवस्थित करने का एक प्रभावी तरीका
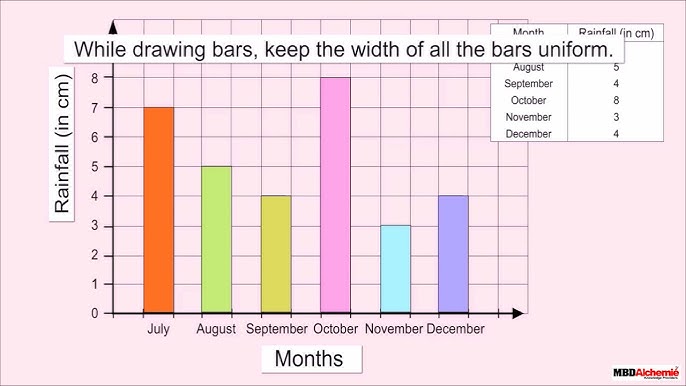
मुख्य बिंदु
- डेटा का स्पष्ट संगठन: टैब्युलेटेड डेटा पंक्तियों और स्तंभों में व्यवस्थित होता है, जिससे डेटा का विश्लेषण और तुलना सरल हो जाता है।
- समय, स्थान और संसाधन की बचत: इस विधि से बड़ी मात्रा में जानकारी को संक्षेप में प्रस्तुत किया जा सकता है, जिससे समय और संसाधनों की बचत होती है।
- आँकड़ों का संक्षिप्त और स्व-विवेकी प्रस्तुति: अच्छी तरह से डिज़ाइन की गई सारणियाँ अपने आप कथन करती हैं, जिससे अतिरिक्त स्पष्टीकरण की आवश्यकता नहीं पड़ती।
टैब्युलेटेड डेटा क्या है?
टैब्युलेटेड डेटा, जिसे हिंदी में "सारणीबद्ध डेटा" या "सारणीकृत डेटा" कहा जाता है, डेटा को पंक्तियों (rows) और स्तंभों (columns) में व्यवस्थित करने की एक प्रक्रिया है। यह तरीका डेटा के विभिन्न अवयवों को स्पष्ट रूप से दिखाने, उनका तुलनात्मक अध्ययन करने, और आवश्यक विश्लेषण करने में मदद करता है। टैब्युलेटेड डेटा का मुख्य उद्देश्य डेटा को समझने और व्याख्या करने में आसानी प्रदान करना है।
जब विभिन्न डेटा पॉइंट्स को सारणीबद्ध करने की प्रक्रिया शुरू होती है, तो पहले डेटा को इकठ्ठा किया जाता है, फिर उसे श्रेणियों में विभाजित किया जाता है और अंततः एक टेबल के रूप में प्रस्तुत किया जाता है। प्रत्येक पंक्ति एक विशिष्ट अवलोकन (observation) का प्रतिनिधित्व करती है और प्रत्येक स्तंभ उस अवलोकन की विशेषताओं (attributes) को प्रदर्शित करता है। इसका परिणाम यह होता है कि डेटा आसानी से तुलना किया जा सकता है और समग्र निष्कर्षों पर पहुँचा जा सकता है।
टैब्युलेटेड डेटा के मुख्य तत्व
पंक्तियाँ (Rows)
पंक्तियाँ वे क्षैतिज श्रेणियाँ होती हैं जिनमें प्रत्येक पंक्ति एक विशेष डेटा अवलोकन या इकाई का प्रतिनिधित्व करती है। उदाहरण के लिए, अगर आप विभिन्न छात्रों की जानकारी सारणीबद्ध कर रहे हैं, तो प्रत्येक पंक्ति में एक छात्र का डेटा होगा। प्रत्येक पंक्ति में छात्र का नाम, उम्र, कक्षा, और अन्य विवरण शामिल हो सकते हैं।
स्तंभ (Columns)
स्तंभ वे ऊर्ध्वाधर श्रेणियाँ होती हैं जो विभिन्न मापदंडों या चर (variables/attributes) को प्रदर्शित करती हैं। ऊपर दिए गए उदाहरण के अनुसार, छात्रों की सारणी में स्तंभों में नाम, उम्र, कक्षा आदि शामिल हो सकते हैं। प्रत्येक स्तंभ एक निश्चित विशेषता के बारे में जानकारी प्रदान करता है।
शीर्षक (Headings)
प्रत्येक टैब्युलेटेड डेटा तालिका में शीर्षक होते हैं जो पंक्तियों और स्तंभों का वर्णन करते हैं। ये शीर्षक सारणी की संरचना को स्पष्ट बनाते हैं और उपयोगकर्ता को यह समझने में मदद करते हैं कि तालिका में किस प्रकार का डेटा मौजूद है। स्पष्ट शीर्षक तालिका को स्व-विवेकी बनाते हैं, जिससे अतिरिक्त स्पष्टीकरण की आवश्यकता कम हो जाती है।
टेबल नंबर और शीर्षक
बड़ी रिपोर्ट्स या शोध कार्यों में, तालिकाओं को क्रमांकित किया जाता है और प्रत्येक तालिका के साथ एक संक्षिप्त शीर्षक दिया जाता है। इससे पाठकों को संदर्भित डेटा को पहचानने और समझने में सहायता मिलती है।
टैब्युलेटेड डेटा के लाभ
टैब्युलेटेड डेटा का प्रयोग न केवल सूचना को व्यवस्थित करने के लिए किया जाता है, बल्कि इसके कई व्यावहारिक लाभ भी होते हैं:
स्पष्टता और अनुक्रमण
यह विधि डेटा को स्पष्ट रूप से संरेखित करती है, जिससे बारीकियों और विशिष्टताओं को आसानी से समझा जा सकता है। एक स्पष्ट और सुव्यवस्थित तालिका पाठकों को डेटा के बीच छिपे जुड़े संबंधों को समझने में मदद करती है।
तुलनात्मक अध्ययन
टैब्युलेटेड डेटा का सबसे महत्वपूर्ण लाभ यह है कि यह विभिन्न डेटा पॉइंट्स का तुलनात्मक अध्ययन करना सरल बनाता है। अलग-अलग पंक्तियों या स्तंभों में मौजूद आंकड़ों की तुलना की जा सकती है और इस तरह महत्वपूर्ण निष्कर्ष निकाले जा सकते हैं। विशेषकर सांख्यिकीय आँकड़ों या बिजनेस रिपोर्ट्स में, यह विशेष महत्व रखता है।
संकलन और विश्लेषण में आसानी
टैब्युलेटेड डेटा को डाटा विश्लेषण टूल्स और सांख्यिकीय सॉफ़्टवेयर द्वारा आसानी से प्रोसेस किया जा सकता है। इसे ग्राफ़्स, चार्ट्स, और अन्य विज़ुअल रिप्रेज़ेंटेशन्स में बदला जा सकता है, जिससे सूचना को और अधिक प्रभावशाली तरीके से प्रस्तुत किया जा सके।
स्थान और समय की बचत
जब हम बड़ी मात्रा में डेटा को सारणीबद्ध करते हैं, तो इसे समझने, संपादित करने और विश्लेषण करने में लगने वाला समय कम होता है। यह विशेष रूप से तब उपयोगी होता है जब डेटा में दोहराव या समान पैटर्न पर ध्यान देना होता है।
स्व-विवेकी प्रस्तुति
एक अच्छी तरह से डिजाइन की गई टैब्युलेटेड डेटा तालिका स्व-व्याख्यात्मक होती है, जिसका अर्थ है कि इसमें प्रयुक्त शीर्षक और लेबल स्वयं ही डेटा के अर्थ को स्पष्ट करते हैं। इसलिए, उपयोगकर्ता को अतिरिक्त स्पष्टीकरण की आवश्यकता नहीं रहती।
टैब्युलेटेड डेटा का अनुप्रयोग
टैब्युलेटेड डेटा का उपयोग विभिन्न क्षेत्रों में किया जाता है, जैसे:
- शिक्षा: परीक्षा के परिणाम, छात्रों के आंकड़ें और शोध पत्रों में डेटा को प्रस्तुत करने के लिए।
- बिजनेस: वित्तीय रिपोर्ट, स्टॉक मार्केट विश्लेषण, और विपणन अनुसंधान में।
- वैज्ञानिक अनुसंधान: प्रयोग परिणाम, सांख्यिकीय सर्वेक्षण और डेटा विश्लेषण के परिणामों को सारणीबद्ध करने के लिए।
- सामाजिक विज्ञान: जनसंख्या से जुड़े आँकड़े, मतदान परिणाम और अन्य समाजशास्त्रीय डेटा।
एक उदाहरण
मान लीजिए कि एक विद्यालय में छात्रों की जानकारी को सारणीबद्ध किया जाना है। निम्न तालिका में छात्रों का नाम, कक्षा, आयु और अंक दर्शाये गए हैं:
| क्रम संख्या | छात्र का नाम | कक्षा | आयु | अंक |
|---|---|---|---|---|
| 1 | आनंद | 10वी | 15 | 87 |
| 2 | पूजा | 10वी | 16 | 92 |
| 3 | सुरेश | 9वी | 14 | 78 |
| 4 | राधिका | 10वी | 15 | 85 |
इस तालिका में, प्रत्येक पंक्ति एक छात्र का विवरण प्रस्तुत करती है, जबकि स्तंभ अलग-अलग विश्लेषणात्मक आयाम (नाम, कक्षा, आयु, और अंक) को प्रदर्शित करते हैं। तालिका में प्रयुक्त शीर्षक व लेबल स्व-स्पष्टीकरण प्रदान करते हैं, जिससे डेटा का अर्थ तुरंत समझ में आ जाता है।
अध्ययन के विभिन्न पहलू
डेटा संग्रहण के बाद प्रक्रिया
डेटा संग्रहण के बाद, सबसे पहली प्रक्रिया इसे वर्गीकृत करना होती है। इस चरण में विभिन्न प्रकार के डेटा पॉइंट्स की पहचान की जाती है, और उन्हें उपयुक्त श्रेणियों में बांटा जाता है। इसके बाद, डेटा को सारणीबद्ध किया जाता है। सारणीबद्ध करने की प्रक्रिया में ध्यान रखना होता है कि डेटा स्पष्ट, संक्षिप्त, और स्व-स्पष्टीकरण प्रदान करने वाला हो।
विश्लेषण और तुलना
सारणीबद्ध डेटा उपयोगकर्ताओं को विभिन्न मापदंडों के बीच तुलना करने की सुविधा प्रदान करता है। जब डेटा को पंक्तियों और स्तंभों में व्यवस्थित किया जाता है, तो संबंधों को स्थापित करना, परिमाणक विश्लेषण करना, और विपरीत पहचानों की पहचान आसान हो जाती है। यह विशेष रूप से सांख्यिकीय आँकड़ों और वित्तीय रिपोर्टों में अत्यंत लाभकारी सिद्ध होता है।
स्व-विवेकी तालिकाएँ
एक सफल टैब्युलेटेड डेटा तालिका में स्व-विवेकी होने की विशेषता होती है। स्व-विवेकी तालिकाएँ ऐसे शीर्षक और लेबल्स का प्रयोग करती हैं जो डेटा के अर्थ को बिना किसी अतिरिक्त स्पष्टीकरण के स्पष्ट करते हैं। यह गुण शोधकर्ताओं, शिक्षकों, और बिजनेस एनालिस्ट्स के बीच बहुत प्रचलित है, क्योंकि इससे सूचना का स्पष्टीकरण तुरंत हो जाता है।
अन्य महत्वपूर्ण विशेषताएँ
टेबल को डिज़ाइन करते समय कुछ अन्य तकनीकी और उपयोगगत विशेषताओं का ध्यान रखना आवश्यक होता है:
संपादन की जटिलता
टैब्युलेटेड डेटा का सबसे बड़ा लाभ यह है कि इसे संशोधित और अपडेट करना अपेक्षाकृत आसान होता है। बार-बार परीक्षण और विश्लेषण के दौरान, डेटा में मामूली बदलाव करने के लिए तालिका एक सुविधाजनक माध्यम है।
कालक्रमीय डेटा का निरूपण
जब किसी विषय पर समय के साथ परिवर्तन को दर्शाना हो, जैसे कि आर्थिक वृद्धि या जनसंख्या वृद्धि, तब सारणीबद्ध डेटा द्वारा अलग-अलग समयबिंदुओं के आंकड़ों की तुलना करना संभव होता है। इससे ट्रेंड्स और पैटर्न की पहचान में आसानी होती है।
डेटा की सटीकता और पूर्णता
सारणीबद्ध डेटा का एक और महत्वपूर्ण पहलू यह है कि डेटा को प्रस्तुत करने से पहले उसका सत्यापन और सटीकता सुनिश्चित करना चाहिए। डेटा का ऑडिट और सत्यापन यह सुनिश्चित करता है कि एकत्रीकरण के बाद तालिका में मौजूद सूचनाएँ विश्वसनीय हैं।
डेटा प्रदर्शन की उपयोगिता
सफल डेटा प्रदर्शन के दो मुख्य पहलू होते हैं: उपयोगकर्ता के लिए आसानी से समझ में आने वाला स्वरूप और निरंतरता। उदाहरण के लिए, शिक्षा से जुड़े परियोजनाओं में, जहाँ बहुल आँकड़ों का विश्लेषण किया जाता है, सारणीबद्ध डेटा शोधकर्ताओं को अपने निष्कर्षों को प्रस्तुत करने में अत्यधिक लाभ पहुंचाता है। वित्तीय रिपोर्टिंग में भी यह विधि निवेशकों और प्रबंधकों के लिए आंकड़ों का सर्वोत्तम निरूपण प्रस्तुत करती है।
इस तरह के स्व-विवेकी डेटा टेबल्स का प्रयोग करके, शोधकर्ता न केवल आंकड़ों में निहित पैटर्न को समझ पा जाते हैं बल्कि परिणामों की व्याख्या भी सरलता से कर लेते हैं। चाहे वह जनसांख्यिकीय डेटा हो या आर्थिक रिपोर्ट, तालिकाओं का प्रयोग करके डेटा के भीतर की जटिलताओं को भी उजागर किया जा सकता है।
व्यावहारिक उदाहरण एवं अनुप्रयोग
टैब्युलेटेड डेटा का प्रयोग वास्तविक जीवन के कई क्षेत्रों में किया जाता है। उदाहरण के लिए, एक सरकारी सर्वेक्षण में, विभिन्न क्षेत्रों के जनसंख्या आँकड़ों को सारणीबद्ध किया जाता है ताकि क्षेत्रीय तुलनाएँ की जा सकें। इसी प्रकार, बिजनेस के नुस्खे में, बिक्री के आँकड़े, वित्तीय बजट और खर्चों का विश्लेषण करने के लिए टैब्युलेटेड डेटा का अत्यधिक प्रयोग होता है।
एक और उदाहरण के रूप में, एक वैज्ञानिक अध्ययन में प्रयोगों के परिणामों को सारणीबद्ध किया जाता है। उपरोक्त परिणामों को आमतौर पर एक संरचित तालिका में व्यवस्थित किया जाता है, जिससे उन परिणामों के बीच संबंधों और अंतरों को आसानी से विश्लेषित किया जा सकता है। शोध में इस विधि से पता चलता है कि डेटा का स्पष्ट और संरचित निरूपण शोध निष्कर्षों की विश्वसनीयता को बढ़ाता है।
संदर्भ और अतिरिक्त संसाधन
निम्नलिखित URL टैब्युलेटेड डेटा के बारे में अधिक जानकारी और उदाहरण प्रदान करते हैं, जो कि शिक्षकों, शोधकर्ताओं, बिजनेस एनालिस्ट्स और छात्रों के लिए अत्यंत उपयोगी हैं:
- Vedantu - Tabulation in Commerce
- Unacademy - Tabulation of Data
- Testbook - Tabulation in Maths
- Statology - Tabular Data Concepts
-
Shabdkosh - Tabulated Data
उपयोगकर्ता की गहरी समझ के लिए अन्य प्रश्न
यदि आप टैब्युलेटेड डेटा के बारे में और अधिक जानना चाहते हैं, तो निम्नलिखित प्रश्नों पर विचार करें, जो इस विषय के विभिन्न पहलुओं को उजागर कर सकते हैं:
Last updated March 16, 2025