
Unveiling the Best Open-Source AI Video Creators of 2025: A Deep Dive
Explore top text-to-video models, their licenses, commercial potential, and capabilities available today.
Highlights
- Leading Models Compared: Discover detailed comparisons of top open-source text-to-video models like HunyuanVideo, Open-Sora, CogVideo, Wan2.1, Text2Video-Zero, and Mochi 1.
- Commercial Freedom: Understand the licensing (often Apache 2.0 or MIT) and commercial usage rights, highlighting the potential for free integration into business projects.
- Performance vs. Accessibility: Learn about the trade-offs between model size (from ~1B to 13B parameters), video quality, computational requirements, and ease of use.
The Open-Source Text-to-Video Revolution in 2025
The field of artificial intelligence is rapidly transforming video creation. As of May 2025, open-source text-to-video models are not just catching up to their proprietary counterparts like OpenAI's Sora or Google's Lumiere; they are carving out significant niches by offering powerful, accessible, and customizable tools. This democratization allows creators, researchers, and businesses to generate compelling video content directly from text prompts without hefty subscription fees or restrictive licenses. These models vary significantly in their architecture, training data, performance, and intended use cases, making a careful comparison essential.
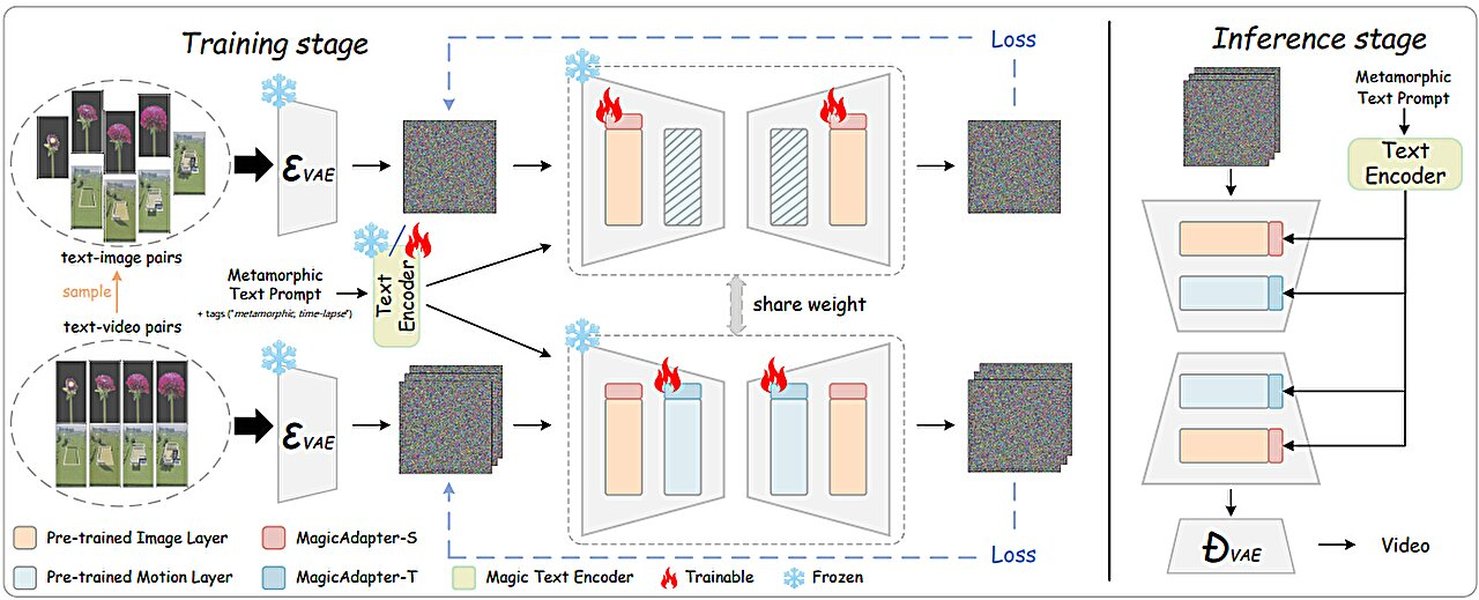
The field of AI text-to-video generation is blossoming with new capabilities in 2025.
Key Factors for Comparison
When evaluating these open-source models, several factors are crucial:
- License: Determines how the software can be used, modified, and distributed. Permissive licenses like Apache 2.0 and MIT are common, generally allowing broad use.
- Commercial Usage Rights: Specifies whether the model can be used for commercial purposes (e.g., marketing videos, monetized content). Most permissive open-source licenses allow this, often requiring only attribution.
- Model Size (Parameters): Indicates the model's complexity and potential capability. Larger models (billions of parameters) often produce higher quality results but require more computational resources (GPU memory, processing power).
- Features & Performance: Includes aspects like video resolution, frame rate, motion accuracy, coherence, speed of generation, and support for specific styles or tasks (e.g., image-to-video, video editing).
- Accessibility & Ease of Use: Considers factors like documentation quality, community support, integration with platforms (like ComfyUI), and hardware requirements.
Comparing the Leading Models
The following table provides a comparative overview of some of the most prominent open-source text-to-video models available as of May 2025. Keep in mind that this field evolves rapidly, and specifics should always be double-checked with the model's official repository or documentation.
| Model Name | Approx. Model Size (Parameters) | Typical License | Commercial Use Allowed? | Key Features & Strengths |
|---|---|---|---|---|
| HunyuanVideo | 13 Billion | Apache 2.0 | Yes (with attribution) | High performance, cinematic quality, multi-tasking (T2V, I2V, editing), multilingual (English/Chinese), relatively fast, efficient VRAM usage (scales 8GB-48GB). |
| Open-Sora | Variants (e.g., 1 Billion, 11 Billion) | Permissive (e.g., MIT, Apache 2.0) | Yes (with attribution) | Fully open-source framework, democratizes video production, scalable, efficient training, community-driven, checkpoints available. |
| CogVideo | ~5 Billion (CogVideoX-5B variant) | Permissive (e.g., MIT, Apache 2.0) | Yes (with attribution) | High-quality output, cinematic realism, transformer-based, good for detailed generation, can run locally. |
| Wan2.1 (WanVideo) | Lightweight/Efficient (exact size not specified) | Likely Permissive (e.g., Apache 2.0) | Yes (with attribution) | Versatile (T2V, I2V), integrated into ComfyUI, good performance, seamless video, efficient. Developed by Alibaba. |
| Text2Video-Zero | ~1-2 Billion (Leverages base models) | Permissive (e.g., MIT, Apache 2.0) | Yes (with attribution) | Flexible, builds on text-to-image models, efficient fine-tuning with limited data, good motion consistency. |
| Mochi 1 | Lightweight/Efficient (exact size not specified) | Implied Permissive (check source) | Implied Yes (check source) | Developed by Genmo AI, optimized for ease of use, ComfyUI integration, balanced quality and accessibility, good for rapid prototyping. |
| AMD Hummingbird-0.9B | ~0.9 Billion (945 Million) | Permissive (AMD specific) | Yes (with attribution) | Highly efficient, low computational demand, optimized for faster inference, reasonable quality for size. |
Deeper Dive into Top Contenders
HunyuanVideo: The High-Performance Titan
With 13 billion parameters, HunyuanVideo stands out as a powerhouse in the open-source arena. Developed by Tencent and released under the permissive Apache 2.0 license, it rivals proprietary models in quality. Its strengths lie in generating high-fidelity, cinematic videos with excellent motion accuracy. Beyond simple text-to-video, it handles image-to-video, video editing, and even text-to-image tasks. It's noted for being significantly faster than some competitors and supports both English and Chinese prompts. While powerful, its size necessitates capable hardware, though it can run on systems with as little as ~8GB VRAM, scaling up for complex tasks.
Open-Sora: Democratizing Video Generation
Open-Sora isn't just a single model but a comprehensive, fully open-source project aiming to replicate and democratize capabilities similar to OpenAI's Sora. It offers various model sizes, including a 1.3 billion parameter version for accessibility and an 11 billion parameter version (Open-Sora 2.0) competing with high-end models like HunyuanVideo. The project provides open checkpoints and training code under permissive licenses, fostering community development and allowing complete customization. Its scalability makes it adaptable to different hardware setups and project needs, embodying the spirit of open-source collaboration in AI video.
CogVideo: Cinematic Quality Focus
CogVideo, often mentioned alongside its CogVideoX variants (like the 5B parameter version), utilizes a large transformer architecture to generate high-quality, detailed videos from text. It's recognized for its ability to produce outputs with cinematic realism. Being open-source (typically under permissive licenses like MIT or Apache 2.0), it allows for local deployment, giving users more control and privacy. While it delivers impressive visual fidelity, it generally requires substantial computational resources, making it suitable for users with access to powerful GPUs.
Wan2.1: Versatility and Efficiency
Developed by Alibaba as part of the WanVideo suite, Wan2.1 is praised for its versatility, performing well in both text-to-video and its renowned image-to-video capabilities. It's known for being lightweight and efficient, making it accessible on more standard hardware setups. Integration into popular frameworks like ComfyUI further enhances its usability for creators. Its likely permissive open-source license (e.g., Apache 2.0) allows for flexible commercial use, making it a practical choice for various video production workflows.
Wan2.1 is noted for its performance in image-to-video and text-to-video generation.
Text2Video-Zero: Flexibility from Images
Text2Video-Zero takes a slightly different approach. Instead of being trained end-to-end on massive video datasets, it cleverly adapts existing pretrained text-to-image diffusion models (like Stable Diffusion) for video generation with minimal video-specific training. This makes it flexible and relatively efficient to adapt. It excels at maintaining consistency and motion, producing coherent short clips. Its open-source nature (MIT/Apache 2.0 licenses) and smaller effective size (~1-2B parameters, relying on the base image model) make it ideal for experimentation and customization.
Mochi 1: Balanced Accessibility
Developed by Genmo AI, Mochi 1 is presented as a user-friendly and efficient open-source text-to-video model. It's often integrated into workflows like ComfyUI, suggesting a focus on practical usability. While potentially not matching the absolute peak quality of giants like HunyuanVideo, Mochi 1 aims for a balance between good fidelity, reasonable speed (targeting fluid motion), and accessibility on less powerful hardware. Its open-source status (likely under a permissive license) makes it an attractive option for creators and developers looking for a readily usable solution for prototyping or content generation.
Visualizing Model Characteristics
This radar chart offers a visual comparison of key characteristics across several top open-source text-to-video models based on the synthesized information. The scores (out of 10) are relative estimates reflecting general consensus and reported strengths: Video Quality (fidelity, resolution, coherence), Speed (generation time), Resource Needs (lower score means higher needs - inverse scale for clarity), Ease of Use (setup, integration, documentation), Feature Set (multi-tasking, editing), and License Permissiveness (freedom for commercial use, modification).
Understanding the Ecosystem
This mindmap illustrates the key aspects surrounding open-source text-to-video models in 2025, connecting the models themselves to their core characteristics, licensing implications, and typical applications.
Affects quality & resources"] Performance["Performance
Quality, Speed, Coherence"] Features["Features
T2V, I2V, Editing, Multilingual"] Resources["Resource Needs
GPU VRAM, Compute Power"] Accessibility["Accessibility
Ease of Use, Integration (ComfyUI)"] Licensing["Licensing & Usage"] LicenseTypes["Common Licenses
Apache 2.0, MIT"] Permissive["Permissive Nature
Freedom to use, modify, distribute"] CommercialUse["Commercial Use
Generally allowed (check terms!)"] Attribution["Attribution
Often required"] Applications["Applications & Benefits"] Democratization["Democratization
Wider access to tools"] Customization["Customization
Adaptable to specific needs"] CostEffective["Cost-Effective
No subscription fees"] Innovation["Innovation
Community-driven development"] UseCases["Use Cases
Marketing, Content Creation, Research, Prototyping"]
Licensing and Commercial Use Explained
Permissive Licenses (Apache 2.0, MIT)
Most of the leading open-source text-to-video models discussed (like HunyuanVideo and potentially Open-Sora, CogVideo, Wan2.1, Text2Video-Zero) are released under permissive licenses such as Apache 2.0 or the MIT License. These licenses grant users significant freedom:
- Usage: You can use the software for any purpose, including commercial projects.
- Modification: You can modify the source code to suit your needs.
- Distribution: You can distribute the original or modified versions of the software.
The primary requirement is usually **attribution** – you must retain the original copyright notices and license text in your distributions. Unlike copyleft licenses (like GPL), permissive licenses generally do not require you to release your own modifications under the same open-source terms. This makes them highly attractive for businesses wanting to integrate AI video generation into proprietary products or services.
Important Note: While this is the general trend, always verify the specific license attached to the exact version of the model you intend to use by checking its official repository (e.g., on GitHub or Hugging Face).
Why Open Source Matters
The rise of powerful open-source text-to-video models offers several advantages:
- Accessibility: Removes cost barriers associated with proprietary software.
- Transparency: Allows researchers and developers to inspect, understand, and build upon the model's architecture.
- Customization: Enables fine-tuning on specific datasets or modification for unique use cases.
- Innovation: Fosters a collaborative environment where the community can rapidly improve the technology.
- Control: Permits local deployment, offering greater data privacy and control over the generation process.
Integrating into Workflows: A Practical Look
Many open-source models gain popularity through integration with user-friendly interfaces and workflow managers like ComfyUI. This allows creators to chain different models and processes together visually, simplifying the creation of complex AI-generated content. The video below demonstrates using Wan2.1 within ComfyUI, showcasing a practical application of these open-source tools for generating video content.
This video provides a tutorial on using the Wan2.1 model, noted for its efficiency, within the popular ComfyUI framework for AI video generation.
Frequently Asked Questions (FAQ)
Which open-source model is best for high-quality cinematic video?
Can I use these models commercially for free?
What hardware do I need to run these models?
Are there open-source models better than OpenAI's Sora?
How fast is the development in this field?
Recommended Further Exploration
- Explore guides on setting up and running top open-source video models on your own hardware.
- Discover different ComfyUI setups for optimizing text-to-video workflows with models like Wan2.1 or Mochi 1.
- Investigate the ethical implications and copyright landscape surrounding the use of AI video generators.
- Learn about anticipated advancements and future directions in the open-source AI video space.
References
Last updated May 5, 2025