
Understanding Graph RAG: An In-Depth Exploration
Enhancing Retrieval-Augmented Generation with Knowledge Graphs
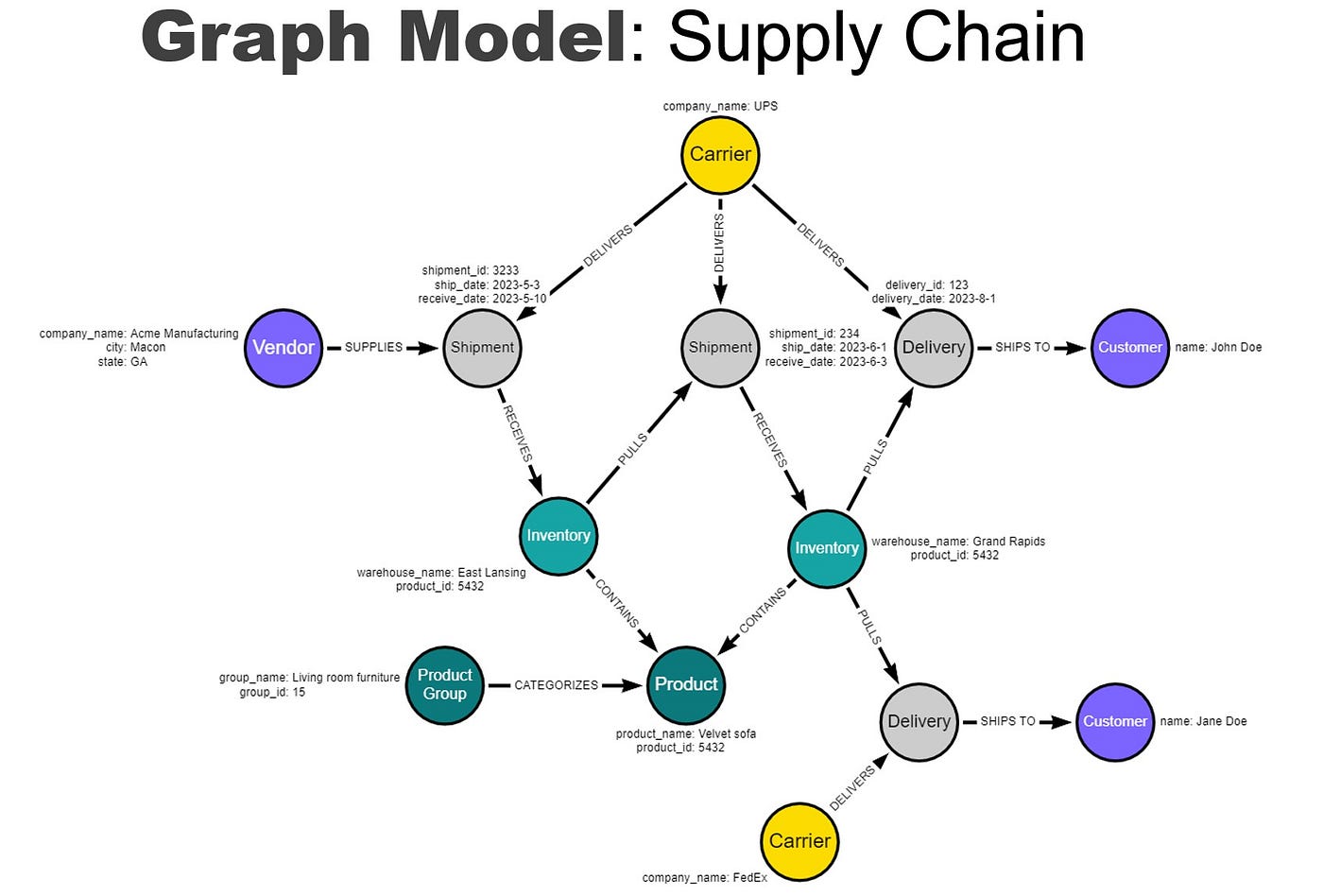
Key Takeaways
- Integration of Knowledge Graphs: Graph RAG leverages structured knowledge graphs to enhance the retrieval process, enabling more accurate and contextually relevant responses.
- Enhanced Multi-Hop Reasoning: By utilizing the interconnected nature of graphs, Graph RAG improves the model's ability to perform complex reasoning across multiple pieces of information.
- Improved Explainability and Scalability: The structured retrieval process offers better transparency and can efficiently handle complex queries in specialized domains.
Introduction to Graph RAG
Graph RAG, or Graph Retrieval-Augmented Generation, represents a significant advancement in the field of natural language processing and artificial intelligence. Building upon the foundational principles of Retrieval-Augmented Generation (RAG), Graph RAG incorporates knowledge graphs to enhance the retrieval and generation phases, resulting in more accurate, contextually rich, and reliable responses. This comprehensive approach addresses some of the limitations inherent in traditional generative models, particularly in handling complex queries and reducing factual inaccuracies.
Core Architecture of Graph RAG
The architecture of Graph RAG is a sophisticated integration of multiple components designed to work in harmony to deliver enhanced performance. The primary components include the Knowledge Graph, Graph Database, and Large Language Models (LLMs).
Knowledge Graph
A knowledge graph is a structured representation of knowledge, where entities are depicted as nodes, and the relationships between them are represented as edges. This structure allows for the capturing of complex interrelations between different pieces of information, providing a rich contextual backdrop for retrieval and generation processes.
Graph Database
The graph database serves as the storage and retrieval mechanism for the knowledge graph. It is optimized for querying and handling the interconnected data efficiently. By utilizing graph-specific query languages like Cypher or Gremlin, the database can execute complex queries that traverse the graph to fetch relevant subgraphs based on user inputs.
Large Language Models (LLMs)
LLMs, such as GPT-4, are at the heart of the generation phase. They process the retrieved information from the knowledge graph, synthesizing it to produce coherent and contextually appropriate responses. The integration with a structured knowledge base helps mitigate issues like hallucinations, where models generate plausible but factually incorrect information.
Operational Workflow of Graph RAG
The functionality of Graph RAG can be broken down into several key phases: Knowledge Graph Construction, Query Processing, Graph-Guided Retrieval, Integration with Vector Databases, and Response Generation. Each phase plays a critical role in ensuring the system's overall efficacy.
1. Knowledge Graph Construction
The initial phase involves building a comprehensive knowledge graph from diverse data sources. This process typically includes:
- Entity and Relationship Extraction: Utilizing tools like Named Entity Recognition (NER) and large language models to identify and extract entities (e.g., people, organizations, concepts) and the relationships between them from unstructured text.
- Graph Formation: Structuring the extracted entities and relationships into a graph format, enabling semantic connections and facilitating efficient retrieval.
- Hierarchical Clustering: Organizing the graph into hierarchical clusters to optimize retrieval efficiency and manageability, especially for large datasets.
2. Query Processing
Upon receiving a user query, the system undertakes a series of steps to interpret and process it:
- Query Understanding: Analyzing the query to identify key entities and the nature of the requested information.
- Subgraph Extraction: Translating the user query into graph-based queries that can navigate the knowledge graph to retrieve relevant subgraphs.
3. Graph-Guided Retrieval
Instead of performing a simple keyword search, Graph RAG leverages the structure of the knowledge graph to perform contextual retrieval:
- Node Identification: Selecting nodes directly related to the query entities.
- Path Exploration: Traversing edges to discover indirect relationships, enabling multi-hop reasoning and the retrieval of contextually linked information.
- Ranking and Selection: Employing graph algorithms (e.g., centrality measures, clustering) to rank and select the most relevant subgraphs for response generation.
4. Integration with Vector Databases
While the knowledge graph provides structured relational data, vector databases are employed to perform semantic searches over unstructured text. This dual approach ensures that both structured and unstructured information are harnessed effectively, enhancing the richness and accuracy of the retrieved data.
5. Response Generation
The final phase involves synthesizing the retrieved information to generate a coherent and contextually appropriate response:
- Contextual Understanding: The LLM analyzes the retrieved subgraphs and associated data to comprehend the full context of the query.
- Content Generation: Using the enriched context, the LLM generates a response that is factually accurate and contextually relevant, minimizing the risk of hallucinations.
Advantages of Graph RAG Over Traditional RAG
Graph RAG offers several distinct advantages compared to traditional RAG approaches, primarily stemming from its integration of knowledge graphs:
1. Enhanced Contextual Retrieval
The use of knowledge graphs allows Graph RAG to understand and navigate the relationships between entities, enabling the retrieval of more contextually relevant information. This interconnected retrieval mechanism supports more nuanced and comprehensive responses.
2. Improved Multi-Hop Reasoning
Graph structures facilitate multi-hop reasoning by enabling the system to traverse multiple relationships within the graph. This capability allows for more complex and insightful answers, especially for queries that require understanding the interplay between various entities.
3. Reduced Hallucinations
By grounding responses in structured knowledge from the graph, Graph RAG significantly reduces the occurrence of hallucinations—instances where the model generates plausible but factually incorrect information.
4. Enhanced Explainability
The transparent nature of graph-based retrieval processes allows for better explainability. Users and developers can trace how specific pieces of information were retrieved and used in generating responses, facilitating debugging and validation.
5. Scalability and Adaptability
Knowledge graphs can be dynamically updated with new information without necessitating retraining of the entire model. This adaptability makes Graph RAG scalable for applications in rapidly evolving domains such as healthcare, finance, and technology.
Applications of Graph RAG
Graph RAG's advanced retrieval and generation capabilities make it suitable for a wide range of applications across various industries:
1. Healthcare
In the healthcare sector, Graph RAG can be utilized to synthesize information from vast medical databases, enabling accurate and comprehensive responses to complex medical queries. It can assist in diagnosing diseases by connecting symptoms, treatments, and patient history.
2. Legal Document Verification
Graph RAG can streamline the process of legal document verification by traversing interconnected legal statutes, case laws, and precedents to provide contextually accurate analyses and summaries.
3. Recommendation Systems
By understanding the relationships between different entities (e.g., products, users, preferences), Graph RAG can enhance recommendation systems, offering more personalized and relevant suggestions.
4. Scientific Research
Graph RAG can aid researchers by aggregating and synthesizing information from diverse scientific studies, facilitating multi-hop reasoning to uncover new insights and hypotheses.
5. Telecommunications
In telecommunications, Graph RAG can manage and analyze complex network structures, improving troubleshooting processes and optimizing network performance through informed decision-making.
Challenges and Future Directions
Despite its numerous advantages, Graph RAG faces several challenges that need to be addressed to fully realize its potential:
1. Building and Maintaining High-Quality Knowledge Graphs
Creating a comprehensive and accurate knowledge graph requires significant effort in data extraction, entity recognition, and relationship mapping. Ensuring the graph remains up-to-date with evolving information is an ongoing challenge.
2. Computational Overhead
The processes involved in graph traversal, complex queries, and multi-hop reasoning can introduce substantial computational overhead. Optimizing these processes to maintain efficiency is crucial for real-time applications.
3. Balancing Retrieval and Generation
Ensuring that the generative models effectively utilize the retrieved graph-based information without being overwhelmed by irrelevant data requires careful tuning and balancing of the retrieval and generation phases.
4. Scalability
As the size and complexity of knowledge graphs grow, maintaining performance and scalability becomes increasingly difficult. Efficient data structures and query optimization techniques are essential to manage large-scale graphs.
5. Domain-Specific Adaptations
Different domains may require tailored approaches to knowledge graph construction and retrieval. Developing domain-specific adaptations while maintaining the system's generalizability is a complex task.
Graph RAG vs. Traditional RAG
| Feature | Traditional RAG | Graph RAG |
|---|---|---|
| Data Structure | Flat text corpora or unstructured data | Structured knowledge graphs with entities and relationships |
| Retrieval Method | Keyword-based or embedding-based search | Graph-based queries leveraging node and edge relationships |
| Contextual Understanding | Limited to isolated documents or passages | Enhanced through multi-hop reasoning and interconnected data |
| Explainability | Low, often black-box retrieval process | High, with transparent traversal of graph relationships |
| Scalability | Can handle large text corpora but lacks structural context | Efficiently manages complex queries in specialized domains |
| Use Cases | General-purpose question answering and content generation | Specialized applications requiring deep contextual understanding |
| Challenges | Handling unstructured data and ensuring factual accuracy | Building high-quality knowledge graphs and managing computational overhead |
Implementing Graph RAG: A Step-by-Step Guide
1. Building the Knowledge Graph
The first step involves constructing the knowledge graph from relevant data sources. This can be achieved through the following sub-steps:
- Data Collection: Aggregate data from various sources such as databases, documents, and APIs.
- Entity Extraction: Use Named Entity Recognition (NER) tools to identify and extract entities from the collected data.
- Relationship Mapping: Determine the relationships between extracted entities using relationship extraction methods.
- Graph Structuring: Organize entities and their relationships into a graph structure, ensuring semantic coherence.
- Clustering: Implement hierarchical clustering to group related entities, optimizing retrieval efficiency.
2. Query Transformation and Processing
When a user poses a query, the system must interpret and transform it into a format suitable for graph-based retrieval:
- Natural Language Processing: Parse the query to identify key entities and intent.
- Graph-Based Query Translation: Convert the natural language query into graph query languages like Cypher or Gremlin to navigate the knowledge graph.
3. Executing Graph-Guided Retrieval
With the transformed query, the system performs retrieval operations guided by the graph's structure:
- Subgraph Identification: Locate the relevant subgraphs that pertain to the query by traversing nodes and edges.
- Contextual Relevance: Evaluate the relevance of retrieved subgraphs based on their proximity and connectivity to the query entities.
- Aggregation: Compile the most pertinent subgraphs to form a comprehensive context for response generation.
4. Integrating with Vector Databases
To complement the structured retrieval from the knowledge graph, vector databases are utilized to perform semantic searches over unstructured text:
- Semantic Embeddings: Convert text data into vector embeddings that capture semantic meaning.
- Vector Search: Perform similarity searches to retrieve semantically relevant documents or passages.
- Dual Retrieval: Combine structured graph-based retrieval with vector-based semantic retrieval for enriched context.
5. Generating the Response
Finally, the Large Language Model synthesizes the retrieved information to formulate a coherent and accurate response:
- Contextual Integration: The LLM receives both the structured subgraphs and unstructured text from vector databases as input.
- Content Synthesis: The model processes the combined inputs to generate a response that is comprehensive and contextually aligned with the user's query.
- Output Refinement: Implement post-processing techniques to ensure grammatical correctness and factual accuracy.
Technical Considerations and Enhancements
To optimize the performance and reliability of Graph RAG systems, several technical considerations and enhancements can be implemented:
1. Advanced Graph Algorithms
Employing sophisticated graph algorithms can enhance retrieval accuracy and efficiency. Examples include:
- Shortest Path Algorithms: Identify the most direct relationships between entities.
- Centrality Measures: Determine the most influential nodes within the graph.
- Clustering and Community Detection: Group related entities to streamline retrieval processes.
2. Dynamic Knowledge Graphs
Implementing dynamic knowledge graphs that can be updated in real-time ensures that the system remains current with new information, enhancing its applicability in fast-evolving domains.
3. Hybrid Retrieval Strategies
Combining graph-based retrieval with traditional keyword or embedding-based methods can provide a more balanced and comprehensive retrieval strategy, catering to both structured and unstructured data needs.
4. Optimization for Computational Efficiency
To mitigate the computational overhead associated with graph traversal and complex queries, optimization techniques such as parallel processing, caching frequently accessed subgraphs, and efficient indexing can be employed.
5. User Feedback Integration
Incorporating user feedback mechanisms allows the system to learn and adapt, improving retrieval relevance and response accuracy over time through continuous learning.
Case Study: Graph RAG in Healthcare
To illustrate the practical application of Graph RAG, consider its implementation in the healthcare sector:
Scenario
A medical researcher seeks comprehensive information about the interactions between specific proteins involved in a particular disease. Traditional RAG systems might retrieve isolated documents or passages, providing fragmented information.
Graph RAG Implementation
- Knowledge Graph Construction: Assemble a knowledge graph from medical databases, research papers, and clinical trial data, mapping entities like proteins, genes, diseases, and their interrelations.
- Query Processing: The researcher's query is parsed to identify key proteins and the disease in question.
- Graph-Guided Retrieval: The system retrieves a subgraph that includes the target proteins, their interactions, related pathways, and associated clinical outcomes.
- Response Generation: The LLM synthesizes the retrieved subgraph to provide a detailed explanation of the protein interactions, their role in the disease mechanism, and potential therapeutic targets.
Benefits
- Comprehensive Insights: By leveraging the interconnected data, the researcher receives a holistic view of the protein interactions.
- Enhanced Accuracy: The structured retrieval minimizes the risk of overlooking critical interactions or misinterpreting data.
- Actionable Information: The synthesized response provides clear pathways for further research or clinical application.
Mathematical Representation of Graph RAG Processes
To formalize the processes involved in Graph RAG, mathematical representations can be employed:
Knowledge Graph Structure
A knowledge graph can be represented as \( G = (V, E) \), where:
-
\( V \) is the set of nodes representing entities.
-
\( E \) is the set of edges representing relationships between entities.
Graph-Based Query Retrieval
Given a user query \( Q \), the goal is to retrieve a relevant subgraph \( G' = (V', E') \) such that:
\[ V' \subseteq V \quad \text{and} \quad E' \subseteq E \]
Where \( G' \) captures the entities and relationships pertinent to \( Q \).
Response Generation
The response \( R \) generated by the LLM is a function of the retrieved subgraph and the original query:
\[ R = f(Q, G') \]
Where \( f \) represents the LLM's generation function conditioned on both \( Q \) and \( G' \).
Future Directions and Innovations
As AI continues to evolve, Graph RAG stands to benefit from several emerging trends and innovations:
1. Enhanced Integration with Multimodal Data
Incorporating multimodal data, such as images, audio, and video, into knowledge graphs can further enrich the retrieval process, enabling more comprehensive and versatile responses.
2. Advanced Reasoning Capabilities
Developing more sophisticated reasoning algorithms within Graph RAG can enhance its ability to perform complex inferences, making it applicable to even more intricate domains.
3. Real-Time Data Processing
Improving the system's ability to process and integrate real-time data ensures that responses remain current and relevant, particularly in fast-paced industries.
4. Personalized Knowledge Graphs
Creating personalized knowledge graphs tailored to individual user preferences and histories can facilitate more personalized and context-aware interactions.
5. Enhanced Security and Privacy Measures
Implementing robust security and privacy protocols ensures that sensitive information within knowledge graphs is protected, fostering trust and compliance with regulatory standards.
Conclusion
Graph RAG represents a transformative approach in the realm of retrieval-augmented generation, bridging the gap between unstructured data retrieval and structured knowledge representation. By integrating knowledge graphs into the retrieval process, Graph RAG not only enhances the accuracy and context of generated responses but also opens avenues for more sophisticated applications across various domains. While challenges such as graph construction and computational overhead remain, ongoing advancements in AI and data management promise to address these hurdles, paving the way for the widespread adoption of Graph RAG in the future.
References

Last updated February 3, 2025