
Unlocking the Power of Words: What Exactly is a Large Language Model (LLM)?
Dive deep into the technology that's revolutionizing how we interact with artificial intelligence and language.
A Large Language Model, commonly abbreviated as LLM, represents a sophisticated category of artificial intelligence (AI) algorithms specifically engineered for natural language processing (NLP) tasks. These models are built upon advanced neural network techniques, most notably deep learning and the transformative "Transformer" architecture. They are distinguished by their vast number of parameters, often numbering in the billions or even trillions, and are trained through self-supervised learning on immense datasets of text and code. This extensive training enables LLMs to comprehend, interpret, summarize, translate, predict, and generate human-like language with remarkable fluency.
Highlights: Key Insights into LLMs
- Sophisticated AI for Language: LLMs are advanced AI systems designed to understand, process, and generate human language using deep learning techniques.
- Massive Scale Training: They are trained on enormous datasets, often comprising trillions of words from diverse sources like books, articles, websites, and code, enabling them to learn intricate language patterns.
- Transformer Architecture at its Core: Most modern LLMs utilize the Transformer architecture, which employs "self-attention" mechanisms to weigh the importance of different words in a sequence, leading to better context understanding and coherent text generation.
- Diverse Capabilities: LLMs can perform a wide array of tasks, including text generation, translation between languages, summarization of lengthy documents, answering questions, writing code, and powering conversational AI.
What Exactly is a Large Language Model (LLM)?
At its heart, an LLM is a computational model that has learned the patterns, structures, and nuances of human language to an extraordinary degree. It functions by predicting the likelihood of a sequence of words, akin to a highly advanced auto-complete system, but with a far deeper understanding of context, semantics, and even style.

A visual illustrating the concept of a Large Language Model.
Defining the Digital Linguist
A Specialized Form of Artificial Intelligence
LLMs are a subset of machine learning and deep learning, representing a significant leap forward in AI's capacity to handle and manipulate language. They are not merely programmed with grammatical rules; instead, they learn these rules, along with countless other linguistic patterns, from the data they are fed. This allows them to generate text that is not only grammatically correct but also coherent, contextually relevant, and often indistinguishable from human writing.
The Scale of Knowledge: Parameters and Data
The "Large" in Large Language Model refers to two primary aspects: the sheer volume of data they are trained on and the number of parameters they possess. Parameters are essentially the internal variables or "knobs" that the model adjusts during training to minimize errors in its predictions. Modern LLMs can have hundreds of billions, or even trillions, of these parameters. The training datasets are equally colossal, encompassing vast swathes of the internet, digital libraries of books, scientific articles, and other textual sources. This scale is crucial for capturing the richness and complexity of human language.
The Engine Room: How LLMs Function
The operational mechanics of LLMs are rooted in sophisticated machine learning principles and a groundbreaking neural network architecture. Understanding these components is key to appreciating their capabilities.
The Learning Process: Self-Supervised Learning
Learning from Unlabeled Data
Most LLMs are trained using a technique called self-supervised learning. In this paradigm, the model learns from raw, unlabeled text data. A common training objective is to predict the next word in a sentence, given the preceding words. For example, if the model sees the phrase "The cat sat on the ___", it tries to predict "mat". By repeatedly performing this task on billions of examples, the model implicitly learns grammar, facts about the world (as described in the text), common sense reasoning, and even stylistic nuances.
Architectural Blueprint: The Transformer Model
The advent of the Transformer architecture in 2017 was a pivotal moment for NLP and the development of LLMs. This architecture is particularly effective at handling sequential data like text.
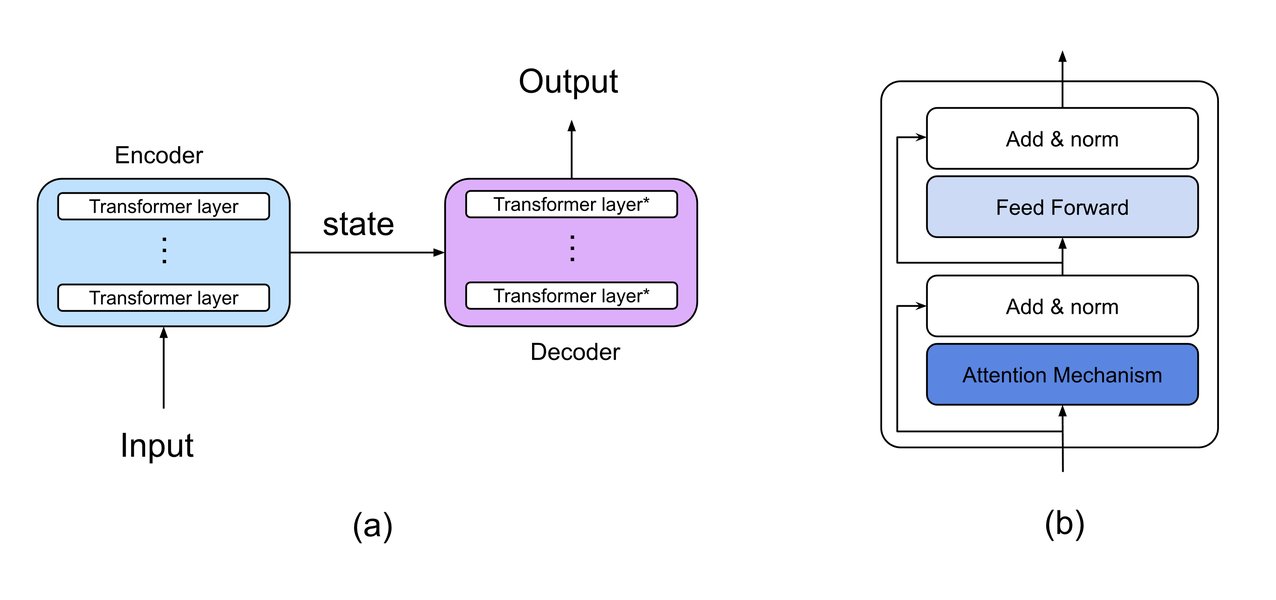
Illustration of the Transformer architecture, highlighting encoders, decoders, and attention mechanisms.
Self-Attention: The Focus Mechanism
A core component of the Transformer is the self-attention mechanism. This allows the model to weigh the importance of different words in an input sequence when processing any given word. For instance, when processing the word "it" in a sentence, the self-attention mechanism helps the model determine which noun "it" refers to by considering the entire context, even words that are distant in the sequence. This ability to capture long-range dependencies is crucial for understanding complex sentences and discourse.
Word Embeddings: Understanding Meaning
LLMs don't process words as simple strings of characters. Instead, they convert words and sub-word units (tokens) into numerical representations called "word embeddings." These embeddings are dense vectors in a high-dimensional space, where words with similar meanings or that appear in similar contexts are located closer to each other. For example, the embeddings for "king" and "queen" would have a relationship that mirrors the relationship between "man" and "woman." This numerical representation allows the model to perform mathematical operations that capture semantic relationships.
Encoders and Decoders
The original Transformer model consists of an encoder and a decoder. The encoder processes the input text sequence and creates a rich contextual representation. The decoder then uses this representation to generate an output sequence, word by word. Some LLMs, particularly those focused on understanding tasks (like BERT), might primarily use the encoder part, while generative models (like GPT) primarily use the decoder part. Many modern architectures, however, blend these concepts or use decoder-only architectures for generation.
Core Components and Concepts of LLMs: A Visual Map
To better visualize the interconnected elements that define a Large Language Model, the mindmap below outlines its fundamental aspects, from its basic definition and training methodologies to its capabilities and inherent limitations.
(Parameters & Data)"] id2b["Transformer Architecture"] id2c["Self-Supervised Learning"] id2d["Probabilistic Word Prediction"] id3["How They Work"] id3a["Training on Vast Corpora"] id3b["Self-Attention Mechanism"] id3c["Word Embeddings
(Numerical Representation)"] id3d["Encoder-Decoder Structure (or variants)"] id4["Capabilities"] id4a["Text Generation & Creative Writing"] id4b["Language Translation"] id4c["Summarization of Documents"] id4d["Question Answering & Information Retrieval"] id4e["Code Generation & Debugging"] id4f["Sentiment Analysis"] id5["Applications"] id5a["Chatbots & Virtual Assistants"] id5b["Automated Content Creation"] id5c["Data Analysis & Insights"] id5d["Software Development Tools"] id5e["Educational Tools"] id5f["Scientific Research"] id6["Limitations & Considerations"] id6a["'Hallucinations' (Factual Inaccuracies)"] id6b["Potential for Bias (from training data)"] id6c["Ethical Concerns & Misuse Potential"] id6d["Lack of True Comprehension or Consciousness"] id6e["Computational Cost (Training & Inference)"] id7["Prominent Examples"] id7a["GPT Series (OpenAI)"] id7b["LLaMA & Llama 2 (Meta AI)"] id7c["PaLM & Gemini (Google)"] id7d["Claude (Anthropic)"] id7e["Various Open Source Models"]
This mindmap provides a structured overview, illustrating how different facets of LLMs interrelate to form these powerful language processing tools.
Unveiling the Capabilities of LLMs
The extensive training and sophisticated architecture of LLMs endow them with a versatile range of language-based capabilities. These abilities have opened up new frontiers in how humans interact with computers and how automated systems can handle complex linguistic tasks.
Diverse Linguistic Proficiencies
Text Generation and Content Creation
LLMs excel at generating human-like text in various styles and formats. This includes writing articles, blog posts, marketing copy, poetry, scripts, and even musical compositions in textual form. They can adapt their tone and style based on the input prompt or specific fine-tuning.
Language Translation and Summarization
They can translate text between numerous languages with increasing accuracy and fluency. Furthermore, LLMs are adept at summarizing long documents or articles, extracting key information, and presenting it in a concise format, saving significant time and effort.
Question Answering and Information Retrieval
LLMs can understand questions posed in natural language and provide relevant answers based on the vast knowledge embedded in their training data. They can retrieve specific facts, explain complex concepts, and engage in informative dialogues.
Code Generation and Assistance
Many LLMs are trained on large amounts of source code, enabling them to generate code snippets in various programming languages, explain existing code, help debug programs, and even translate code from one language to another.
Conversational AI: Powering Chatbots and Virtual Assistants
LLMs are the backbone of many modern chatbots and virtual assistants. They enable these systems to engage in more natural, coherent, and context-aware conversations, providing customer support, personal assistance, and interactive experiences.
LLM Proficiency Across Different Tasks: A Comparative View
Large Language Models vary in their strengths and weaknesses depending on their architecture, training data, and specific fine-tuning. The radar chart below offers a conceptual comparison of different classes of LLMs across several key capabilities. The scores are illustrative, representing general tendencies rather than precise measurements, on a scale of 1 (Rudimentary) to 10 (Highly Advanced).
This chart illustrates that while all LLMs share core capabilities, their proficiency levels can differ significantly. Cutting-edge models generally show higher performance across most tasks, while specialized models excel in their niche. Factual reliability remains a challenge that improves with newer generations but requires careful verification.
Real-World Impact: Applications of LLMs
The versatility of Large Language Models has led to their adoption across a multitude of industries, transforming processes and creating new possibilities. Their ability to understand and generate human-like text is being leveraged in innovative ways to enhance efficiency, creativity, and user engagement.
Visual contextualizing Large Language Models within the broader field of Artificial Intelligence, including Machine Learning and Deep Learning.
Below is a table highlighting some common applications of LLMs in various sectors:
| Industry | Application Area | Example Use Case |
|---|---|---|
| Technology & Software | Code Generation & Assistance | Automated code completion, bug detection, natural language to code translation. |
| Customer Service | Intelligent Chatbots & Virtual Assistants | Providing 24/7 customer support, answering FAQs, resolving issues, personal shopping assistants. |
| Marketing & Advertising | Content Creation | Generating ad copy, social media posts, email marketing campaigns, product descriptions. |
| Healthcare | Medical Documentation & Research | Summarizing patient records, assisting in medical report generation, analyzing research papers. |
| Education | Personalized Learning & Tutoring | Creating tailored educational content, interactive tutoring systems, grading assistance. |
| Finance | Fraud Detection & Financial Analysis | Analyzing financial reports for anomalies, generating market summaries, customer sentiment analysis. |
| Media & Entertainment | Script Writing & Content Summarization | Assisting in writing scripts for movies or games, generating plot summaries, creating personalized news feeds. |
| Legal | Document Review & Legal Research | Automating the review of legal documents, assisting in case law research, drafting legal correspondence. |
These examples showcase just a fraction of how LLMs are being integrated into professional and personal spheres, driving innovation and efficiency.
Explore LLMs Further: A Video Explainer
For a comprehensive visual and auditory explanation of Large Language Models, including their history, how they work, the concept of fine-tuning, and the challenges associated with them, the following video provides an excellent overview. It delves into the foundational aspects and practical considerations of LLM technology.
This video, "Large Language Models (LLMs) - Everything You NEED To Know," offers deeper insights into the transformative power of LLMs and their journey from conceptual AI to practical tools shaping various aspects of our digital world.
Navigating the Nuances: Limitations and Considerations
Despite their impressive capabilities, LLMs are not without limitations. Understanding these challenges is crucial for their responsible development and deployment.
Key Challenges and Ethical Points
The "Hallucination" Phenomenon
LLMs can sometimes generate text that is plausible-sounding and grammatically correct but factually inaccurate or nonsensical. This is often referred to as "hallucination." Because they primarily predict likely sequences of words based on patterns rather than accessing a database of verified facts, they can confidently assert incorrect information.
Understanding vs. Mimicry
While LLMs can process and generate language in a way that mimics human understanding, they do not possess true consciousness, sentience, or genuine comprehension in the human sense. Their "understanding" is based on statistical relationships learned from data, not on lived experience or an internal model of the world.
Bias In, Bias Out
LLMs learn from the data they are trained on. If this data contains societal biases (e.g., related to gender, race, or stereotypes), the model can inadvertently learn and perpetuate these biases in its outputs. Addressing and mitigating bias in LLMs is an ongoing area of research and ethical concern.
Ethical Implications and Responsible Use
The power of LLMs also brings ethical considerations, including the potential for misuse (e.g., generating misinformation or "fake news"), job displacement due to automation, and concerns about privacy if trained on sensitive data. Responsible development practices, transparency, and robust ethical guidelines are essential.
Refining Performance: Prompt Engineering and Fine-Tuning
The output of an LLM can be significantly influenced by how it is prompted (the input text given to it). "Prompt engineering" is the art and science of crafting effective prompts to elicit desired responses. Additionally, pre-trained LLMs can be "fine-tuned" on smaller, task-specific datasets to improve their performance on particular applications or to align their behavior with desired norms.
Notable Examples of LLMs
The field of Large Language Models has seen rapid advancements, with several prominent models making headlines and pushing the boundaries of AI capabilities. Some of an LLM's well-known examples include:
- GPT (Generative Pre-trained Transformer) Series by OpenAI: Models like GPT-3, GPT-3.5, and GPT-4 are widely recognized for their strong generative capabilities and performance across a diverse range of NLP tasks.
- LLaMA (Large Language Model Meta AI) and Llama 2 by Meta AI: These models, particularly Llama 2, have gained attention for being available in more open configurations, fostering research and development in the wider community.
- PaLM (Pathways Language Model) and Gemini by Google: Google has developed a suite of powerful LLMs, with PaLM and its successor Gemini showcasing impressive scale and multimodal capabilities.
- Claude by Anthropic: Developed with a focus on AI safety and helpfulness, Claude models are designed to be more aligned with human values and less prone to generating harmful content.
- Open-Source Initiatives: Beyond proprietary models, a vibrant ecosystem of open-source LLMs (e.g., Vicuna, Falcon, Mixtral) is emerging, driven by research institutions and collaborative efforts, promoting accessibility and innovation.
These examples represent just a snapshot of a dynamic and rapidly evolving field, with new models and improvements being announced regularly.
Frequently Asked Questions (FAQs)
Recommended Queries
- How does the Transformer architecture in LLMs actually work?
- What are the most significant ethical challenges in developing and deploying Large Language Models?
- Compare the capabilities and limitations of different leading LLMs like GPT-4, Llama 2, and Gemini.
- What is prompt engineering and how can it be used to get better results from LLMs?
References

Last updated May 11, 2025