
ไขปริศนา R-squared (R²): ตัวชี้วัดสำคัญที่นักวิเคราะห์ข้อมูลต้องรู้!
R² คืออะไร? ใช้วัดอะไรได้บ้าง? และเราจะค้นหาค่านี้ได้อย่างไร? มาหาคำตอบกัน
ไฮไลท์สำคัญเกี่ยวกับ R-squared (R²)
- ความหมายของ R²: R-squared หรือ สัมประสิทธิ์การตัดสินใจ คือค่าสถิติที่บ่งบอกสัดส่วนความแปรปรวนของตัวแปรตาม (Dependent Variable) ที่สามารถอธิบายได้ด้วยตัวแปรอิสระ (Independent Variable) ในแบบจำลองการถดถอยเชิงเส้น
- วัตถุประสงค์หลัก: ใช้เพื่อประเมินว่าแบบจำลองการถดถอย (Regression Model) ที่สร้างขึ้นนั้นมีความเหมาะสมและสามารถอธิบายข้อมูลได้ดีเพียงใด (Goodness-of-fit) ยิ่งค่า R² สูง (เข้าใกล้ 1) หมายความว่าแบบจำลองอธิบายข้อมูลได้ดี
- วิธีการหาค่า: สามารถคำนวณได้จากสูตรทางสถิติ หรือใช้เครื่องมือซอฟต์แวร์ยอดนิยมอย่าง Microsoft Excel และโปรแกรมทางสถิติอื่น ๆ ซึ่งช่วยให้การหาค่า R² เป็นเรื่องง่ายและรวดเร็ว
R² คืออะไร? (What is R²?)
R-squared (ออกเสียงว่า อาร์-สแควร์) หรือที่รู้จักกันในชื่อ "สัมประสิทธิ์การตัดสินใจ" (Coefficient of Determination) เป็นหนึ่งในตัวชี้วัดทางสถิติที่สำคัญอย่างยิ่งในโลกของการวิเคราะห์ข้อมูลและการสร้างแบบจำลอง โดยเฉพาะอย่างยิ่งในการวิเคราะห์การถดถอย (Regression Analysis)
ความหมายและขอบเขตของ R²
R² คือค่าที่แสดงถึงสัดส่วนของความแปรปรวนทั้งหมดในตัวแปรตาม (Dependent Variable) ที่สามารถอธิบายได้ด้วยตัวแปรอิสระ (Independent Variable หรือ Predictor Variables) ที่อยู่ในแบบจำลองการถดถอยที่เราสร้างขึ้น พูดง่ายๆ คือ R² บอกเราว่าแบบจำลองของเรานั้น "ดีแค่ไหน" ในการอธิบายความสัมพันธ์ของข้อมูล
ค่า R² จะมีค่าอยู่ระหว่าง 0 ถึง 1 (หรือ 0% ถึง 100% เมื่อแสดงในรูปเปอร์เซ็นต์):
- R² = 0: หมายความว่าแบบจำลองไม่สามารถอธิบายความแปรปรวนใดๆ ของตัวแปรตามได้เลย ตัวแปรอิสระที่ใช้ไม่มีความสัมพันธ์เชิงเส้นกับตัวแปรตาม
- R² = 1: หมายความว่าแบบจำลองสามารถอธิบายความแปรปรวนทั้งหมดของตัวแปรตามได้อย่างสมบูรณ์แบบ ทุกจุดข้อมูลจริงตกอยู่บนเส้นถดถอยพอดี (ซึ่งในความเป็นจริงเกิดขึ้นได้ยากมาก)
ตัวอย่างเช่น ถ้าค่า R² ของแบบจำลองการทำนายยอดขายเท่ากับ 0.75 นั่นหมายความว่า 75% ของความผันแปรในยอดขายสามารถอธิบายได้ด้วยตัวแปรอิสระที่ใช้ในแบบจำลอง (เช่น งบโฆษณา, จำนวนสาขา) ส่วนอีก 25% ที่เหลืออาจเกิดจากปัจจัยอื่นๆ ที่ไม่ได้รวมอยู่ในแบบจำลอง หรือเป็นความคลาดเคลื่อนโดยธรรมชาติ
การตีความค่า R²
การตีความค่า R² ควรทำด้วยความระมัดระวัง:
- ค่า R² สูง: โดยทั่วไปแล้ว ค่า R² ที่สูง (เช่น มากกว่า 0.7 หรือ 0.8) บ่งชี้ว่าแบบจำลองมีความเหมาะสมกับข้อมูลได้ดี อย่างไรก็ตาม ค่า R² ที่สูงมาก ๆ ไม่ได้การันตีเสมอไปว่าแบบจำลองนั้นดีที่สุดหรือถูกต้องเสมอไป บางครั้งอาจเกิดจาก "การฟิตเกินไป" (Overfitting) โดยเฉพาะเมื่อมีตัวแปรอิสระจำนวนมาก
- ค่า R² ต่ำ: ค่า R² ที่ต่ำ (เช่น น้อยกว่า 0.3) บ่งชี้ว่าแบบจำลองอธิบายความแปรปรวนของตัวแปรตามได้น้อย แต่อาจไม่ได้หมายความว่าแบบจำลองนั้นไร้ประโยชน์เสมอไป ในบางสาขาวิชา เช่น สังคมศาสตร์ ที่มีความซับซ้อนสูง การได้ค่า R² ปานกลางก็อาจถือว่ามีความสำคัญทางสถิติแล้ว หากตัวแปรอิสระนั้นมีความสำคัญทางทฤษฎี
สิ่งสำคัญคือต้องพิจารณา R² ร่วมกับบริบทของปัญหา สถิติอื่นๆ เช่น ค่า p-value ของสัมประสิทธิ์, การวิเคราะห์ส่วนที่เหลือ (Residual Analysis) และความรู้ความเข้าใจในโดเมนนั้นๆ
R² มีไว้ทำอะไร? (What is R² used for?)
ค่า R² เป็นเครื่องมือที่มีประโยชน์หลายประการในการวิเคราะห์ข้อมูลและสร้างแบบจำลองทางสถิติ โดยมีวัตถุประสงค์หลักดังนี้:
การประเมินความเหมาะสมของแบบจำลอง (Assessing Model Goodness-of-Fit)
วัตถุประสงค์หลักของ R² คือการวัดว่าแบบจำลองการถดถอยที่เราสร้างขึ้นนั้น "ฟิต" หรือเหมาะสมกับชุดข้อมูลที่สังเกตได้ดีเพียงใด ยิ่งค่า R² สูง แสดงว่าจุดข้อมูลจริงส่วนใหญ่อยู่ใกล้เคียงกับค่าที่ทำนายโดยแบบจำลอง ซึ่งหมายความว่าแบบจำลองสามารถจับรูปแบบหรือแนวโน้มในข้อมูลได้ดี
ตัวอย่างเช่น ในการวิเคราะห์แนวโน้มยอดขายสินค้าโดยใช้ปัจจัยด้านราคาและโปรโมชั่นเป็นตัวแปรอิสระ ค่า R² จะช่วยบอกว่าปัจจัยเหล่านี้สามารถอธิบายความผันผวนของยอดขายได้มากน้อยเพียงใด
การเปรียบเทียบแบบจำลอง (Comparing Models)
เมื่อเรามีแบบจำลองหลายแบบที่พยายามอธิบายปรากฏการณ์เดียวกัน R² สามารถใช้เป็นเกณฑ์หนึ่งในการเปรียบเทียบว่าแบบจำลองใดอธิบายข้อมูลได้ดีกว่า โดยทั่วไป แบบจำลองที่มีค่า R² สูงกว่าจะถือว่ามีความสามารถในการอธิบายที่ดีกว่า
อย่างไรก็ตาม เมื่อเปรียบเทียบแบบจำลองที่มีจำนวนตัวแปรอิสระแตกต่างกัน ควรพิจารณาใช้ Adjusted R² (R² ปรับปรุง) แทน R² แบบปกติ เนื่องจาก Adjusted R² จะทำการปรับค่า R² ให้ลดลงเมื่อมีการเพิ่มตัวแปรอิสระที่ไม่ช่วยปรับปรุงความสามารถในการอธิบายของแบบจำลองได้อย่างมีนัยสำคัญ ซึ่งช่วยป้องกันปัญหาการเลือกแบบจำลองที่ซับซ้อนเกินความจำเป็น (Overfitting)
ข้อควรระวังในการใช้ R²
แม้ว่า R² จะเป็นตัวชี้วัดที่มีประโยชน์ แต่ก็มีข้อจำกัดและข้อควรระวังในการใช้งาน:
- R² ไม่ได้บอกถึงความสัมพันธ์เชิงสาเหตุ: ค่า R² สูงไม่ได้หมายความว่าตัวแปรอิสระเป็น "สาเหตุ" ของการเปลี่ยนแปลงในตัวแปรตาม มันเพียงแค่บ่งบอกถึงความสัมพันธ์ทางสถิติเท่านั้น
- ความเอนเอียง (Bias): R² ไม่สามารถตรวจจับความเอนเอียงในแบบจำลองได้ แบบจำลองที่มี R² สูงก็ยังอาจให้ค่าพยากรณ์ที่เอนเอียงได้
- การเพิ่มตัวแปรอิสระ: การเพิ่มตัวแปรอิสระเข้าไปในแบบจำลอง (แม้ว่าตัวแปรนั้นจะไม่เกี่ยวข้องเลยก็ตาม) จะทำให้ค่า R² เพิ่มขึ้นหรืออย่างน้อยก็ไม่ลดลง นี่คือเหตุผลที่ควรพิจารณา Adjusted R² สำหรับแบบจำลองที่มีตัวแปรอิสระหลายตัว
- ความสำคัญทางปฏิบัติ vs. ความสำคัญทางสถิติ: ค่า R² สูงอาจมีความสำคัญทางสถิติ แต่ในทางปฏิบัติอาจจะไม่มีนัยสำคัญก็ได้ หรือในทางกลับกัน ค่า R² ต่ำก็อาจยังคงมีประโยชน์หากแบบจำลองให้ข้อมูลเชิงลึกที่สำคัญ
- ประเภทของข้อมูล: ความคาดหวังสำหรับค่า R² ที่ "ดี" อาจแตกต่างกันไปตามสาขาวิชาและประเภทของข้อมูลที่กำลังวิเคราะห์
ดังนั้น การประเมินแบบจำลองไม่ควรพึ่งพาค่า R² เพียงอย่างเดียว แต่ควรพิจารณาร่วมกับเครื่องมือและเทคนิคอื่นๆ เช่น การตรวจสอบกราฟส่วนที่เหลือ (Residual Plots), ค่า p-values ของตัวแปร, และการตรวจสอบความสมเหตุสมผลของแบบจำลองตามหลักทฤษฎี
วิธีการหาค่า R² (How to find R²?)
การหาค่า R² สามารถทำได้หลายวิธี ตั้งแต่การคำนวณด้วยสูตรทางสถิติไปจนถึงการใช้เครื่องมือซอฟต์แวร์ที่ช่วยอำนวยความสะดวก
สูตรการคำนวณ R² (R² Calculation Formulas)
ในทางคณิตศาสตร์ R² ถูกกำหนดโดยสัดส่วนของผลรวมกำลังสอง (Sum of Squares)
สูตรหลัก (Main Formula)
สูตรที่ใช้กันโดยทั่วไปในการคำนวณ R² คือ:
\[ R^2 = 1 - \frac{SS_{\text{res}}}{SS_{\text{tot}}} \]โดยที่:
- \( SS_{\text{res}} \) (Sum of Squares of Residuals) หรือบางครั้งเรียกว่า \( SSE \) (Sum of Squared Errors): คือผลรวมของกำลังสองของผลต่างระหว่างค่าที่สังเกตได้จริง (Actual Values) กับค่าที่ทำนายได้จากแบบจำลอง (Predicted Values) มันแสดงถึงความแปรปรวนที่แบบจำลอง "ไม่สามารถ" อธิบายได้ \[ SS_{\text{res}} = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \] เมื่อ \(y_i\) คือค่าจริง และ \(\hat{y}_i\) คือค่าที่ทำนายได้
- \( SS_{\text{tot}} \) (Total Sum of Squares): คือผลรวมของกำลังสองของผลต่างระหว่างค่าที่สังเกตได้จริงกับค่าเฉลี่ยของตัวแปรตามทั้งหมด มันแสดงถึงความแปรปรวนทั้งหมดในตัวแปรตาม \[ SS_{\text{tot}} = \sum_{i=1}^{n} (y_i - \bar{y})^2 \] เมื่อ \(\bar{y}\) คือค่าเฉลี่ยของตัวแปรตาม
อีกสูตรหนึ่งที่ให้ผลลัพธ์เหมือนกันคือ:
\[ R^2 = \frac{SS_{\text{reg}}}{SS_{\text{tot}}} \]โดยที่ \( SS_{\text{reg}} \) (Sum of Squares due to Regression) หรือบางครั้งเรียกว่า \( SSR \) (Sum of Squares Regression) คือผลรวมของกำลังสองของผลต่างระหว่างค่าที่ทำนายได้จากแบบจำลองกับค่าเฉลี่ยของตัวแปรตาม มันแสดงถึงความแปรปรวนที่แบบจำลอง "สามารถ" อธิบายได้ \[ SS_{\text{reg}} = \sum_{i=1}^{n} (\hat{y}_i - \bar{y})^2 \] และมีความสัมพันธ์คือ \( SS_{\text{tot}} = SS_{\text{reg}} + SS_{\text{res}} \)
ความสัมพันธ์กับค่าสหสัมพันธ์ (r) (Relationship with Correlation Coefficient (r))
ในกรณีของการวิเคราะห์การถดถอยเชิงเส้นอย่างง่าย (Simple Linear Regression) ซึ่งมีตัวแปรอิสระเพียงตัวเดียว ค่า R² จะเท่ากับกำลังสองของค่าสัมประสิทธิ์สหสัมพันธ์แบบเพียร์สัน (Pearson Correlation Coefficient, r) ระหว่างตัวแปรอิสระและตัวแปรตาม:
\[ R^2 = r^2 \]ค่า r บ่งบอกถึงทิศทางและความแข็งแรงของความสัมพันธ์เชิงเส้นระหว่างตัวแปรสองตัว ในขณะที่ R² บ่งบอกถึงสัดส่วนของความแปรปรวนที่ถูกอธิบาย
การหาค่า R² ด้วยเครื่องมือ (Finding R² with Tools)
ในทางปฏิบัติ การคำนวณ R² ด้วยมืออาจมีความซับซ้อนและเสียเวลา โดยเฉพาะกับชุดข้อมูลขนาดใหญ่ ดังนั้นจึงนิยมใช้โปรแกรมคอมพิวเตอร์ช่วย
การใช้โปรแกรม Microsoft Excel
Microsoft Excel เป็นเครื่องมือที่เข้าถึงง่ายและมีฟังก์ชันสำหรับการคำนวณ R² ได้หลายวิธี:
- การสร้างกราฟกระจาย (Scatter Plot) และเพิ่มเส้นแนวโน้ม (Trendline):
- นำเข้าข้อมูลตัวแปรอิสระ (X) และตัวแปรตาม (Y) ของคุณลงในคอลัมน์ของ Excel
- เลือกข้อมูลทั้งสองคอลัมน์
- ไปที่แท็บ "Insert" (แทรก) และเลือก "Scatter" (แผนภูมิกระจาย) เพื่อสร้างกราฟ
- คลิกขวาที่จุดข้อมูลใดๆ บนกราฟ แล้วเลือก "Add Trendline..." (เพิ่มเส้นแนวโน้ม...)
- ในหน้าต่าง "Format Trendline" (จัดรูปแบบเส้นแนวโน้ม) ที่ปรากฏขึ้น ให้เลือกประเภทของเส้นแนวโน้ม (โดยทั่วไปคือ "Linear" สำหรับการถดถอยเชิงเส้น)
- เลื่อนลงมาและติ๊กถูกที่ช่อง "Display Equation on chart" (แสดงสมการในแผนภูมิ) และ "Display R-squared value on chart" (แสดงค่า R-squared ในแผนภูมิ)
- Excel จะแสดงสมการเส้นตรงและค่า R² บนกราฟของคุณโดยอัตโนมัติ
- การใช้ฟังก์ชัน Data Analysis ToolPak:
- หากยังไม่ได้เปิดใช้งาน ให้ไปที่ File > Options > Add-ins > Manage: Excel Add-ins > Go... แล้วติ๊กเลือก "Analysis ToolPak"
- ไปที่แท็บ "Data" (ข้อมูล) และคลิก "Data Analysis" (การวิเคราะห์ข้อมูล)
- ในหน้าต่าง Data Analysis เลือก "Regression" (การถดถอย) และคลิก OK
- ป้อนช่วงข้อมูลสำหรับ "Input Y Range" (ตัวแปรตาม) และ "Input X Range" (ตัวแปรอิสระ)
- เลือกตัวเลือกผลลัพธ์ (Output options) และคลิก OK
- Excel จะสร้างรายงานสรุปผลการวิเคราะห์การถดถอย ซึ่งรวมถึงค่า R Square (R²), Adjusted R Square, และสถิติอื่นๆ ที่เกี่ยวข้อง
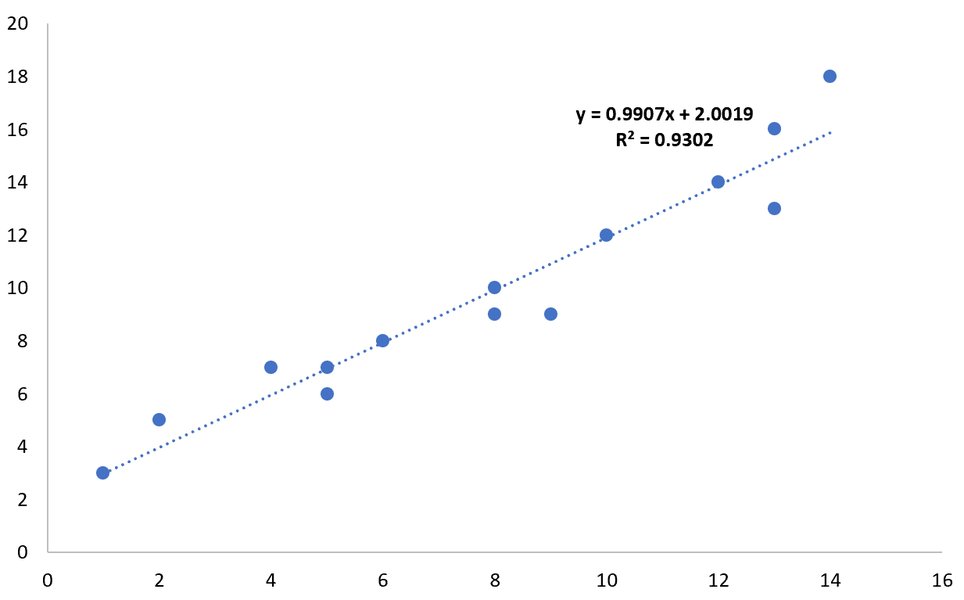
ภาพตัวอย่างแสดงการเพิ่มเส้นแนวโน้มและค่า R-squared บนแผนภูมิกระจายใน Excel
การใช้ซอฟต์แวร์ทางสถิติ (Using Statistical Software)
โปรแกรมทางสถิติเฉพาะทาง เช่น SPSS, Minitab, R, Python (ด้วยไลบรารีเช่น Scikit-learn, Statsmodels) จะคำนวณค่า R² และสถิติอื่นๆ ที่เกี่ยวข้องกับการวิเคราะห์การถดถอยให้โดยอัตโนมัติเมื่อคุณสั่งให้โปรแกรมทำการวิเคราะห์ ซึ่งมักจะให้ผลลัพธ์ที่ละเอียดและครอบคลุมมากกว่า
R² ในมุมมองเปรียบเทียบ: ปัจจัยในการประเมินแบบจำลอง
ค่า R² เป็นเพียงหนึ่งในหลายปัจจัยที่ใช้ในการประเมินความเหมาะสมและประสิทธิภาพของแบบจำลองการถดถอย การพิจารณาแบบจำลองที่ดีที่สุดมักเกี่ยวข้องกับการสร้างสมดุลระหว่างปัจจัยต่างๆ แผนภูมิเรดาร์ด้านล่างแสดงการเปรียบเทียบสมมติของแบบจำลองสามแบบ (แบบจำลอง A, แบบจำลอง B, และแบบจำลองอุดมคติ) โดยพิจารณาจากเกณฑ์ต่างๆ ซึ่งรวมถึง R²
แผนภูมิเรดาร์เปรียบเทียบคุณลักษณะของแบบจำลองทางสถิติสมมติต่างๆ
จากแผนภูมิ:
- พลังในการอธิบาย (R²): แสดงสัดส่วนความแปรปรวนที่แบบจำลองอธิบายได้
- ความแม่นยำในการทำนาย: ความสามารถของแบบจำลองในการทำนายค่าใหม่ได้อย่างถูกต้อง
- ความเรียบง่าย: ความซับซ้อนของแบบจำลอง; แบบจำลองที่เรียบง่ายกว่ามักเป็นที่ต้องการหากอธิบายได้ดีพอ
- ความทนทานต่อค่าผิดปกติ: ความสามารถของแบบจำลองในการรักษาประสิทธิภาพแม้มีข้อมูลที่ผิดปกติ
- ความง่ายในการตีความ: ความชัดเจนในการทำความเข้าใจว่าแบบจำลองทำงานอย่างไรและความหมายของปัจจัยต่างๆ
สรุปแนวคิดหลักของ R² (Summary of Key Concepts of R²)
เพื่อให้เข้าใจภาพรวมของ R-squared ได้ง่ายขึ้น แผนผังความคิด (Mindmap) ด้านล่างนี้สรุปประเด็นสำคัญต่างๆ ที่เกี่ยวข้องกับ R² ตั้งแต่ความหมายพื้นฐาน วัตถุประสงค์ในการใช้งาน วิธีการคำนวณ การตีความหมาย และข้อจำกัดที่ควรทราบ
สัดส่วนความแปรปรวนของตัวแปรตาม
ที่อธิบายได้ด้วยตัวแปรอิสระในแบบจำลอง"] id1_1["ค่าอยู่ระหว่าง 0 ถึง 1 (0% - 100%)"] id1_2["0 = แบบจำลองไม่อธิบายความแปรปรวนเลย"] id1_3["1 = แบบจำลองอธิบายความแปรปรวนได้ทั้งหมด"] id2["วัตถุประสงค์ (Purpose)"] id2_1["วัดความเหมาะสมของแบบจำลอง (Goodness-of-fit)"] id2_2["ประเมินความสามารถในการอธิบายข้อมูลของแบบจำลอง"] id2_3["เปรียบเทียบประสิทธิภาพระหว่างแบบจำลองต่างๆ"] id2_4["สนับสนุนการตัดสินใจในการวิเคราะห์ข้อมูล"] id3["การคำนวณ (Calculation)"] id3_1["สูตรหลัก: \( R^2 = 1 - \frac{SS_{res}}{SS_{tot}} \)"] id3_1_1["\(SS_{res}\): Sum of Squares of Residuals (ความคลาดเคลื่อน)"] id3_1_2["\(SS_{tot}\): Total Sum of Squares (ความแปรปรวนทั้งหมด)"] id3_2["อีกสูตร: \( R^2 = \frac{SS_{reg}}{SS_{tot}} \)"] id3_2_1["\(SS_{reg}\): Sum of Squares due to Regression (ความแปรปรวนที่อธิบายได้)"] id3_3["กรณีถดถอยเชิงเส้นอย่างง่าย: \(R^2 = r^2\) (r คือ สัมประสิทธิ์สหสัมพันธ์)"] id3_4["เครื่องมือ: Excel, SPSS, R, Python"] id4["การตีความ (Interpretation)"] id4_1["ค่าสูง (ใกล้ 1) = แบบจำลองอธิบายข้อมูลได้ดี"] id4_2["ค่าต่ำ (ใกล้ 0) = แบบจำลองอธิบายข้อมูลได้ไม่ดี"] id4_3["ต้องพิจารณาร่วมกับบริบทและสถิติอื่น"] id5["ข้อจำกัดและข้อควรระวัง (Limitations & Caveats)"] id5_1["ค่าสูง ไม่ได้หมายความว่าแบบจำลอง 'ดี' เสมอไป (อาจเกิด Overfitting)"] id5_2["ไม่ได้บ่งบอกความสัมพันธ์เชิงสาเหตุ"] id5_3["ค่า R² เพิ่มขึ้นเมื่อเพิ่มตัวแปร (พิจารณา Adjusted R²)"] id5_4["ไม่ควรใช้ R² เพียงตัวเดียวในการประเมินแบบจำลอง"]
แผนผังนี้ช่วยให้เห็นภาพรวมและความเชื่อมโยงของแนวคิดต่างๆ เกี่ยวกับ R² ทำให้สามารถนำไปประยุกต์ใช้ได้อย่างถูกต้องและมีประสิทธิภาพมากยิ่งขึ้น
เรียนรู้เพิ่มเติมเกี่ยวกับการคำนวณ R² (Learn More About R² Calculation)
วิดีโอนี้จะอธิบายวิธีการคำนวณค่า R-Squared สำหรับแบบจำลองการถดถอยเชิงเส้น (Linear Regression) ด้วยภาพและการอธิบายที่เข้าใจง่าย ซึ่งจะช่วยให้คุณเห็นภาพและเข้าใจแนวคิดเบื้องหลังสูตรการคำนวณได้ชัดเจนยิ่งขึ้น รวมถึงความหมายของแต่ละองค์ประกอบในสูตร เช่น SSm (Sum of Squares Model), SSt (Sum of Squares Total), และ SSr (Sum of Squares Residual หรือ Error) วิดีโอนี้เหมาะสำหรับผู้ที่ต้องการทำความเข้าใจหลักการคำนวณ R² อย่างลึกซึ้ง
วิดีโออธิบายวิธีการคำนวณค่า R-Squared ของ Linear Regression
การทำความเข้าใจวิธีการคำนวณ R² ไม่เพียงแต่ช่วยให้คุณใช้ค่านี้ได้อย่างถูกต้อง แต่ยังช่วยให้คุณตระหนักถึงข้อจำกัดและสามารถตีความผลลัพธ์ได้อย่างมีวิจารณญาณมากขึ้นในการวิเคราะห์ข้อมูล
ตารางสรุป R² (R² Summary Table)
เพื่อให้ง่ายต่อการจดจำและทบทวนข้อมูลสำคัญเกี่ยวกับ R-squared (R²) ตารางด้านล่างนี้ได้สรุปประเด็นหลักๆ ไว้ดังนี้:
| หัวข้อ | คำอธิบาย |
|---|---|
| ชื่อเต็ม | สัมประสิทธิ์การตัดสินใจ (Coefficient of Determination) |
| สัญลักษณ์ | R² หรือ R-squared |
| ความหมายหลัก | สัดส่วนของความแปรปรวนในตัวแปรตามที่สามารถอธิบายได้ด้วยตัวแปรอิสระในแบบจำลอง |
| ช่วงของค่า | 0 ถึง 1 (หรือ 0% ถึง 100%) |
| การตีความค่า | ค่าใกล้ 1: แบบจำลองอธิบายข้อมูลได้ดีมาก ค่าใกล้ 0: แบบจำลองอธิบายข้อมูลได้น้อยหรือไม่ดี |
| วัตถุประสงค์หลัก | วัดความเหมาะสมของแบบจำลองการถดถอย (Goodness-of-fit), เปรียบเทียบแบบจำลอง |
| สูตรคำนวณหลัก | \(R^2 = 1 - \frac{SS_{\text{res}}}{SS_{\text{tot}}}\) หรือ \(R^2 = \frac{SS_{\text{reg}}}{SS_{\text{tot}}}\) |
| สำหรับ Simple Linear Regression | \(R^2 = r^2\) (เมื่อ r คือ สัมประสิทธิ์สหสัมพันธ์ของเพียร์สัน) |
| เครื่องมือที่ใช้หาค่า | Microsoft Excel, SPSS, R, Python, Minitab และโปรแกรมทางสถิติอื่นๆ |
| ข้อควรพิจารณาเพิ่มเติม | Adjusted R² สำหรับแบบจำลองที่มีตัวแปรอิสระหลายตัว, พิจารณาร่วมกับสถิติอื่นๆ และบริบทของปัญหา |
ตารางนี้เป็นเพียงภาพรวมเบื้องต้น การทำความเข้าใจ R² อย่างถ่องแท้จำเป็นต้องศึกษาและนำไปประยุกต์ใช้กับโจทย์ปัญหาจริง เพื่อให้เกิดความชำนาญในการตีความและใช้งานอย่างเหมาะสม
คำถามที่พบบ่อย (FAQ)
แนะนำหัวข้อที่เกี่ยวข้อง (Recommended Topics)
- Adjusted R-squared คืออะไร และแตกต่างจาก R-squared อย่างไร?
- วิธีการตีความผลลัพธ์การวิเคราะห์การถดถอยเชิงเส้นแบบละเอียดควรทำอย่างไร?
- การตรวจสอบข้อสมมติฐานของแบบจำลองการถดถอย (Regression Assumptions) มีความสำคัญอย่างไร?
- มีเทคนิคใดบ้างในการเลือกตัวแปรอิสระที่ดีที่สุดสำหรับแบบจำลองการถดถอย?
แหล่งอ้างอิง (References)
Last updated May 12, 2025