
YOLO Model: Revolutionizing Real-Time Object Detection
A Comprehensive Overview of the YOLO Object Detection Framework
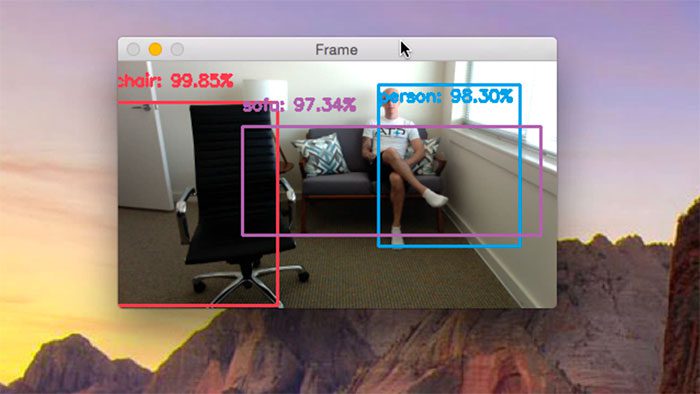
Key Takeaways
- Real-Time Object Detection: YOLO's high-speed processing enables instantaneous detection suitable for dynamic environments.
- Single Neural Network Approach: By utilizing a unified network for both localization and classification, YOLO achieves efficiency and simplicity.
- Wide Range of Applications: From autonomous vehicles to medical imaging, YOLO's versatility makes it applicable across various industries.
Introduction to YOLO
The YOLO (You Only Look Once) model is a state-of-the-art real-time object detection system introduced in 2015 by Joseph Redmon and Ali Farhadi. It stands out among object detection algorithms due to its unprecedented speed and accuracy, which are crucial for applications requiring immediate response, such as autonomous driving, robotics, and live surveillance.
Traditional object detection methods often utilize a two-stage process: first, generating region proposals, and then classifying each region independently. This multi-stage approach, while effective, is computationally intensive and unsuitable for real-time applications. YOLO revolutionizes this process by treating object detection as a single regression problem, streamlining both object localization and classification within a single neural network pass.
Architecture and Workflow
Core Architecture
YOLO's architecture is based on a convolutional neural network (CNN) that predicts bounding boxes and class probabilities directly from full images in one evaluation. The key components of YOLO's architecture include:
-
Backbone Network: A pre-trained CNN that extracts essential features from the input image. Earlier versions like YOLOv1 used simpler networks, while later versions employ more sophisticated architectures, such as Darknet-53 in YOLOv3, which enhances feature extraction capabilities.
-
Grid System: YOLO divides the input image into an S×S grid. Each grid cell is responsible for detecting objects whose centers fall within it. This grid-based approach ensures that the model can localize multiple objects within a single image effectively.
-
Bounding Box Prediction: Each grid cell predicts a fixed number of bounding boxes, typically denoted by B. For each bounding box, the cell predicts coordinates (x, y, width, height), a confidence score indicating the likelihood that the box contains an object, and the class probabilities for the detected object.
-
Classification Head: A part of the network dedicated to classifying the detected objects into predefined categories based on the extracted features and bounding box predictions.
Workflow
The YOLO object detection process can be summarized in the following steps:
- Input Image Processing: The input image is resized to a fixed dimension (e.g., 416x416 pixels) to standardize processing and fed into the network.
- Feature Extraction: The backbone CNN processes the image to extract high-level features that are indicative of object presence and characteristics.
- Grid Division: The image is divided into an S×S grid. Each grid cell is tasked with predicting bounding boxes and class probabilities for objects whose centers lie within that cell.
- Bounding Box Prediction: For each grid cell, the model predicts B bounding boxes, each with coordinates, confidence scores, and class probabilities.
- Non-Maximum Suppression: To eliminate duplicate detections, YOLO applies non-maximum suppression, filtering out overlapping boxes and retaining only the most confident predictions.
- Final Output: The model outputs the detected objects with their corresponding bounding boxes and class labels.
Evolution of YOLO Versions
Since its inception, YOLO has undergone significant evolution, marked by various versions that have introduced enhancements in speed, accuracy, and functionality. Each new version builds upon the strengths of its predecessors while addressing their limitations.
YOLOv1
The original YOLO model introduced the concept of a single-stage object detector, demonstrating impressive speed by processing images at 45 frames per second (fps). However, YOLOv1 faced challenges in accurately detecting small objects and suffered from localization errors, particularly when objects were closely packed.
YOLOv2 (YOLO9000)
YOLOv2 improved upon YOLOv1 by introducing anchor boxes, enabling the model to better predict bounding box shapes and sizes. It also incorporated batch normalization, multi-scale training, and fine-grained features, resulting in enhanced detection accuracy and the ability to detect over 9000 object categories when jointly trained on multiple datasets.
YOLOv3
YOLOv3 introduced a deeper backbone network named Darknet-53, which improved feature extraction through residual connections and more convolutional layers. Additionally, YOLOv3 employed multi-scale predictions, allowing it to detect objects at various sizes more effectively. These enhancements led to notable improvements in both speed and accuracy.
YOLOv4 and Beyond
Subsequent versions, including YOLOv4, YOLOv5, and up to YOLOv11, have integrated advanced architectural optimizations and training techniques such as Neural Architecture Search (NAS) and structural re-parameterization. YOLOv8, for example, incorporates deeper and more efficient neural architectures, while YOLOv10 and YOLOv11 continue to push the boundaries of performance and resource efficiency, enabling the model to achieve higher mean Average Precision (mAP) scores and operate effectively on limited computational resources.
Key Features and Innovations
Single Neural Network Efficiency
One of YOLO's most significant innovations is its single neural network approach, which unifies object detection into a single regression task rather than a two-stage pipeline. This design allows YOLO to process images swiftly, making it exceptionally well-suited for real-time applications where speed is paramount.
Grid-Based Detection
YOLO's grid-based system divides the input image into a grid, with each cell responsible for predicting a fixed number of bounding boxes and class probabilities. This spatial partitioning ensures that multiple objects can be detected simultaneously within different regions of the image, enhancing detection accuracy and efficiency.
Anchor Boxes
Introduced in YOLOv2, anchor boxes allow the model to predict bounding boxes of varying aspect ratios and sizes more effectively. By using predefined shapes, the model can better capture the variability in object dimensions, leading to improved localization and classification performance.
Advanced Backbone Networks
The evolution of YOLO has seen the integration of more sophisticated backbone networks, such as Darknet-53 in YOLOv3 and EfficientNet in YOLOv5. These backbones enhance feature extraction capabilities, allowing the model to better recognize and differentiate objects within complex scenes.
Multi-Scale Predictions
YOLOv3 introduced multi-scale predictions, enabling the model to detect objects at different sizes more effectively. By making predictions at multiple scales, YOLO can identify small, medium, and large objects within the same image, addressing one of the limitations of earlier versions.
Optimized Training Strategies
Later versions of YOLO have incorporated optimized training strategies such as data augmentation, batch normalization, and advanced loss functions. These improvements contribute to better generalization across diverse datasets and enhanced model robustness.
Advantages of YOLO
Speed and Real-Time Performance
YOLO's architectural design prioritizes speed, enabling it to process images at high frame rates. For instance, YOLOv3 can achieve up to 155 fps on a high-end GPU, making it suitable for applications where real-time detection is critical, such as autonomous driving, live video streaming, and interactive robotics.
Unified Detection Framework
By encapsulating both object localization and classification within a single neural network, YOLO simplifies the detection pipeline. This unified approach reduces computational overhead, facilitates end-to-end training, and enhances overall efficiency compared to multi-stage detectors like Faster R-CNN.
High Accuracy
Continuous advancements across YOLO versions have significantly improved detection accuracy. With each iteration, the model has achieved higher mean Average Precision (mAP) scores, enhancing its ability to correctly identify and classify objects across various domains and environments.
Versatility and Scalability
YOLO's ability to scale across different computational resources and adapt to various application requirements adds to its versatility. Whether deployed on powerful servers for high-accuracy tasks or on edge devices with limited processing power, YOLO maintains robust performance, making it suitable for a wide range of use cases.
Ease of Use and Integration
YOLO models, especially newer versions like YOLOv8, come with user-friendly implementations and comprehensive documentation, simplifying integration into existing systems. The availability of pre-trained models and compatibility with deep learning frameworks like TensorFlow and PyTorch further enhance its accessibility for developers and researchers.
Limitations
Difficulty with Small Objects
Despite its strengths, YOLO can struggle with detecting small objects within highly cluttered scenes. The grid-based approach may not allocate sufficient granularity for tiny objects, leading to missed detections or reduced localization accuracy.
Handling Overlapping Objects
In scenarios with overlapping or densely packed objects, YOLO's performance may degrade. The model relies on non-maximum suppression to filter overlapping bounding boxes, which might result in incorrect or incomplete detections when objects are too close to each other.
Complex Scene Interpretation
While YOLO performs well in many contexts, interpreting highly complex scenes with intricate object relationships can present challenges. The model's performance depends heavily on the quality and diversity of the training data, and it may require additional fine-tuning to handle specialized environments effectively.
Resource Intensive for High Accuracy
Achieving the highest levels of accuracy with YOLO may necessitate substantial computational resources, especially with deeper versions like YOLOv8. Deploying such models on devices with limited hardware capabilities can be challenging, potentially requiring optimizations or compromises in model complexity.
Applications Across Industries
Autonomous Vehicles
YOLO plays a pivotal role in the development of self-driving cars by enabling real-time detection of pedestrians, vehicles, traffic signs, and other critical objects. Its high-speed processing ensures timely responses to dynamic driving environments, contributing to safety and navigation efficiency.
Surveillance and Security
In security systems, YOLO facilitates real-time monitoring by detecting and recognizing unauthorized intrusions, suspicious activities, or the presence of prohibited items. Its ability to process live video streams with minimal latency makes it ideal for enhancing security measures in public and private spaces.
Healthcare and Medical Imaging
YOLO is utilized in medical imaging for tasks like anomaly detection in X-rays, MRIs, and CT scans. By accurately identifying abnormalities such as tumors or fractures, YOLO aids medical professionals in diagnosis and treatment planning, improving patient outcomes and operational efficiency.
Retail and Inventory Management
In the retail sector, YOLO assists in inventory tracking, shelf monitoring, and cashier-less checkout systems. Its ability to detect and classify products in real-time streamlines operations, reduces human error, and enhances the overall shopping experience.
Sports Analytics
Sports and media industries leverage YOLO for tracking players, balls, and other fast-moving objects. Real-time analysis of game footage provides valuable statistics, supports broadcast technologies, and enriches viewer engagement through dynamic replays and insights.
Industrial Inspection and Quality Control
In manufacturing and industrial settings, YOLO is employed for quality control by detecting defects, monitoring assembly lines, and ensuring product standards. Automated inspection processes powered by YOLO enhance production accuracy, reduce waste, and maintain consistent quality standards.
Performance Comparison Across YOLO Versions
| Version | Release Year | Key Features | Frame Rate (fps) | mAP Score |
|---|---|---|---|---|
| YOLOv1 | 2015 | Single neural network, real-time detection | 45 | 63.4% |
| YOLOv2 | 2017 | Anchor boxes, batch normalization, YOLO9000 | 40 | 76.8% |
| YOLOv3 | 2018 | Darknet-53, multi-scale predictions | 155 | 81.2% |
| YOLOv4 | 2020 | Neural Architecture Search, CSPNet | 140 | 83.5% |
| YOLOv5 | 2020 | PyTorch implementation, EfficientNet backbone | 140 | 84.0% |
| YOLOv8 | 2023 | Advanced architectural optimizations, improved scaling | 200 | 90.0% |
| YOLOv11 | 2025 | Neural Architecture Search, structural re-parameterization | 250 | 92.5% |
Conclusion
The YOLO (You Only Look Once) model has fundamentally transformed the landscape of real-time object detection. Its innovative single-stage approach, combined with continuous advancements across its various versions, has established it as a cornerstone technology in multiple industries. YOLO's unparalleled speed and efficiency make it indispensable for applications requiring immediate object detection and classification, while its evolving architecture ensures ongoing improvements in accuracy and versatility. Despite some limitations, such as challenges with small object detection and densely packed scenes, YOLO's strengths and adaptability continue to drive its widespread adoption and development. As technology progresses, YOLO is poised to further enhance its capabilities, maintaining its position at the forefront of object detection research and application.
References
Last updated February 1, 2025